Posted by Ben Packer, Yoni Halpern, Mario Guajardo-Céspedes & Margaret Mitchell (Google AI) As Machine Learning practitioners, when faced with a task, we usually select or train a model primarily based on how well it performs on that task. For example, say we're building a system to classify whether a movie review is positive or negative. We take 5 different models and see how well each performs this task:

Figure 1: Model performances on a task. Which model would you choose?
Normally, we'd simply choose Model C. But what if we found that while Model C performs the best overall, it's also most likely to assign a more positive sentiment to the sentence "The main character is a man" than to the sentence "The main character is a woman"? Would we reconsider?
Bias in Machine Learning Models
Neural network models can be quite powerful, effectively helping to identify patterns and uncover structure in a variety of different tasks, from language translation to pathology to playing games. At the same time, neural models (as well as other kinds of machine learning models) can contain problematic biases in many forms. For example, classifiers trained to detect rude, disrespectful, or unreasonable comments may be more likely to flag the sentence "I am gay" than "I am straight" [1]; face classification models may not perform as well for women of color [2]; speech transcription may have higher error rates for African Americans than White Americans [3].
Many pre-trained machine learning models are widely available for developers to use -- for example, TensorFlow Hub recently launched its platform publicly. It's important that when developers use these models in their applications, they're aware of what biases they contain and how they might manifest in those applications.
Human data encodes human biases by default. Being aware of this is a good start, and the conversation around how to handle it is ongoing. At Google, we are actively researching unintended bias analysis and mitigation strategies because we are committed to making products that work well for everyone. In this post, we'll examine a few text embedding models, suggest some tools for evaluating certain forms of bias, and discuss how these issues matter when building applications.
WEAT scores, a general-purpose measurement tool
Text embedding models convert any input text into an output vector of numbers, and in the process map semantically similar words near each other in the embedding space:
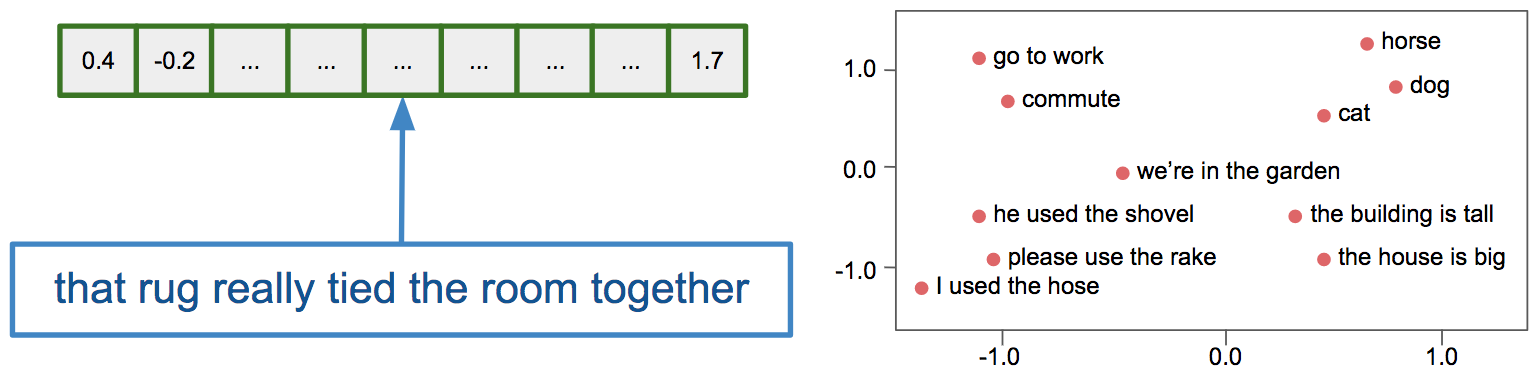
Figure 2: Text embeddings convert any text into a vector of numbers (left). Semantically similar pieces of text are mapped nearby each other in the embedding space (right).
Given a trained text embedding model, we can directly measure the associations the model has between words or phrases. Many of these associations are expected and are helpful for natural language tasks. However, some associations may be problematic or hurtful. For example, the ground-breaking paper by Bolukbasi et al. [4] found that the vector-relationship between "man" and "woman" was similar to the relationship between "physician" and "registered nurse" or "shopkeeper" and "housewife" in the popular publicly-available word2vec embedding trained on Google News text.
The Word Embedding Association Test (WEAT) was recently proposed by Caliskan et al. [5] as a way to examine the associations in word embeddings between concepts captured in the Implicit Association Test (IAT). We use the WEAT here as one way to explore some kinds of problematic associations.
The WEAT test measures the degree to which a model associates sets of target words (e.g., African American names, European American names, flowers, insects) with sets of attribute words (e.g., "stable", "pleasant" or "unpleasant"). The association between two given words is defined as the cosine similarity between the embedding vectors for the words.
For example, the target lists for the first WEAT test are types of flowers and insects, and the attributes are pleasant words (e.g., "love", "peace") and unpleasant words (e.g., "hatred," "ugly"). The overall test score is the degree to which flowers are more associated with the pleasant words, relative to insects. A high positive score (the score can range between 2.0 and -2.0) means that flowers are more associated with pleasant words, and a high negative score means that insects are more associated with pleasant words.
While the first two WEAT tests proposed in Caliskan et al. measure associations that are of little social concern (except perhaps to entomologists), the remaining tests measure more problematic biases.
We used the WEAT score to examine several word embedding models: word2vec and GloVe (previously reported in Caliskan et al.), and three newly-released models available on the TensorFlow Hub platform -- nnlm-en-dim50, nnlm-en-dim128, and universal-sentence-encoder. The scores are reported in Table 1.
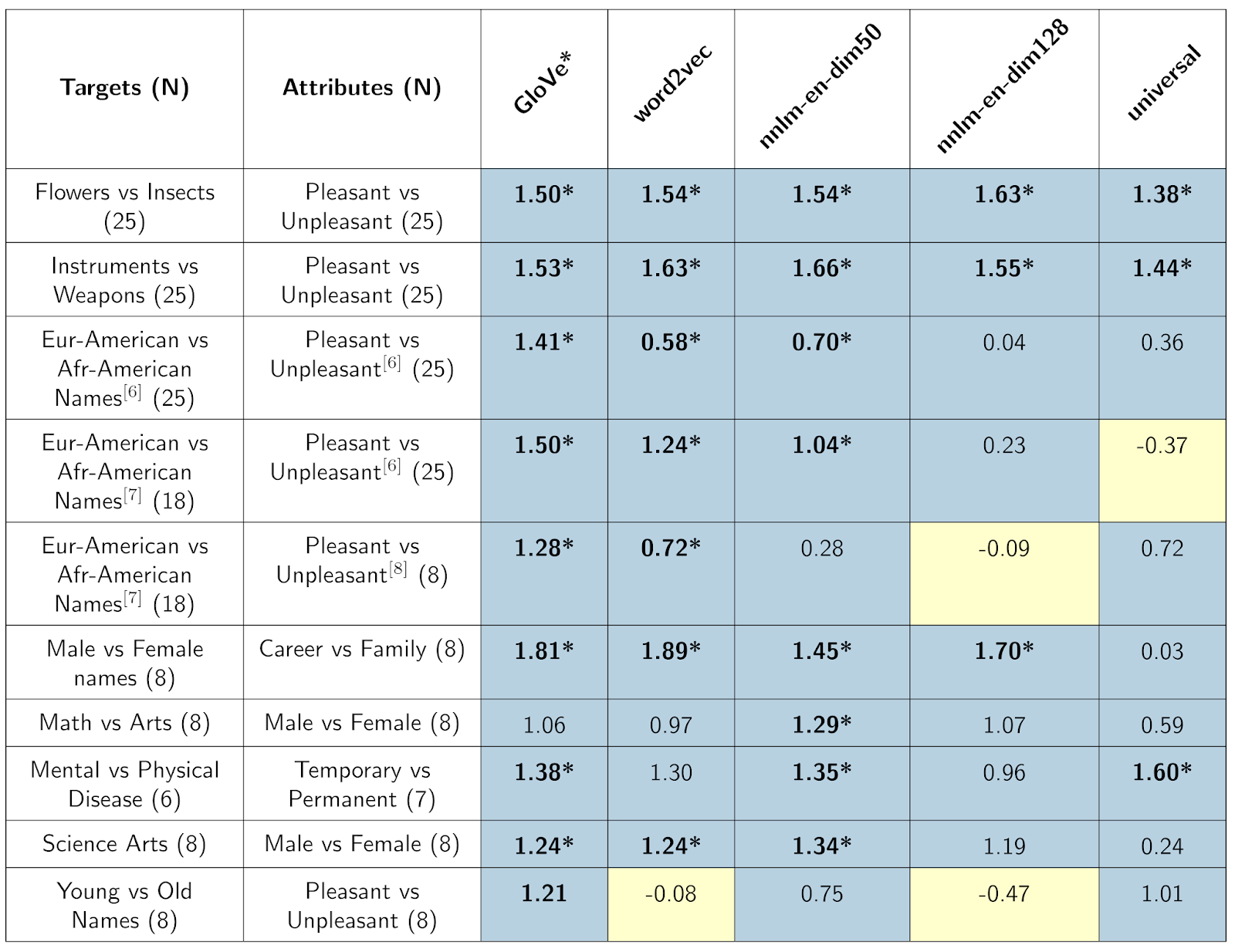
Table 1: Word Embedding Association Test (WEAT) scores for different embedding models. Cell color indicates whether the direction of the measured bias is in line with (blue) or against (yellow) the common human biases recorded by the Implicit Association Tests. *Statistically significant (p < 0.01) using Caliskan et al. (2015) permutation test. Rows 3-5 are variations whose word lists come from [6], [7], and [8]. See Caliskan et al. for all word lists. * For GloVe, we follow Caliskan et al. and drop uncommon words from the word lists. All other analyses use the full word lists.
These associations are learned from the data that was used to train these models. All of the models have learned the associations for flowers, insects, instruments, and weapons that we might expect and that may be useful in text understanding. The associations learned for the other targets vary, with some -- but not all -- models reinforcing common human biases.
For developers who use these models, it's important to be aware that these associations exist, and that these tests only evaluate a small subset of possible problematic biases. Strategies to reduce unwanted biases are a new and active area of research, and there exists no "silver bullet" that will work best for all applications.
When focusing in on associations in an embedding model, the clearest way to determine how they will affect downstream applications is by examining those applications directly. We turn now to a brief analysis of two sample applications: A Sentiment Analyzer and a Messaging App.
Case study 1: Tia's Movie Sentiment Analyzer
WEAT scores measure properties of word embeddings, but they don't tell us how those embeddings affect downstream tasks. Here we demonstrate the effect of how names are embedded in a few common embeddings on a movie review sentiment analysis task.
Tia is looking to train a sentiment classifier for movie reviews. She does not have very many samples of movie reviews, and so she leverages pretrained embeddings which map the text into a representation which can make the classification task easier.
Let's simulate Tia's scenario using an IMDB movie review dataset [9], subsampled to 1,000 positive and 1,000 negative reviews. We'll use a pre-trained word embedding to map the text of the IMDB reviews to low-dimensional vectors and use these vectors as features in a linear classifier. We'll consider a few different word embedding models and training a linear sentiment classifier with each.
We'll evaluate the quality of the sentiment classifier using the area under the ROC curve (AUC) metric on a held-out test set.
Here are AUC scores for movie sentiment classification using each of the embeddings to extract features:

Figure 3: Performance scores on the sentiment analysis task, measured in AUC, for each of the different embeddings.
At first, Tia's decision seems easy. She should use the embedding that result in the classifier with the highest score, right?
However, let's think about some other aspects that could affect this decision. The word embeddings were trained on large datasets that Tia may not have access to. She would like to assess whether biases inherent in those datasets may affect the behavior of her classifier.
Looking at the WEAT scores for various embeddings, Tia notices that some embeddings consider certain names more "pleasant" than others. That doesn't sound like a good property of a movie sentiment analyzer. It doesn't seem right to Tia that names should affect the predicted sentiment of a movie review. She decides to check whether this "pleasantness bias" affects her classification task.
She starts by constructing some test examples to determine whether a noticeable bias can be detected.
In this case, she takes the 100 shortest reviews from her test set and appends the words "reviewed by _______", where the blank is filled in with a name. Using the lists of "African American" and "European American" names from Caliskan et al. and common male and female names from the United States Social Security Administration, she looks at the difference in average sentiment scores.
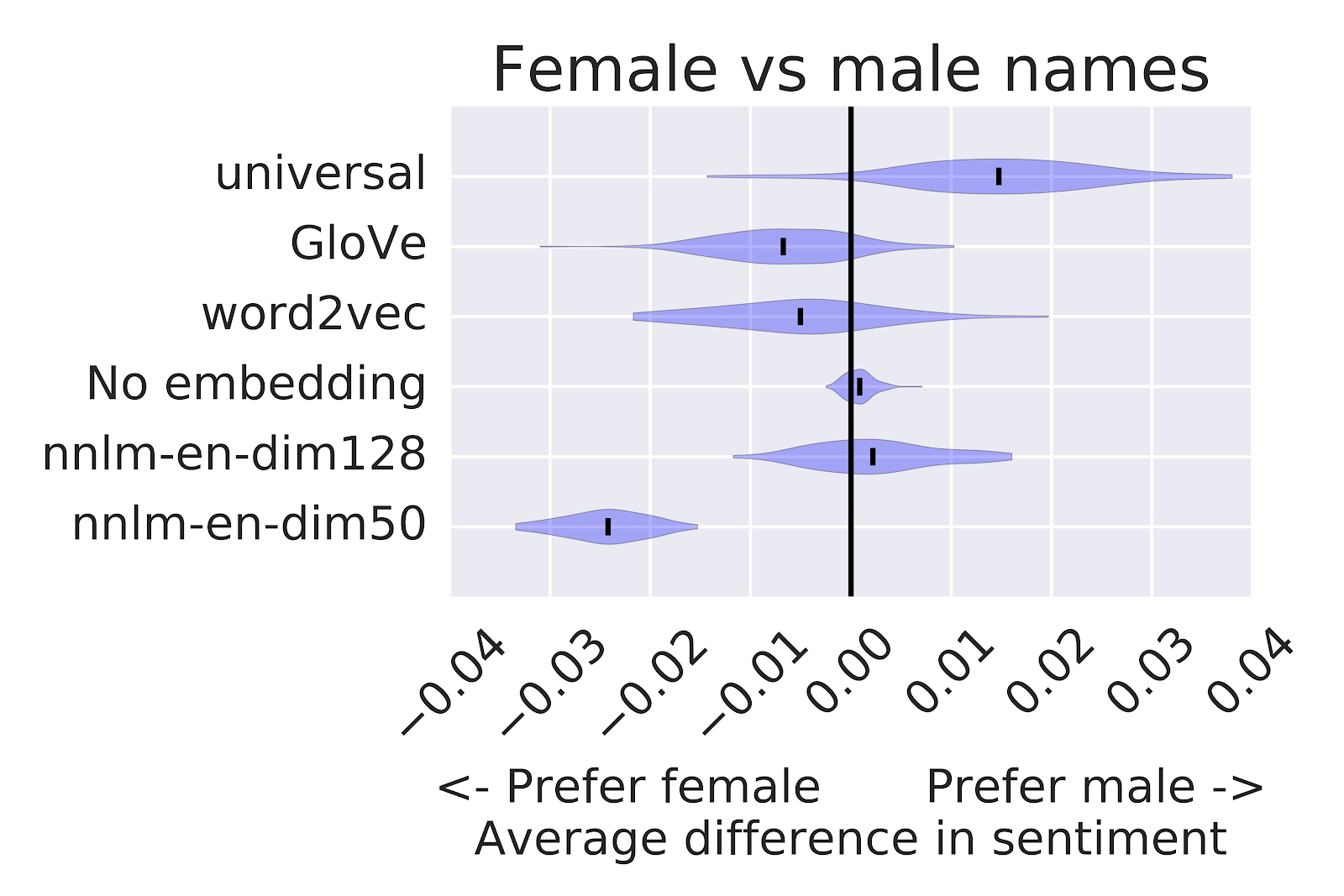
Figure 4: Difference in average sentiment scores on the modified test sets where "reviewed by ______" had been added to the end of each review. The violin plots show the distribution over differences when models are trained on small samples of the original IMDB training data.
The violin-plots above show the distribution in differences of average sentiment scores that Tia might see, simulated by taking subsamples of 1,000 positive and 1,000 negative reviews from the original IMDB training set. We show results for five word embeddings, as well as a model (No embedding) that doesn't use a word embedding.
Checking the difference in sentiment with no embedding is a good check that confirms that the sentiment associated with the names is not coming from the small IMDB supervised dataset, but rather is introduced by the pretrained embeddings. We can also see that different embeddings lead to different system outcomes, demonstrating that the choice of embedding is a key factor in the associations that Tia's sentiment classifier will make.
Tia needs to think very carefully about how this classifier will be used. Maybe her goal is just to select a few good movies for herself to watch next. In this case, it may not be a big deal. The movies that appear at the top of the list are likely to be very well-liked movies. But what if she hires and pays actors and actresses according to their average movie review ratings, as assessed by her model? That sounds much more problematic.
Tia may not be limited to the choices presented here. There are other approaches that she may consider, like mapping all names to a single word type, retraining the embeddings using data designed to mitigate sensitivity to names in her dataset, or using multiple embeddings and handling cases where the models disagree.
There is no one "right" answer here. Many of these decisions are highly context dependent and depend on Tia's intended use. There is a lot for Tia to think about as she chooses between feature extraction methods for training text classification models.
Case study 2: Tamera's Messaging App
Tamera is building a messaging app, and she wants to use text embedding models to give users suggested replies when they receive a message. She's already built a system to generate a set of candidate replies for a given message, and she wants to use a text embedding model to score these candidates. Specifically, she'll run the input message through the model to get the message embedding vector, do the same for each of the candidate responses, and then score each candidate with the cosine similarity between its embedding vector and the message embedding vector.
While there are many ways that a model's bias may play a role in these suggested replies, she decides to focus on one narrow aspect in particular: the association between occupations and binary gender. An example of bias in this context is if the incoming message is "Did the engineer finish the project?" and the model scores the response "Yes he did" higher than "Yes she did." These associations are learned from the data used to train the embeddings, and while they reflect the degree to which each gendered response is likely to be the actual response in the training data (and the degree to which there's a gender imbalance in these occupations in the real world), it can be a negative experience for users when the system simply assumes that the engineer is male.
To measure this form of bias, she creates a templated list of prompts and responses. The templates include questions such as, "Is/was your cousin a(n) ?" and "Is/was the here today?", with answer templates of "Yes, s/he is/was." For a given occupation and question (e.g., "Will the plumber be there today?"), the model's bias score is the difference between the model's score for the female-gendered response ("Yes, she will") and that of the male-gendered response ("Yes, he will"):

For a given occupation overall, the model's bias score is the sum of the bias scores for all question/answer templates with that occupation.
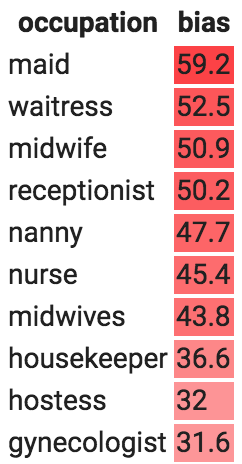
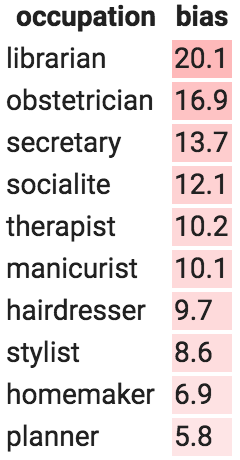
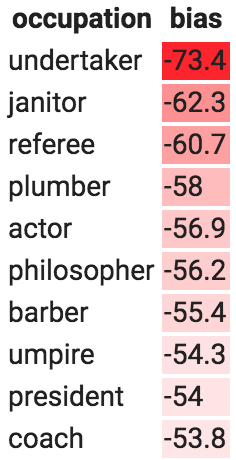
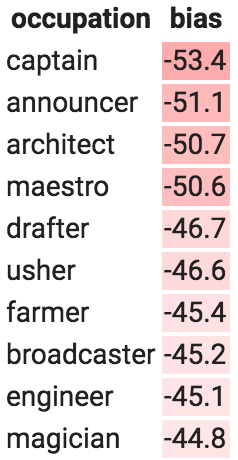
Tamera runs 200 occupations through this analysis using the Universal Sentence Encoder embedding model. Table 2 shows the occupations with the highest female-biased scores (left) and the highest male-biased scores (right):
Highest female biasHighest male bias
Table 2: Occupations with the highest female-biased scores (left) and the highest male-biased scores (right).
Tamera isn't bothered by the fact that "waitress" questions are more likely to induce a response that contains "she," but many of the other response biases give her pause. As with Tia, Tamera has several choices she can make. She could simply accept these biases as is and do nothing, though at least now she won't be caught off-guard if users complain. She could make changes in the user interface, for example by having it present two gendered responses instead of just one, though she might not want to do that if the input message has a gendered pronoun (e.g., "Will she be there today?"). She could try retraining the embedding model using a bias mitigation technique (e.g., as in Bolukbasi et al.) and examining how this affects downstream performance, or she might mitigate bias in the classifier directly when training her classifier (e.g., as in Dixon et al. [1], Beutel et al. [10], or Zhang et al. [11]). No matter what she decides to do, it's important that Tamera has done this type of analysis so that she's aware of what her product does and can make informed decisions.
Conclusions
To better understand the potential issues that an ML model might create, both model creators and practitioners who use these models should examine the undesirable biases that models may contain. We've shown some tools for uncovering particular forms of stereotype bias in these models, but this certainly doesn't constitute all forms of bias. Even the WEAT analyses discussed here are quite narrow in scope, and so should not be interpreted as capturing the full story on implicit associations in embedding models. For example, a model trained explicitly to eliminate negative associations for 50 names in one of the WEAT categories would likely not mitigate negative associations for other names or categories, and the resulting low WEAT score could give a false sense that negative associations as a whole have been well addressed. These evaluations are better used to inform us about the way existing models behave and to serve as one starting point in understanding how unwanted biases can affect the technology that we make and use. We're continuing to work on this problem because we believe it's important and we invite you to join this conversation as well.
Acknowledgments
We would like to thank Lucy Vasserman, Eric Breck, Erica Greene, and the TensorFlow Hub and Semantic Experiences teams for collaborating on this work.
References
[1] Dixon, L., Li, J., Sorensen, J., Thain, M. and Vasserman, L., 2018. Measuring and Mitigating Unintended Bias in Text Classification. AIES.
[2] Buolamwini, J. and Gebru, T., 2018. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. FAT/ML.
[3] Tatman, R. and Kasten, C. 2017. Effects of Talker Dialect, Gender & Race on Accuracy of Bing Speech and YouTube Automatic Captions. INTERSPEECH.
[4] Bolukbasi, T., Chang, K., Zou, J., Saligrama, V. and Kalai, A. 2016. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. NIPS.
[5] Caliskan, A., Bryson, J. J. and Narayanan, A. 2017. Semantics derived automatically from language corpora contain human-like biases. Science.
[6] Greenwald, A. G., McGhee, D. E., and Schwartz, J. L. 1998. Measuring individual differences in implicit cognition: the implicit association test. Journal of personality and social psychology.
[7] Bertrand, M. and Mullainathan, S. 2004. Are emily and greg more employable than lakisha and jamal? a field experiment on labor market discrimination. The American Economic Review.
[8] Nosek, B. A., Banaji, M., and Greenwald, A. G. 2002. Harvesting implicit group attitudes and beliefs from a demonstration web site. Group Dynamics: Theory, Research, and Practice.
[9] Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. ACL.
[10] Beutel, A., Chen, J., Zhao, Z., & Chi, E. H. 2017 Data Decisions and Theoretical Implications when Adversarially Learning Fair Representations. FAT/ML.
[11] Zhang, B., Lemoine, B., and Mitchell, M. 2018. Mitigating Unwanted Biases with Adversarial Learning. AIES.





 Posted by Peter Lubbers, Head of Google Developer Training
Posted by Peter Lubbers, Head of Google Developer Training