
Posted by Simona Milanovic, Developer Relations Engineer
Every year, Google I/O brings new announcements and resources across ecosystems and products, including Android development. As development shifts toward AI and agent-assisted tooling, we’ve expanded our offerings to better support you, however you decide to build for Android.
To help you stay up to date, here is a summary of the top 3 announcements for Android Developer Productivity at I/O.
1. Android CLI is now stable
Android CLI is now stable at version 1.0, with more capabilities and integrations.
The latest version of Android CLI introduces many new features, like programmatic version lookup and support for Journeys, and bridging capability to allow agents to integrate directly with Android Studio, via the studio command.
Running Android Studio alongside the agent and Android CLI enables more efficient navigation in your project, more precise output, and access to Android Studio’s unique tooling, such as performance profilers, Compose Previews, and Android Device Streaming.
Android CLI now integrates seamlessly with Android Studio
Additionally, Google Antigravity now officially supports Android development, with the Android resources bundle, which includes the Android CLI and skills.
You can either install the bundle during onboarding after installation, or later from the Settings > Customizations > Build With Google Plugins menu. This provides Antigravity with all the powerful tools and knowledge of Android CLI to enable it to perform core tasks—from creating projects to deploying your app on a new virtual device—much more easily and efficiently.
Google Antigravity now offers the Android resources bundle
Android CLI is now available through more package managers: like npm and homebrew.
For more information, check out the Android CLI blog post and official documentation.
2. Android skills keep growing
To help models gain expertise for specific development patterns that follow our best practices, we are continuing to expand our repository of Android skills, available through Android CLI and GitHub.
Android skills ground LLMs in specialized workflows and domain knowledge, for the most common and more complex user journeys they might struggle with. We’ve shipped a fresh new batch of skills, with now more than 17 skills for areas such as:
- Adaptive UI
- Display Glasses and Jetpack Compose Glimmer for XR
- Migration to CameraX
- Perfetto SQL and Trace Analysis
- Jetpack Compose Styles API
- AppFunctions
- Verified email retrieval with Android Credential Manager
- Engage SDK integration
- Testing setup
- Wear OS Jetpack Compose Material3
 Android skills keep growing
Android skills keep growing
You can browse skills and install using the Android CLI commands:
android skills list
android skills add –skill=<skill-name>
For more information, check out the official documentation.
3. Android Bench adds new models
Earlier this year, we launched Android Bench - our leaderboard for testing LLMs on real-world Android development challenges and tasks, with the goal of accelerating model improvements, so you have more helpful options for AI assistance.
Latest results from Android Bench leaderboard
You asked us to evaluate open models. So, at I/O, we added more commonly used ones, including our local model Gemma 4, to the leaderboard. We also added the latest models including Gemini 3.5 Flash.
We are also working on increasing the difficulty of challenges we’re giving LLMs, including creating long running tasks, to continue encouraging improvements. These tasks will be coming soon to Android Bench. Checkout the Android Bench leaderboard to see the latest results.
Android development anywhere
By expanding our AI-assisted Android development offerings to Antigravity, through Android CLI and Android skills, and solidifying with the pro capabilities and production grade polish of Android Studio, we’re supporting Android developers wherever they choose to build.
Have fun bringing your ideas to life faster and easier than ever before - we’re excited to see what you build in this new era of agentic development.
 Here’s how three creators are building with Gemma 4, our latest and most advanced family of generative AI open models.
Here’s how three creators are building with Gemma 4, our latest and most advanced family of generative AI open models.
 “See in CMYK:” Explore the science of color with Google Arts & Culture and the Exploratorium.
“See in CMYK:” Explore the science of color with Google Arts & Culture and the Exploratorium.
 The self-described "undercover nerd" used Canvas to build her own app — no coding required.
The self-described "undercover nerd" used Canvas to build her own app — no coding required.
 Learn how researchers are collaborating with Google's Co-Scientist to tackle complex scientific problems.
Learn how researchers are collaborating with Google's Co-Scientist to tackle complex scientific problems.




 Google and American Airlines signed a multi-year sustainable aviation fuel (SAF) agreement.
Google and American Airlines signed a multi-year sustainable aviation fuel (SAF) agreement.
 Google DeepMind Accelerator selects 15 robotics companies from across Europe to join the program. Providing 3 months of intensive mentorship and technical support, enabl…
Google DeepMind Accelerator selects 15 robotics companies from across Europe to join the program. Providing 3 months of intensive mentorship and technical support, enabl…
 Ben Gomes, Google’s Chief Technologist for Learning and Sustainability, held a dialogue for the students of the University of Tokyo.
Ben Gomes, Google’s Chief Technologist for Learning and Sustainability, held a dialogue for the students of the University of Tokyo.
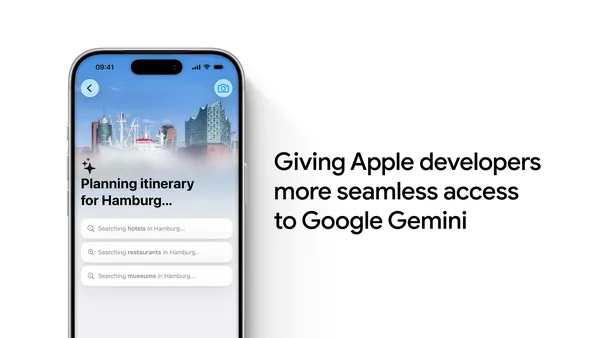 Apple developers can now securely call cloud-hosted Gemini models using the Foundation Models framework, and access Gemini in Xcode.
Apple developers can now securely call cloud-hosted Gemini models using the Foundation Models framework, and access Gemini in Xcode.