Last year we released the Transformer, a new machine learning model that showed remarkable success over existing algorithms for machine translation and other language understanding tasks. Before the Transformer, most neural network based approaches to machine translation relied on recurrent neural networks (RNNs) which operate sequentially (e.g. translating words in a sentence one-after-the-other) using recurrence (i.e. the output of each step feeds into the next). While RNNs are very powerful at modeling sequences, their sequential nature means that they are quite slow to train, as longer sentences need more processing steps, and their recurrent structure also makes them notoriously difficult to train properly.
In contrast to RNN-based approaches, the Transformer used no recurrence, instead processing all words or symbols in the sequence in parallel while making use of a self-attention mechanism to incorporate context from words farther away. By processing all words in parallel and letting each word attend to other words in the sentence over multiple processing steps, the Transformer was much faster to train than recurrent models. Remarkably, it also yielded much better translation results than RNNs. However, on smaller and more structured language understanding tasks, or even simple algorithmic tasks such as copying a string (e.g. to transform an input of “abc” to “abcabc”), the Transformer does not perform very well. In contrast, models that perform well on these tasks, like the Neural GPU and Neural Turing Machine, fail on large-scale language understanding tasks like translation.
In “Universal Transformers” we extend the standard Transformer to be computationally universal (Turing complete) using a novel, efficient flavor of parallel-in-time recurrence which yields stronger results across a wider range of tasks. We built on the parallel structure of the Transformer to retain its fast training speed, but we replaced the Transformer’s fixed stack of different transformation functions with several applications of a single, parallel-in-time recurrent transformation function (i.e. the same learned transformation function is applied to all symbols in parallel over multiple processing steps, where the output of each step feeds into the next). Crucially, where an RNN processes a sequence symbol-by-symbol (left to right), the Universal Transformer processes all symbols at the same time (like the Transformer), but then refines its interpretation of every symbol in parallel over a variable number of recurrent processing steps using self-attention. This parallel-in-time recurrence mechanism is both faster than the serial recurrence used in RNNs, and also makes the Universal Transformer more powerful than the standard feedforward Transformer.
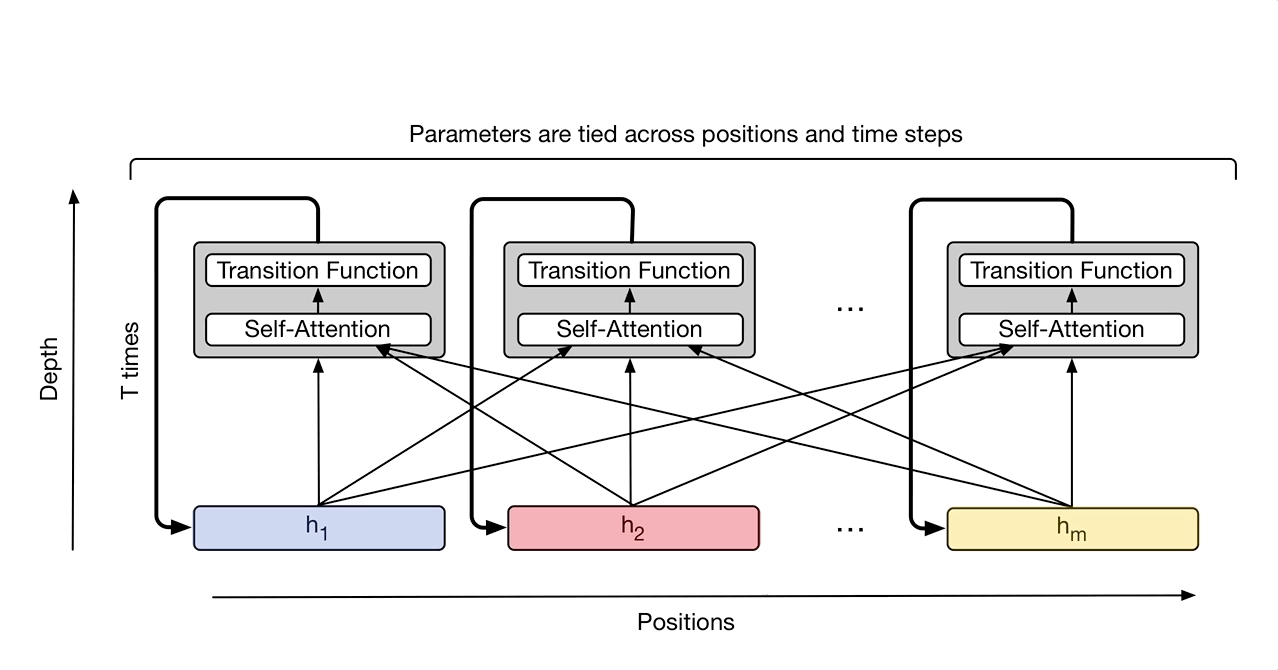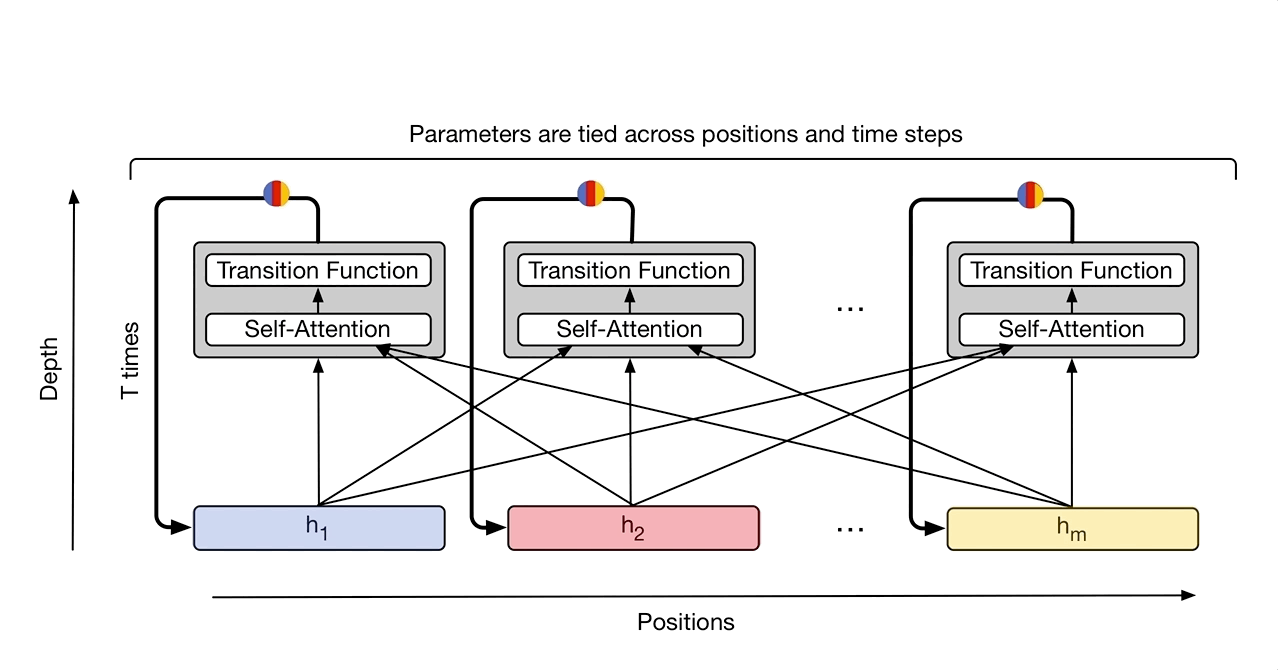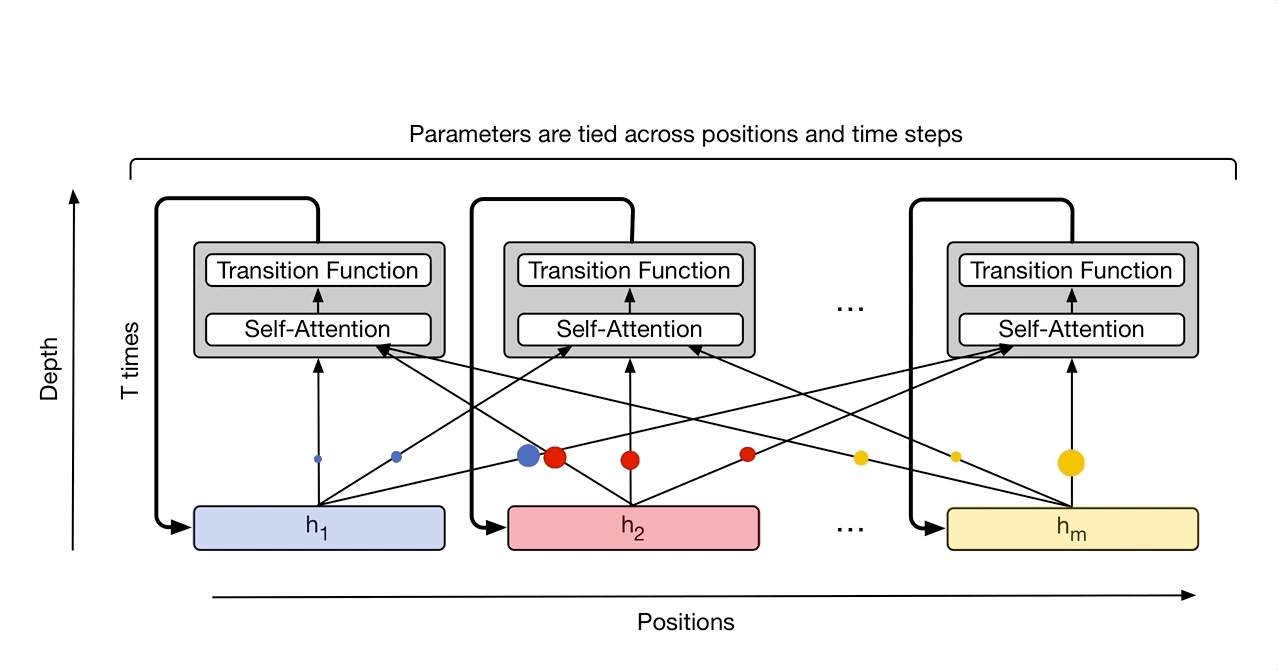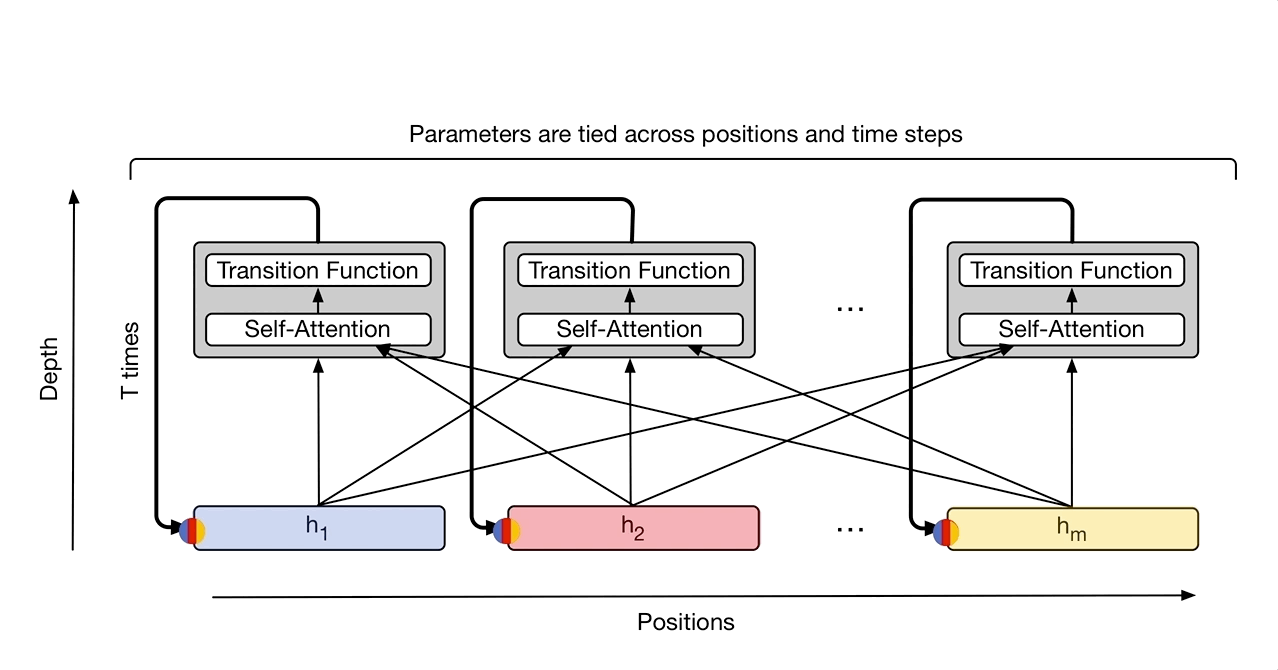 |
| The Universal Transformer repeatedly refines a series of vector representations (shown as h1 to hm) for each position of the sequence in parallel, by combining information from different positions using self-attention and applying a recurrent transition function. Arrows denote dependencies between operations. |
As an intuitive example of how this could be useful, consider the sentence “I arrived at the bank after crossing the river”. In this case, more context is required to infer the most likely meaning of the word “bank” compared to the less ambiguous meaning of “I” or “river”. When we encode this sentence using the standard Transformer, the same amount of computation is applied unconditionally to each word. However, the Universal Transformer’s adaptive mechanism allows the model to spend increased computation only on the more ambiguous words, e.g. to use more steps to integrate the additional contextual information needed to disambiguate the word “bank”, while spending potentially fewer steps on less ambiguous words.
At first it might seem restrictive to allow the Universal Transformer to only apply a single learned function repeatedly to process its input, especially when compared to the standard Transformer which learns to apply a fixed sequence of distinct functions. But learning how to apply a single function repeatedly means the number of applications (processing steps) can now be variable, and this is the crucial difference. Beyond allowing the Universal Transformer to apply more computation to more ambiguous symbols, as explained above, it further allows the model to scale the number of function applications with the overall size of the input (more steps for longer sequences), or to decide dynamically how often to apply the function to any given part of the input based on other characteristics learned during training. This makes the Universal Transformer more powerful in a theoretical sense, as it can effectively learn to apply different transformations to different parts of the input. This is something that the standard Transformer cannot do, as it consists of fixed stacks of learned Transformation blocks applied only once.
But while increased theoretical power is desirable, we also care about empirical performance. Our experiments confirm that Universal Transformers are indeed able to learn from examples how to copy and reverse strings and how to perform integer addition much better than a Transformer or an RNN (although not quite as well as Neural GPUs). Furthermore, on a diverse set of challenging language understanding tasks the Universal Transformer generalizes significantly better and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task. But perhaps of most interest is that the Universal Transformer also improves translation quality by 0.9 BLEU1 over a base Transformer with the same number of parameters, trained in the same way on the same training data. Putting things in perspective, this almost adds another 50% relative improvement on top of the previous 2.0 BLEU improvement that the original Transformer showed over earlier models when it was released last year.
The Universal Transformer thus closes the gap between practical sequence models competitive on large-scale language understanding tasks such as machine translation, and computationally universal models such as the Neural Turing Machine or the Neural GPU, which can be trained using gradient descent to perform arbitrary algorithmic tasks. We are enthusiastic about recent developments on parallel-in-time sequence models, and in addition to adding computational capacity and recurrence in processing depth, we hope that further improvements to the basic Universal Transformer presented here will help us build learning algorithms that are both more powerful, more data efficient, and that generalize beyond the current state-of-the-art.
If you’d like to try this for yourself, the code used to train and evaluate Universal Transformers can be found here in the open-source Tensor2Tensor repository.
Acknowledgements
This research was conducted by Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Additional thanks go to Ashish Vaswani, Douglas Eck, and David Dohan for their fruitful comments and inspiration.
1 A translation quality benchmark widely used in the machine translation community, computed on the standard WMT newstest2014 English to German translation test data set.↩