Posted by the Flutter team
The Flutter team is coming to you live this week from Mobile World Congress in Barcelona, the largest annual gathering of the mobile technology industry. One year ago, we announced the first beta of Flutter at this same event, and since then Flutter has grown faster than we could have imagined. So it seems fitting that we celebrate this anniversary occasion with our first stable update release for Flutter.
Flutter 1.2
Flutter 1.2 is the first feature update for Flutter. We've focused this release on a few major areas:
- Improved stability, performance and quality of the core framework.
- Work to polish visual finish and functionality of existing widgets.
- New web-based tooling for developers building Flutter applications.
Having shipped Flutter 1.0, we focused a good deal of energy in the last couple of months on improving our testing and code infrastructure, clearing a backlog of pull requests, and improving performance and quality of the overall framework. We have a comprehensive list of these requests in the Flutter wiki for those who are interested in the specifics. This work also included broader support for new UI languages such as Swahili.
We continue to make improvements to both the Material and Cupertino widget sets, to support more flexible usage of Material and continue to strive towards pixel-perfect fidelity on iOS. The latter work includes support for floating cursor text editing, as well as showing continued attention to minor details (for example, we updated the way the text editing cursor paints on iOS for a faithful representation of the animation and painting order). We added support for a broader set of animation easing functions, inspired by the work of Robert Penner. And we added support for new keyboard events and mouse hover support, in preparation for deeper support for desktop-class operating systems.
The plug-in team has also been busy in Flutter 1.2, with work well underway to support in-app purchases, as well as many bug fixes for video player, webview, and maps. And thanks to a pull request contributed by a developer from Intuit, we now have support for Android App Bundles, a new packaging format that helps in reducing app size and enables new features like dynamic delivery for Android apps.
Lastly, Flutter 1.2 includes the Dart 2.2 SDK, an update that brings significant performance improvements to compiled code along with new language support for initializing sets. For more information on this work, you can read the Dart 2.2 announcement.
(As an aside, some might wonder why this release is numbered 1.2. Our goal is to ship a 1.x release to the 'beta' channel on about a monthly basis, and to release an update approximately every quarter to the 'stable' channel that is ready for production usage. Our 1.1 last month was a beta release, and so 1.2 is therefore our first stable release.)
New Tools for Flutter Developers
Mobile developers come from a variety of backgrounds and often prefer different programming tools and editors. Flutter itself supports different tools, including first-class support for Android Studio and Visual Studio Code as well as support for building apps from the command line, so we knew we needed flexibility in how we expose debugging and runtime inspection tools.
Alongside Flutter 1.2, we're delighted to preview a new web-based suite of programming tools to help Flutter developers debug and analyze their apps. These tools are now available for installation alongside the extensions and add-ins for Visual Studio Code and Android Studio, and offer a number of capabilities:
- A widget inspector, which enables visualization and exploration of the tree hierarchy that Flutter uses for rendering.
- A timeline view that helps you diagnose your application at a frame-by-frame level, identifying rendering and computational work that may cause animation 'jank' in your apps.
- A full source-level debugger that lets you step through code, set breakpoints and investigate the call stack.
- A logging view that shows activity you log from your application as well as network, framework and garbage collection events.
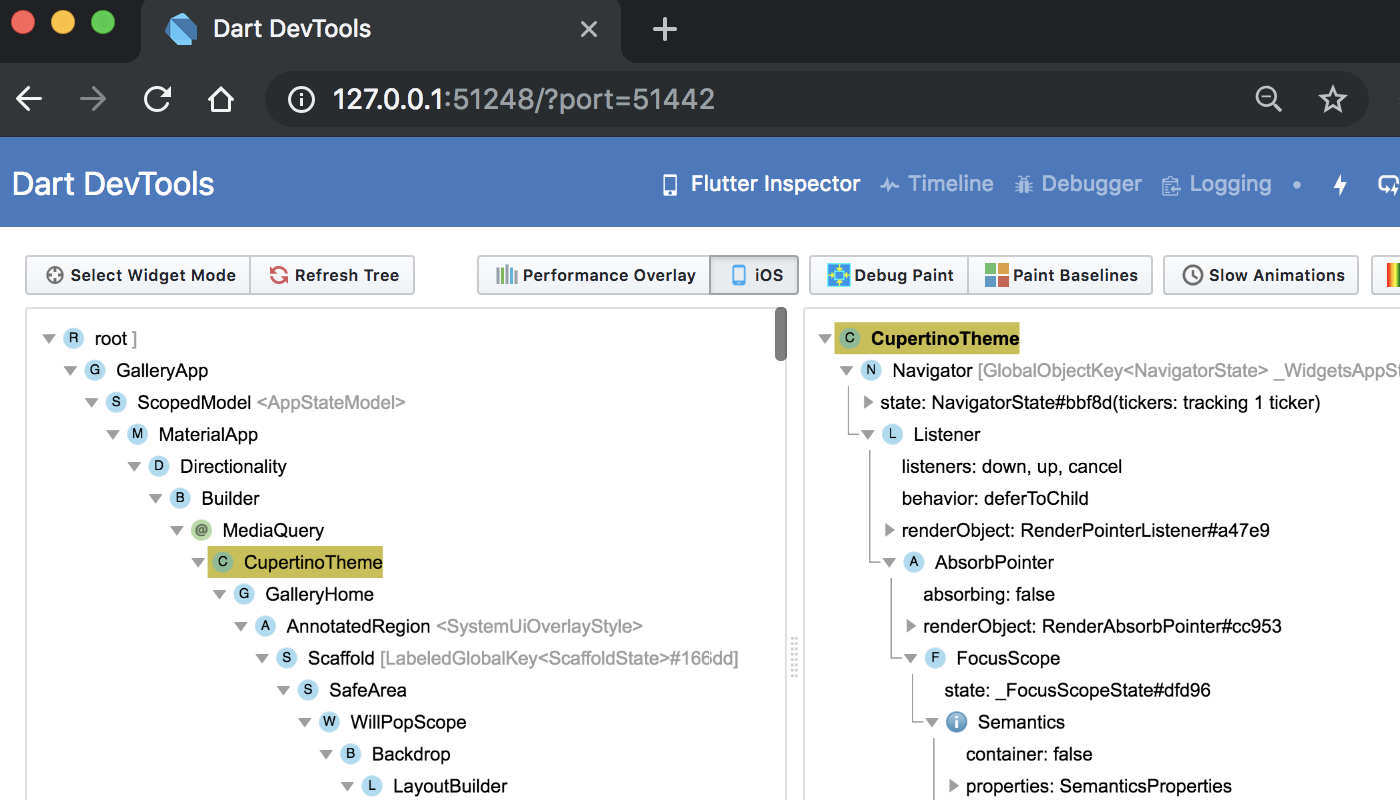
We plan to invest further in this new web-based tooling for both Flutter and Dart developers and, as integration for web-based experiences improves, we plan to build these services directly into tools like Visual Studio Code.
What's next for Flutter?
In addition to the engineering work, we took some time after Flutter 1.0 to document our 2019 roadmap, and you'll see that we've got plenty of work ahead of us.
A big focus for 2019 is growing Flutter beyond mobile platforms. At Flutter Live, we announced a project codenamed "Hummingbird", which brings Flutter to the web, and we plan to share a technical preview in the coming months. In addition, we continue to work on bringing Flutter to desktop-class devices; this requires work both at the framework level as described above, as well as the ability to package and deploy applications for operating systems like Windows and Mac, in which we're investing through our Flutter Desktop Embedding project.
Flutter Create: what can you do with 5K of Dart?
This week, we're also excited to launch Flutter Create, a contest that challenges you to build something interesting, inspiring, and beautiful with Flutter using five kilobytes or less of Dart code. 5K isn't a lot -- for a typical MP3 file, it's about a third of a second of music -- but we're betting you can amaze us with what you can achieve in Flutter with such a small amount of code.

The contest runs until April 7th, so you've got a few weeks to build something cool. We have some great prizes, including a fully-loaded iMac Pro developer workstation with a 14-core processor and 128GB of memory that is worth over $10,000! We'll be announcing the winners at Google I/O, where we'll have a number of Flutter talks, codelabs and activities.
In closing
Flutter is now one of the top 20 software repos on Github, and the worldwide community grows with every passing month. Between meetups in Chennai, India, articles from Port Harcourt, Nigeria, apps from Copenhagen, Denmark and incubation studios in New York City, USA, it's clear that Flutter continues to become a worldwide phenomenon, thanks to you. You can see Flutter in apps that have hundreds of millions of users, and in apps from entrepreneurs who are bringing their first idea to market. It's exciting to see the range of ideas you have, and we hope that we can help you express them with Flutter.

Attendees of a Flutter deep dive at Technozzare, SRM University.
Finally, we've recently launched a YouTube channel exclusively dedicated to Flutter. Be sure to subscribe at flutter.dev/youtube for shows including the Boring Flutter Development Show, Widget of the Week, and Flutter in Focus. You'll also find a new case study from Dream11, a popular Indian fantasy sports site, as well as other Developer Stories. See you there!