The Stable channel has been updated to 151.0.7922.47/.48 for Windows and Mac as part of our early stable release to a small percentage of users. A full list of changes in this build is available in the log.
You can find more details about early Stable releases here.
Interested in switching release channels? Find out how here. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
Daniel Yip
Google Chrome
 Have you ever struggled to describe something you’re looking at? Whether it’s a complex manual, a blinking error code, or a unique object, sometimes you just need an exp…
Have you ever struggled to describe something you’re looking at? Whether it’s a complex manual, a blinking error code, or a unique object, sometimes you just need an exp…
 We shared how Samsung users can boost productivity and get time back on new foldables, watches, and glasses coming soon.
We shared how Samsung users can boost productivity and get time back on new foldables, watches, and glasses coming soon.
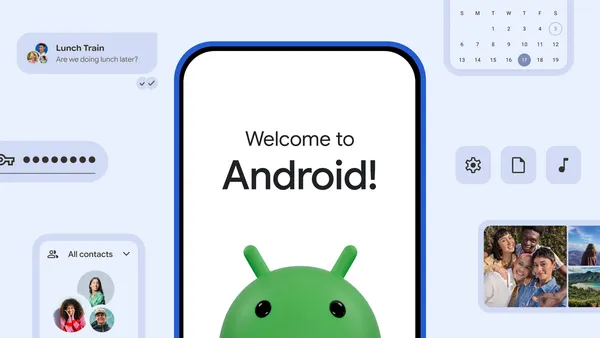 A new migration experience built directly into Android 17 that lets you transfer more data wirelessly from an iPhone.
A new migration experience built directly into Android 17 that lets you transfer more data wirelessly from an iPhone.
 Building on a partnership that began in 2021, Waze is once again teaming up with Halo to celebrate the launch of Halo: Campaign Evolved, with a refreshed Halo experience…
Building on a partnership that began in 2021, Waze is once again teaming up with Halo to celebrate the launch of Halo: Campaign Evolved, with a refreshed Halo experience…