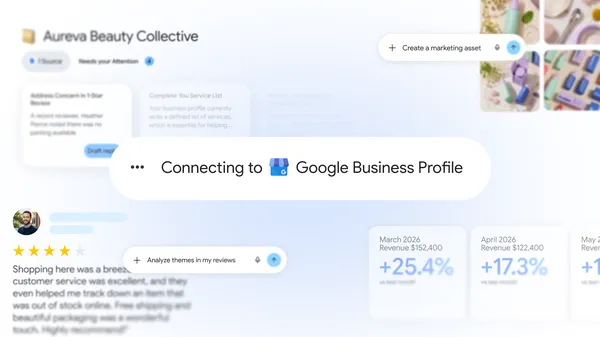
 An overview of new features in the Gemini app designed specifically to support businesses and entrepreneurs.
An overview of new features in the Gemini app designed specifically to support businesses and entrepreneurs.
Save time and grow your business with new Gemini tools
An overview of new features in the Gemini app designed specifically to support businesses and entrepreneurs.
 Google is rolling out many of Chrome's latest AI features in Latin America, Africa, the Middle East and more.
Google is rolling out many of Chrome's latest AI features in Latin America, Africa, the Middle East and more.
 Research with 6,000 UK teens shows AI is vital for learning and creativity. We need "scaffolding" safeguarding and regulation to help children navigate digital risks, wh…
Research with 6,000 UK teens shows AI is vital for learning and creativity. We need "scaffolding" safeguarding and regulation to help children navigate digital risks, wh…
 Young people aren’t just end users of AI; they should be involved in its design and governance. This report highlights how the next generation is prepared to shape the t…
Young people aren’t just end users of AI; they should be involved in its design and governance. This report highlights how the next generation is prepared to shape the t…
 At Google, we believe that understanding and supporting young people as they navigate the digital world is paramount.That’s why we have partnered with Livity to deliver …
At Google, we believe that understanding and supporting young people as they navigate the digital world is paramount.That’s why we have partnered with Livity to deliver …
 Today at our annual Google for Brazil event, we showcased how our most advanced AI products and platforms are helping Brazilians thrive: from Gemini acting as your perso…
Today at our annual Google for Brazil event, we showcased how our most advanced AI products and platforms are helping Brazilians thrive: from Gemini acting as your perso…
 Five ways students can use Google and YouTube AI tools to study effectively and finish the school year strong.
Five ways students can use Google and YouTube AI tools to study effectively and finish the school year strong.
 We’re expanding our coverage and speed — plus, security and connectivity features will work in even more international destinations.
We’re expanding our coverage and speed — plus, security and connectivity features will work in even more international destinations.