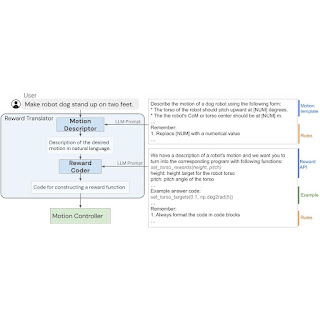
Simple and effective interaction between human and quadrupedal robots paves the way towards creating intelligent and capable helper robots, forging a future where technology enhances our lives in ways beyond our imagination. Key to such human-robot interaction systems is enabling quadrupedal robots to respond to natural language instructions. Recent developments in large language models (LLMs) have demonstrated the potential to perform high-level planning. Yet, it remains a challenge for LLMs to comprehend low-level commands, such as joint angle targets or motor torques, especially for inherently unstable legged robots, necessitating high-frequency control signals. Consequently, most existing work presumes the provision of high-level APIs for LLMs to dictate robot behavior, inherently limiting the system’s expressive capabilities.
In “SayTap: Language to Quadrupedal Locomotion”, we propose an approach that uses foot contact patterns (which refer to the sequence and manner in which a four-legged agent places its feet on the ground while moving) as an interface to bridge human commands in natural language and a locomotion controller that outputs low-level commands. This results in an interactive quadrupedal robot system that allows users to flexibly craft diverse locomotion behaviors (e.g., a user can ask the robot to walk, run, jump or make other movements using simple language). We contribute an LLM prompt design, a reward function, and a method to expose the SayTap controller to the feasible distribution of contact patterns. We demonstrate that SayTap is a controller capable of achieving diverse locomotion patterns that can be transferred to real robot hardware.
SayTap method
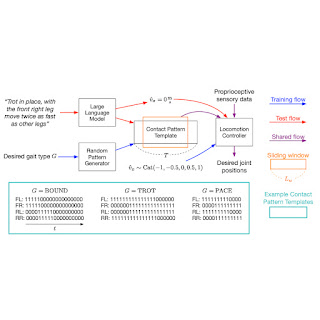
The SayTap approach uses a contact pattern template, which is a 4 X T matrix of 0s and 1s, with 0s representing an agent’s feet in the air and 1s for feet on the ground. From top to bottom, each row in the matrix gives the foot contact patterns of the front left (FL), front right (FR), rear left (RL) and rear right (RR) feet. SayTap’s control frequency is 50 Hz, so each 0 or 1 lasts 0.02 seconds. In this work, a desired foot contact pattern is defined by a cyclic sliding window of size Lw and of shape 4 X Lw. The sliding window extracts from the contact pattern template four foot ground contact flags, which indicate if a foot is on the ground or in the air between t + 1 and t + Lw. The figure below provides an overview of the SayTap method.
SayTap introduces these desired foot contact patterns as a new interface between natural language user commands and the locomotion controller. The locomotion controller is used to complete the main task (e.g., following specified velocities) and to place the robot’s feet on the ground at the specified time, such that the realized foot contact patterns are as close to the desired contact patterns as possible. To achieve this, the locomotion controller takes the desired foot contact pattern at each time step as its input in addition to the robot’s proprioceptive sensory data (e.g., joint positions and velocities) and task-related inputs (e.g., user-specified velocity commands). We use deep reinforcement learning to train the locomotion controller and represent it as a deep neural network. During controller training, a random generator samples the desired foot contact patterns, the policy is then optimized to output low-level robot actions to achieve the desired foot contact pattern. Then at test time a LLM translates user commands into foot contact patterns.
 |
| SayTap approach overview. |
| SayTap uses foot contact patterns (e.g., 0 and 1 sequences for each foot in the inset, where 0s are foot in the air and 1s are foot on the ground) as an interface that bridges natural language user commands and low-level control commands. With a reinforcement learning-based locomotion controller that is trained to realize the desired contact patterns, SayTap allows a quadrupedal robot to take both simple and direct instructions (e.g., “Trot forward slowly.”) as well as vague user commands (e.g., “Good news, we are going to a picnic this weekend!”) and react accordingly. |
We demonstrate that the LLM is capable of accurately mapping user commands into foot contact pattern templates in specified formats when given properly designed prompts, even in cases when the commands are unstructured or vague. In training, we use a random pattern generator to produce contact pattern templates that are of various pattern lengths T, foot-ground contact ratios within a cycle based on a given gait type G, so that the locomotion controller gets to learn on a wide distribution of movements leading to better generalization. See the paper for more details.
Results
With a simple prompt that contains only three in-context examples of commonly seen foot contact patterns, an LLM can translate various human commands accurately into contact patterns and even generalize to those that do not explicitly specify how the robot should react.
SayTap prompts are concise and consist of four components: (1) general instruction that describes the tasks the LLM should accomplish; (2) gait definition that reminds the LLM of basic knowledge about quadrupedal gaits and how they can be related to emotions; (3) output format definition; and (4) examples that give the LLM chances to learn in-context. We also specify five velocities that allow a robot to move forward or backward, fast or slow, or remain still.
General instruction block You are a dog foot contact pattern expert. Your job is to give a velocity and a foot contact pattern based on the input. You will always give the output in the correct format no matter what the input is. Gait definition block The following are description about gaits: 1. Trotting is a gait where two diagonally opposite legs strike the ground at the same time. 2. Pacing is a gait where the two legs on the left/right side of the body strike the ground at the same time. 3. Bounding is a gait where the two front/rear legs strike the ground at the same time. It has a longer suspension phase where all feet are off the ground, for example, for at least 25% of the cycle length. This gait also gives a happy feeling. Output format definition block The following are rules for describing the velocity and foot contact patterns: 1. You should first output the velocity, then the foot contact pattern. 2. There are five velocities to choose from: [-1.0, -0.5, 0.0, 0.5, 1.0]. 3. A pattern has 4 lines, each of which represents the foot contact pattern of a leg. 4. Each line has a label. "FL" is front left leg, "FR" is front right leg, "RL" is rear left leg, and "RR" is rear right leg. 5. In each line, "0" represents foot in the air, "1" represents foot on the ground. Example block Input: Trot slowly Output: 0.5 FL: 11111111111111111000000000 FR: 00000000011111111111111111 RL: 00000000011111111111111111 RR: 11111111111111111000000000 Input: Bound in place Output: 0.0 FL: 11111111111100000000000000 FR: 11111111111100000000000000 RL: 00000011111111111100000000 RR: 00000011111111111100000000 Input: Pace backward fast Output: -1.0 FL: 11111111100001111111110000 FR: 00001111111110000111111111 RL: 11111111100001111111110000 RR: 00001111111110000111111111 Input:
| SayTap prompt to the LLM. Texts in blue are used for illustration and are not input to LLM. |
Following simple and direct commands
We demonstrate in the videos below that the SayTap system can successfully perform tasks where the commands are direct and clear. Although some commands are not covered by the three in-context examples, we are able to guide the LLM to express its internal knowledge from the pre-training phase via the “Gait definition block” (see the second block in our prompt above) in the prompt.
Following unstructured or vague commands
But what is more interesting is SayTap’s ability to process unstructured and vague instructions. With only a little hint in the prompt to connect certain gaits with general impressions of emotions, the robot bounds up and down when hearing exciting messages, like “We are going to a picnic!” Furthermore, it also presents the scenes accurately (e.g., moving quickly with its feet barely touching the ground when told the ground is very hot).
Conclusion and future work
We present SayTap, an interactive system for quadrupedal robots that allows users to flexibly craft diverse locomotion behaviors. SayTap introduces desired foot contact patterns as a new interface between natural language and the low-level controller. This new interface is straightforward and flexible, moreover, it allows a robot to follow both direct instructions and commands that do not explicitly state how the robot should react.
One interesting direction for future work is to test if commands that imply a specific feeling will allow the LLM to output a desired gait. In the gait definition block shown in the results section above, we provide a sentence that connects a happy mood with bounding gaits. We believe that providing more information can augment the LLM’s interpretations (e.g., implied feelings). In our evaluation, the connection between a happy feeling and a bounding gait led the robot to act vividly when following vague human commands. Another interesting direction for future work is to introduce multi-modal inputs, such as videos and audio. Foot contact patterns translated from those signals will, in theory, still work with our pipeline and will unlock many more interesting use cases.
Acknowledgements
Yujin Tang, Wenhao Yu, Jie Tan, Heiga Zen, Aleksandra Faust and Tatsuya Harada conducted this research. This work was conceived and performed while the team was in Google Research and will be continued at Google DeepMind. The authors would like to thank Tingnan Zhang, Linda Luu, Kuang-Huei Lee, Vincent Vanhoucke and Douglas Eck for their valuable discussions and technical support in the experiments.