Posted by Billy Rutledge, Director of AIY Projects
Over the past year and a half, we've seen more than 200K people build, modify, and create with our Voice Kit and Vision Kit products. Today at Cloud Next we announced two new devices to help professional engineers build new products with on-device machine learning(ML) at their core: the AIY Edge TPU Dev Board and the AIY Edge TPU Accelerator. Both are powered by Google's Edge TPU and represent our first steps towards expanding AIY into a platform for experimentation with on-device ML.
The Edge TPU is Google's purpose-built ASIC chip designed to run TensorFlow Lite ML models on your device. We've learned that performance-per-watt and performance-per-dollar are critical benchmarks when processing neural networks within a small footprint. The Edge TPU delivers both in a package that's smaller than the head of a penny. It can accelerate ML inferencing on device, or can pair with Google Cloud to create a full cloud-to-edge ML stack. In either configuration, by processing data directly on-device, a local ML accelerator increases privacy, removes the need for persistent connections, reduces latency, and allows for high performance using less power.
The AIY Edge TPU Dev Board is an all-in-one development board that allows you to prototype embedded systems that demand fast ML inferencing. The baseboard provides all the peripheral connections you need to effectively prototype your device — including a 40-pin GPIO header to integrate with various electrical components. The board also features a removable System-on-module (SOM) daughter board can be directly integrated into your own hardware once you're ready to scale.
The AIY Edge TPU Accelerator is a neural network coprocessor for your existing system. This small USB-C stick can connect to any Linux-based system to perform accelerated ML inferencing. The casing includes mounting holes for attachment to host boards such as a Raspberry Pi Zero or your custom device.
On-device ML is still in its early days, and we're excited to see how these two products can be applied to solve real world problems — such as increasing manufacturing equipment reliability, detecting quality control issues in products, tracking retail foot-traffic, building adaptive automotive sensing systems, and more applications that haven't been imagined yet.
Both devices will be available online this fall in the US with other countries to follow shortly.
A novel SSD-based architecture called the Pooling Pyramid Network (PPN) whose model size is >3x smaller than that of SSD MobileNet v1 with minimal loss in accuracy.
Additionally, we are releasing pre-trained weights for each of the above models based on the COCO dataset.
Accelerated Training via Cloud TPUs Users spend a great deal of time on optimizing hyperparameters and retraining object detection models, therefore having fast turnaround times on experiments is critical. The models released today belong to the single shot detector (SSD) class of architectures that are optimized for training on Cloud TPUs. For example, we can now train a ResNet-50 based RetinaNet model to achieve 35% mean Average Precision (mAP) on the COCO dataset in < 3.5 hrs.
Accelerated Inference via Quantization and TensorFlow Lite To better support low-latency requirements on mobile and embedded devices, the models we are providing are now natively compatible with TensorFlow Lite, which enables on-device machine learning inference with low latency and a small binary size. As part of this, we have implemented: (1) model quantization and (2) detection-specific operations natively in TensorFlow Lite. Our model quantization follows the strategy outlined in Jacob et al. (2018) and the whitepaper by Krishnamoorthi (2018) which applies quantization to both model weights and activations at training and inference time, yielding smaller models that run faster.
Quantized detection models are faster and smaller (e.g., a quantized 75% depth-reduced SSD Mobilenet model runs at >15 fps on a Pixel 2 CPU with a 4.2 Mb footprint) with minimal loss in detection accuracy compared to the full floating point model.
Try it Yourself with a New Tutorial! To get started training your own model on Cloud TPUs, check out our new tutorial! This walkthrough will take you through the process of training a quantized pet face detector on Cloud TPU then exporting it to an Android phone for inference via TensorFlow Lite conversion.
We hope that these new additions will help make high-quality computer vision models accessible to anyone wishing to solve an object detection problem, and provide a more seamless user experience, from training a model with quantization to exporting to a TensorFlow Lite model ready for on-device deployment. We would like to thank everyone in the community who have contributed features and bug fixes. As always, contributions to the codebase are welcome, and please stay tuned for more updates!
Acknowledgements This post reflects the work of the following group of core contributors: Derek Chow, Aakanksha Chowdhery, Jonathan Huang, Pengchong Jin, Zhichao Lu, Vivek Rathod, Ronny Votel and Xiangxin Zhu. We would also like to thank the following colleagues: Vasu Agrawal, Sourabh Bajaj, Chiachen Chou, Tom Jablin, Wenzhe Li, Tsung-Yi Lin, Hernan Moraldo, Kevin Murphy, Sara Robinson, Andrew Selle, Shashi Shekhar, Yash Sonthalia, Zak Stone, Pete Warden and Menglong Zhu.
Next week a veritable who’s who of free and open source software luminaries, maintainers and developers will gather to celebrate the 20th annual OSCON and the 20th anniversary of the Open Source Definition. Naturally, the Google Open Source and Google Cloud teams will be there too!
Program chairs at OSCON 2017, left to right: Rachel Roumeliotis, Kelsey Hightower, Scott Hanselman. Photo used with permission from O'Reilly Media.
This year OSCON returns to Portland, Oregon and runs from July 16-19. As usual, it is preceded by the free-to-attend Community Leadership Summit on July 14-15.
Looking for an inroad into the world of Artificial Intelligence and Machine Learning? Now you can access practical -- and free -- training from Google experts
From helping farmers detect the onset of crop infections to enabling doctors diagnose the occurrence of diabetic blindness among millions, Artificial Intelligence is helping tackle challenges inventively across a range of sectors. At Google, we believe that AI has the potential to make apps and services more useful, while helping innovation among businesses and developers, be it in their own field or while taking on humanity’s big challenges.
In India the AI ecosystem is nascent but is developing rapidly. With companies of all sizes adopting AI in their solutions, there is a clear and present need for trained and technically-equipped developers to drive these AI-related challenges and projects. To help facilitate this, Google signed a Statement of Intent with NITI Aayog earlier this year to jointly work towards building the AI ecosystem in India.
One of the key initiatives of this collaboration is to train Indian developers in the field of Machine Learning. With this as the objective we are excited to bring the Machine Learning Crash Course (MLCC) Study Jam series to India this July.
This course intends to improve developers’ technical proficiency in machine learning, enabling them to apply cutting-edge techniques to help take on a range of practical challenges.
About MLCC
MLCC is Google’s flagship machine learning course, initially created for Google engineers. This course was taken up by more than 18,000 Googlers, and was recently made publicly available. MLCC provides exercises, interactive visualizations, and instructional videos that anyone can use to learn and practice ML concepts.
What does the course cover?
MLCC covers numerous machine learning fundamentals, from basic concepts such as loss function and gradient descent, then building through more advanced theories like classification models and neural networks. The programming exercises include the basics of TensorFlow -- our open-source machine learning framework -- and also feature succinct videos from Google machine learning experts. Participants will be able to read short text lessons, and play with educational gadgets devised by Google’s instructional designers and engineers.
Who should take this (free!) course?
MLCC is intended for those who wish to learn about ML from a practical, applied perspective that will enable them to gain a deeper understanding of the power of TensorFlow, and incorporate best practices into their everyday projects. This course is ideally suited to developers with basic machine learning knowledge, who are keen to gain experience in ML and TensorFlow.
Posted by Nicola Pezzotti, Software Engineering Intern, Google Zürich
In recent years, the t-distributed Stochastic Neighbor Embedding (tSNE) algorithm has become one of the most used and insightful techniques for exploratory data analysis of high-dimensional data. Used to interpret deep neural network outputs in tools such as the TensorFlow Embedding Projector and TensorBoard, a powerful feature of tSNE is that it reveals clusters of high-dimensional data points at different scales while requiring only minimal tuning of its parameters. Despite these advantages, the computational complexity of the tSNE algorithm limits its application to relatively small datasets. While several evolutions of tSNE have been developed to address this issue (mainly focusing on the scalability of the similarity computations between data points), they have so far not been enough to provide a truly interactive experience when visualizing the evolution of the tSNE embedding for large datasets.
In “Linear tSNE Optimization for the Web”, we present a novel approach to tSNE that heavily relies on modern graphics hardware. Given the linear complexity of the new approach, our method generates embeddings faster than comparable techniques and can even be executed on the client side in a web browser by leveraging GPU capabilities through WebGL. The combination of these two factors allows for real-time interactive visualization of large, high-dimensional datasets. Furthermore, we are releasing this work as an open source library in the TensorFlow.js family in the hopes that the broader research community finds it useful.
Real-time evolution of the tSNE embedding for the complete MNIST dataset with our technique. The dataset contains images of 60,000 handwritten digits. You can find a live demo here.
The aim of tSNE is to cluster small “neighborhoods” of similar data points while also reducing the overall dimensionality of the data so it is more easily visualized. In other words, the tSNE objective function measures how well these neighborhoods of similar data are preserved in the 2 or 3-dimensional space, and arranges them into clusters accordingly.
In previous work, the minimization of the tSNE objective was performed as a N-body simulation problem, in which points are randomly placed in the embedding space and two different types of forces are applied on each point. Attractive forces bring the points closer to the points that are most similar in the high-dimensional space, while repulsive forces push them away from all the neighbors in the embedding.
While the attractive forces are acting on a small subset of points (i.e., similar neighbors), repulsive forces are in effect from all pairs of points. Due to this, tSNE requires significant computation and many iterations of the objective function, which limits the possible dataset size to just a few hundred data points. To improve over a brute force solution, the Barnes-Hut algorithm was used to approximate the repulsive forces and the gradient of the objective function. This allows scaling of the computation to tens of thousand data points, but it requires more than 15 minutes to compute the MNIST embedding in a C++ implementation.
In our paper, we propose a solution to this scaling problem by approximating the gradient of the objective function using textures that are generated in WebGL. Our technique draws a “repulsive field” at every minimization iteration using a three channel texture, with the 3 components treated as colors and drawn in the RGB channels. The repulsive field is obtained for every point to represent both the horizontal and vertical repulsive force created by the point, and a third component used for normalization. Intuitively, the normalization term ensures that the magnitude of the shifts matches the similarity measure in the high-dimensional space. In addition, the resolution of the texture is adaptively changed to keep the number of pixels drawn constant.
Rendering of the three functions used to approximate the repulsive effect created by a single point. In the above figure the repulsive forces show a point in a blue area is pushed to the left/bottom, while a point in the red area is pushed to the right/top while a point in the white region will not move.
The contribution of every point is then added on the GPU, resulting in a texture similar to those presented in the GIF below, that approximate the repulsive fields. This innovative repulsive field approach turns out to be much more GPU friendly than more commonly used calculation of point-to-point interactions. This is because repulsion for multiple points can be computed at once and in a very fast way in the GPU. In addition, we implemented the computation of the attraction between points in the GPU.
This animation shows the evolution of the tSNE embedding (upper left) and of the scalar fields used to approximate its gradient with normalization term (upper right), horizontal shift (bottom left) and vertical shift (bottom right).
We additionally revised the update of the embedding from an ad-hoc implementation to a series of standard tensor operations that are computed in TensorFlow.js, a JavaScript library to perform tensor computations in the web browser. Our approach, which is released as an open source library in the TensorFlow.js family, allows us to compute the evolution of the tSNE embedding entirely on the GPU while having better computational complexity.
With this implementation, what used to take 15 minutes to calculate (on the MNIST dataset) can now be visualized in real-time and in the web browser. Furthermore this allows real-time visualizations of much larger datasets, a feature that is particularly useful when deep neural output is analyzed. One main limitation of our work is that this technique currently only works for 2D embeddings. However, 2D visualizations are often preferred over 3D ones as they require more interaction to effectively understand cluster results.
Future Work We believe that having a fast and interactive tSNE implementation that runs in the browser will empower developers of data analytics systems. We are particularly interested in exploring how our implementation can be used for the interpretation of deep neural networks. Additionally, our implementation shows how lateral thinking in using GPU computations (approximating the gradient using RGB texture) can be used to significantly speed up algorithmic computations. In the future we will be exploring how this kind of gradient approximation can be applied not only to speed-up other dimensionality reduction algorithms, but also to implement other N-body simulations in the web browser using TensorFlow.js.
Acknowledgements We would like to thank Alexander Mordvintsev, Yannick Assogba, Matt Sharifi, Anna Vilanova, Elmar Eisemann, Nikhil Thorat, Daniel Smilkov, Martin Wattenberg, Fernanda Viegas, Alessio Bazzica, Boudewijn Lelieveldt, Thomas Höllt, Baldur van Lew, Julian Thijssen and Marvin Ritter.
Posted by Bo Chen, Software Engineer and Jeffrey M. Gilbert, Member of Technical Staff, Google Research
Over the past year, there have been exciting innovations in the design of deep networks for vision applications on mobile devices, such as the MobileNet model family and integer quantization. Many of these innovations have been driven by performance metrics that focus on meaningful user experiences in real-world mobile applications, requiring inference to be both low-latency and accurate. While the accuracy of a deep network model can be conveniently estimated with well established benchmarks in the computer vision community, latency is surprisingly difficult to measure and no uniform metric has been established. This lack of measurement platforms and uniform metrics have hampered the development of performant mobile applications.
Today, we are happy to announce the On-device Visual Intelligence Challenge (OVIC), part of the Low-Power Image Recognition Challenge Workshop at the 2018 Computer Vision and Pattern Recognition conference (CVPR2018). A collaboration with Purdue University, the University of North Carolina and IEEE, OVIC is a public competition for real-time image classification that uses state-of-the-art Google technology to significantly lower the barrier to entry for mobile development. OVIC provides two key features to catalyze innovation: a unified latency metric and an evaluation platform.
A Unified Metric OVIC focuses on the establishment of a unified metric aligned directly with accurate and performant operation on mobile devices. The metric is defined as the number of correct classifications within a specified per-image average time limit of 33ms. This latency limit allows every frame in a live 30 frames-per-second video to be processed, thus providing a seamless user experience1. Prior to OVIC, it was tricky to enforce such a limit due to the difficulty in accurately and uniformly measuring latency as would be experienced in real-world applications on real-world devices. Without a repeatable mobile development platform, researchers have relied primarily on approximate metrics for latency that are convenient to compute, such as the number of multiply-accumulate operations (MACs). The intuition is that multiply-accumulate constitutes the most time-consuming operation in a deep neural network, so their count should be indicative of the overall latency. However, these metrics are often poor predictors of on-device latency due to many aspects of the models that can impact the average latency of each MAC in typical implementations.
Even though the number of multiply-accumulate operations (# MACs) is the most commonly used metric to approximate on-device latency, it is a poor predictor of latency. Using data from various quantized and floating point MobileNet V1 and V2 based models, this graph plots on-device latency on a common reference device versus the number of MACs. It is clear that models with similar latency can have very different MACs, and vice versa.
The graph above shows that while the number of MACs is correlated with the inference latency, there is significant variation in the mapping. Thus number of MACs is a poor proxy for latency, and since latency directly affects users’ experiences, we believe it is paramount to optimize latency directly rather than focusing on limiting the number of MACs as a proxy.
An Evaluation Platform As mentioned above, a primary issue with latency is that it has previously been challenging to measure reliably and repeatably, due to variations in implementation, running environment and hardware architectures. Recent successes in mobile development overcome these challenges with the help of a convenient mobile development platform, including optimized kernels for mobile CPUs, light-weight portable model formats, increasingly capable mobile devices, and more. However, these various platforms have traditionally required resources and development capabilities that are only available to larger universities and industry.
With that in mind, we are releasing OVIC’s evaluation platform that includes a number of components designed to make mobile development and evaluations that can be replicated and compared accessible to the broader research community:
TOCO compiler for optimizing TensorFlow models for efficient inference
Sample models to showcase successful mobile architectures that run inference in floating-point and quantized modes
Google’s benchmarking tool for reliable latency measurements on specific Pixel phones (available to registered contestants).
Using these tools available in OVIC, a participant can conveniently incorporate measurement of on-device latency into their design loop without having to worry about optimizing kernels, purchasing latency/power measurement devices, or designing the framework to drive them. The only requirement for entry is experiences with training computer vision models in TensorFlow, which can be found in this tutorial.
With OVIC, we encourage the entire research community to improve the classification performance of low-latency high-accuracy models towards new frontiers, as shown in the following graphic.
Sampling of current MobileNet mobile models illustrating the tradeoff between increased accuracy and reduced latency.
We cordially invite you to participate here before the deadline on June 15th, and help us discover new mobile vision architectures that will propel development into the future.
Acknowledgements We would like to acknowledge our core contributors Achille Brighton, Alec Go, Andrew Howard, Hartwig Adam, Mark Sandler and Xiao Zhang. We would also like to acknowledge our external collaborators Alex Berg and Yung-Hsiang Lu. We give special thanks to Andre Hentz, Andrew Selle, Benoit Jacob, Brad Krueger, Dmitry Kalenichenko, Megan Cummins, Pete Warden, Rajat Monga, Shiyu Hu and Yicheng Fan.
1 Alternatively the same metric could encourage even lower power operation by only processing a subset of the images in the input stream.↩
Posted by Bo Chen, Software Engineer and Jeffrey M. Gilbert, Member of Technical Staff, Google Research
Over the past year, there have been exciting innovations in the design of deep networks for vision applications on mobile devices, such as the MobileNet model family and integer quantization. Many of these innovations have been driven by performance metrics that focus on meaningful user experiences in real-world mobile applications, requiring inference to be both low-latency and accurate. While the accuracy of a deep network model can be conveniently estimated with well established benchmarks in the computer vision community, latency is surprisingly difficult to measure and no uniform metric has been established. This lack of measurement platforms and uniform metrics have hampered the development of performant mobile applications.
Today, we are happy to announce the On-device Visual Intelligence Challenge (OVIC), part of the Low-Power Image Recognition Challenge Workshop at the 2018 Computer Vision and Pattern Recognition conference (CVPR2018). A collaboration with Purdue University, the University of North Carolina and IEEE, OVIC is a public competition for real-time image classification that uses state-of-the-art Google technology to significantly lower the barrier to entry for mobile development. OVIC provides two key features to catalyze innovation: a unified latency metric and an evaluation platform.
A Unified Metric OVIC focuses on the establishment of a unified metric aligned directly with accurate and performant operation on mobile devices. The metric is defined as the number of correct classifications within a specified per-image average time limit of 33ms. This latency limit allows every frame in a live 30 frames-per-second video to be processed, thus providing a seamless user experience1. Prior to OVIC, it was tricky to enforce such a limit due to the difficulty in accurately and uniformly measuring latency as would be experienced in real-world applications on real-world devices. Without a repeatable mobile development platform, researchers have relied primarily on approximate metrics for latency that are convenient to compute, such as the number of multiply-accumulate operations (MACs). The intuition is that multiply-accumulate constitutes the most time-consuming operation in a deep neural network, so their count should be indicative of the overall latency. However, these metrics are often poor predictors of on-device latency due to many aspects of the models that can impact the average latency of each MAC in typical implementations.
Even though the number of multiply-accumulate operations (# MACs) is the most commonly used metric to approximate on-device latency, it is a poor predictor of latency. Using data from various quantized and floating point MobileNet V1 and V2 based models, this graph plots on-device latency on a common reference device versus the number of MACs. It is clear that models with similar latency can have very different MACs, and vice versa.
The graph above shows that while the number of MACs is correlated with the inference latency, there is significant variation in the mapping. Thus number of MACs is a poor proxy for latency, and since latency directly affects users’ experiences, we believe it is paramount to optimize latency directly rather than focusing on limiting the number of MACs as a proxy.
An Evaluation Platform As mentioned above, a primary issue with latency is that it has previously been challenging to measure reliably and repeatably, due to variations in implementation, running environment and hardware architectures. Recent successes in mobile development overcome these challenges with the help of a convenient mobile development platform, including optimized kernels for mobile CPUs, light-weight portable model formats, increasingly capable mobile devices, and more. However, these various platforms have traditionally required resources and development capabilities that are only available to larger universities and industry.
With that in mind, we are releasing OVIC’s evaluation platform that includes a number of components designed to make mobile development and evaluations that can be replicated and compared accessible to the broader research community:
TOCO compiler for optimizing TensorFlow models for efficient inference
Sample models to showcase successful mobile architectures that run inference in floating-point and quantized modes
Google’s benchmarking tool for reliable latency measurements on specific Pixel phones (available to registered contestants).
Using these tools available in OVIC, a participant can conveniently incorporate measurement of on-device latency into their design loop without having to worry about optimizing kernels, purchasing latency/power measurement devices, or designing the framework to drive them. The only requirement for entry is experiences with training computer vision models in TensorFlow, which can be found in this tutorial.
With OVIC, we encourage the entire research community to improve the classification performance of low-latency high-accuracy models towards new frontiers, as shown in the following graphic.
Sampling of current MobileNet mobile models illustrating the tradeoff between increased accuracy and reduced latency.
We cordially invite you to participate here before the deadline on June 15th, and help us discover new mobile vision architectures that will propel development into the future.
Acknowledgements We would like to acknowledge our core contributors Achille Brighton, Alec Go, Andrew Howard, Hartwig Adam, Mark Sandler and Xiao Zhang. We would also like to acknowledge our external collaborators Alex Berg and Yung-Hsiang Lu. We give special thanks to Andre Hentz, Andrew Selle, Benoit Jacob, Brad Krueger, Dmitry Kalenichenko, Megan Cummins, Pete Warden, Rajat Monga, Shiyu Hu and Yicheng Fan.
1 Alternatively the same metric could encourage even lower power operation by only processing a subset of the images in the input stream.↩
Posted by Bill Luan, Senior Program Manager & Greater China Regional Lead, Developer Relations
The 2018 China-U.S. Young Maker Competition launched this week by the event co-organizer Hackster.IO. Project submissions are now open to all makers, developers, and students ages 18-40 in both China and the United States. Google is the corporate sponsor for this year's competition.
Since 2014, this competition has been running annually in supporting the U.S.-China High-Level Consultation on People-to-People Exchange program. The competition encourages makers in both countries to create innovative products focusing on community development, education, environmental protection, health & fitness, energy, transportation and sustainable development.
Participants have the freedom to choose appropriate technologies to enable their innovations, and we encourage makers to consider open source technologies, such as TensorFlow and AIY Projects for artificial intelligence use cases, Android Studio for mobile applications, as well as Android Things for IoT solutions.
The top 10 projects in the U.S. will win an all-expenses-paid trip to Beijing, to compete against Chinese makers on August 13-17 for the chance at $30,000 in prizes. Further, there are 35 additional chances to win Google prizes! So join the competition, and let your innovation shine on the global stage!
For more details, please see the event announcement on Hackster.IO.
Originally posted by Sandeep Gupta, Product Manager for TensorFlow, on behalf of the TensorFlow team on the TensorFlow Blog.
On March 30th, we held the second TensorFlow Developer Summit at the Computer History Museum in Mountain View, CA! The event brought together over 500 TensorFlow users in-person and thousands tuning into the livestream at TensorFlow events around the world. The day was filled with new product announcements along with technical talks from the TensorFlow team and guest speakers. Here are the highlights from the event:
Machine learning is solving challenging problems that impact everyone around the world. Problems that we thought were impossible or too complex to solve are now possible with this technology. Using TensorFlow, we've already seen great advancements in many different fields. For example:
Astrophysicists are using TensorFlow to analyze large amounts of data from the Kepler mission to discover new planets.
Scientists in Africa are using TensorFlow to detect diseases in Cassava plants to improving yield for farmers.
We're excited to see these amazing uses of TensorFlow and are committed to making it accessible to more developers. This is why we're pleased to announce new updates to TensorFlow that will help improve the developer experience!
We're making TensorFlow easier to use
Researchers and developers want a simpler way of using TensorFlow. We're integrating a more intuitive programming model for Python developers called eager execution that removes the distinction between the construction and execution of computational graphs. You can develop with eager execution and then use the same code to generate the equivalent graph for training at scale using the Estimator high-level API. We're also announcing a new method for running Estimator models on multiple GPUs on a single machine. This allows developers to quickly scale their models with minimal code changes.
As machine learning models become more abundant and complex, we want to make it easier for developers to share, reuse, and debug them. To help developers share and reuse models, we're announcing TensorFlow Hub, a library built to foster the publication and discovery of modules (self-contained pieces of TensorFlow graph) that can be reused across similar tasks. Modules contain weights that have been pre-trained on large datasets, and may be retrained and used in your own applications. By reusing a module, a developer can train a model using a smaller dataset, improve generalization, or simply speed up training. To make debugging models easier, we're also releasing a new interactive graphical debugger plug-in as part of the TensorBoard visualization tool that helps you inspect and step through internal nodes of a computation graph in real-time.
Model training is only one part of the machine learning process and developers need a solution that works end-to-end to build real-world ML systems. Towards this end, we're announcing the roadmap for TensorFlow Extended (TFX) along with the launch of TensorFlow Model Analysis, an open-source library that combines the power of TensorFlow and Apache Beam to compute and visualize evaluation metrics. The components of TFX that have been released thus far (including TensorFlow Model Analysis, TensorFlow Transform, Estimators, and TensorFlow Serving) are well integrated and let developers prepare data, train, validate, and deploy TensorFlow models in production.
TensorFlow is available in more languages and platforms
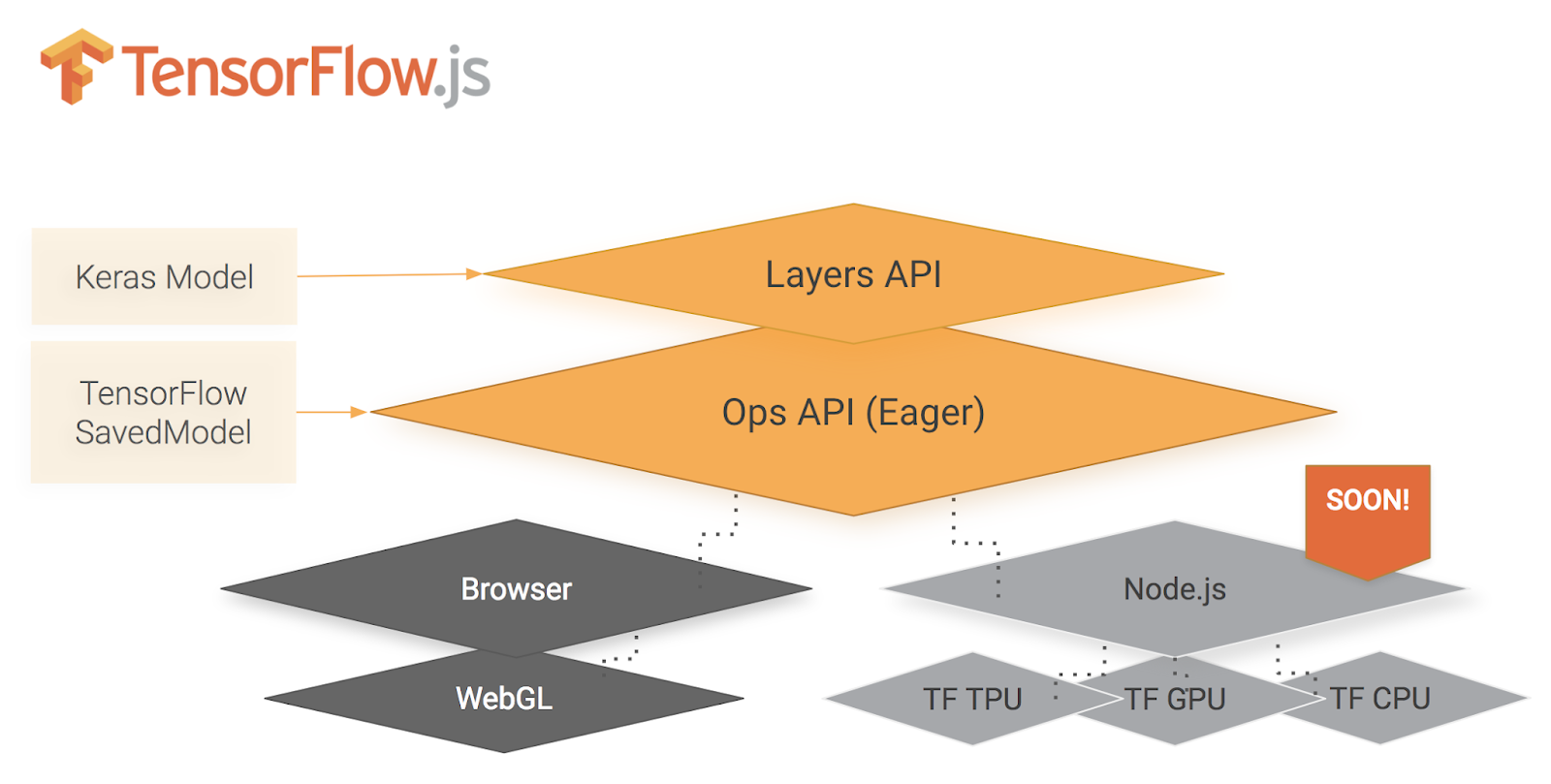
Along with making TensorFlow easier to use, we're announcing that developers can use TensorFlow in new languages. TensorFlow.js is a new ML framework for JavaScript developers. Machine learning in the browser using TensorFlow.js opens exciting new possibilities, including interactive ML and support for scenarios where all data remains client-side. It can be used to build and train modules entirely in the browser, as well as import TensorFlow and Keras models trained offline for inference using WebGL acceleration. The Emoji Scavenger Hunt game is a fun example of an application built using TensorFlow.js.
We also have some exciting news for Swift programmers: TensorFlow for Swift will be open sourced this April. TensorFlow for Swift is not your typical language binding for TensorFlow. It integrates first-class compiler and language support, providing the full power of graphs with the usability of eager execution. The project is still in development, with more updates coming soon!
We're also sharing the latest updates to TensorFlow Lite, TensorFlow's lightweight, cross-platform solution for deploying trained ML models on mobile and other edge devices. In addition to existing support for Android and iOS, we're announcing support for Raspberry Pi, increased support for ops/models (including custom ops), and describing how developers can easily use TensorFlow Lite in their own apps. The TensorFlow Lite core interpreter is now only 75KB in size (vs 1.1 MB for TensorFlow) and we're seeing speedups of up to 3x when running quantized image classification models on TensorFlow Lite vs. TensorFlow.
For hardware support, TensorFlow now has integration with NVIDIA's TensorRT. TensorRT is a library that optimizes deep learning models for inference and creates a runtime for deployment on GPUs in production environments. It brings a number of optimizations to TensorFlow and automatically selects platform specific kernels to maximize throughput and minimizes latency during inference on GPUs.
For users who run TensorFlow on CPUs, our partnership with Intel has delivered integration with a highly optimized Intel MKL-DNN open source library for deep learning. When using Intel MKL-DNN, we observed up to 3x inference speedup on various Intel CPU platforms.
The list of platforms that run TensorFlow has grown to include Cloud TPUs, which were released in beta last month. The Google Cloud TPU team has already delivered a strong 1.6X performance increase in ResNet-50 performance since launch. These improvements will be available to TensorFlow users with the 1.8 release soon.
Enabling new applications and domains using TensorFlow
Many data analysis problems are solved using statistical and probabilistic methods. Beyond deep learning and neural network models, TensorFlow now provides state-of-the-art methods for Bayesian analysis via the TensorFlow Probability API. This library contains building blocks like probability distributions, sampling methods, and new metrics and losses. Many other classical ML methods also have increased support. As an example, boosted decision trees can be easily trained and deployed using pre-made high-level classes.
Machine learning and TensorFlow have already helped solve challenging problems in many different fields. Another area where we see TensorFlow having a big impact is in genomics, which is why we're releasing Nucleus, a library for reading, writing, and filtering common genomics file formats for use in TensorFlow. This, along with DeepVariant, an open-source TensorFlow based tool for genome variant discovery, will help spur new research and advances in genomics.
Expanding community resources and engagement
These updates to TensorFlow aim to benefit and grow the community of users and contributors - the thousands of people who play a part in making TensorFlow one of the most popular ML frameworks in the world. To continue to engage with the community and stay up-to-date with TensorFlow, we've launched the new official TensorFlow blog and the TensorFlow YouTube channel. We're also making it easier for our community to collaborate by launching new mailing lists and Special Interest Groups designed to support open-source work on specific projects. To see how you can be a part of the community, visit the TensorFlow Community page and as always, you can follow TensorFlow on Twitter for the latest news.
We're incredibly thankful to everyone who has helped make TensorFlow a successful ML framework in the past two years. Thanks for attending, thanks for watching, and remember to use #MadeWithTensorFlow to share how you are solving impactful and challenging problems with machine learning and TensorFlow!
Posted by Mark Sandler and Andrew Howard, Google Research
Last year we introduced MobileNetV1, a family of general purpose computer vision neural networks designed with mobile devices in mind to support classification, detection and more. The ability to run deep networks on personal mobile devices improves user experience, offering anytime, anywhere access, with additional benefits for security, privacy, and energy consumption. As new applications emerge allowing users to interact with the real world in real time, so does the need for ever more efficient neural networks.
Today, we are pleased to announce the availability of MobileNetV2 to power the next generation of mobile vision applications. MobileNetV2 is a significant improvement over MobileNetV1 and pushes the state of the art for mobile visual recognition including classification, object detection and semantic segmentation. MobileNetV2 is released as part of TensorFlow-Slim Image Classification Library, or you can start exploring MobileNetV2 right away in Colaboratory. Alternately, you can download the notebook and explore it locally using Jupyter. MobileNetV2 is also available as modules on TF-Hub, and pretrained checkpoints can be found on github.
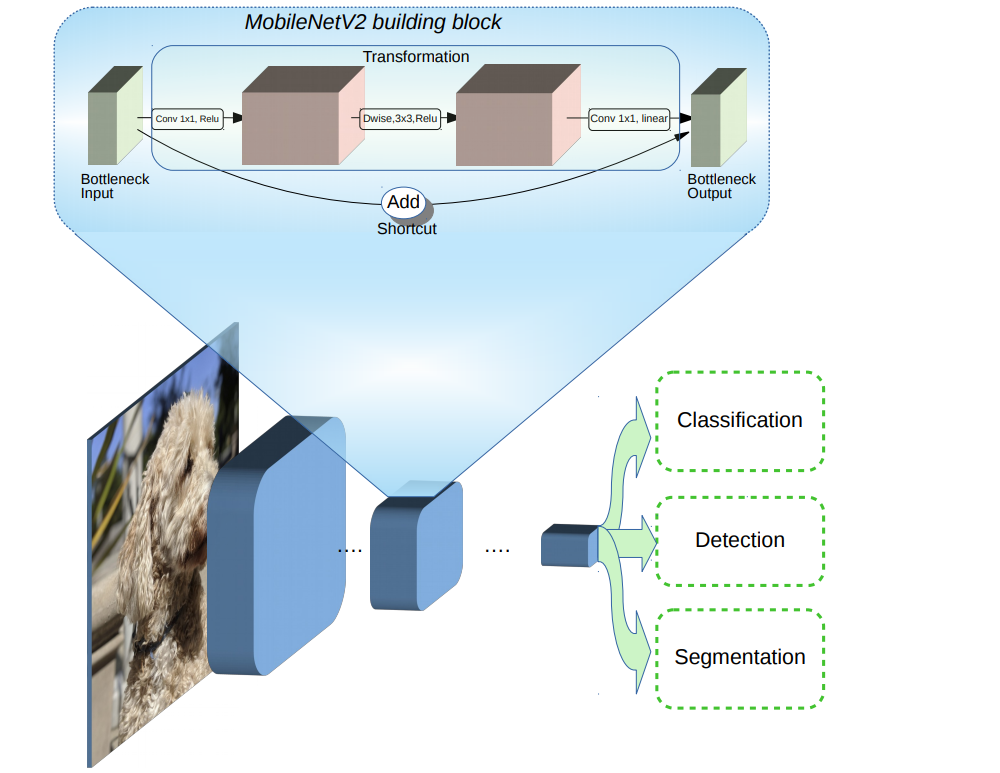
MobileNetV2 builds upon the ideas from MobileNetV1 [1], using depthwise separable convolution as efficient building blocks. However, V2 introduces two new features to the architecture: 1) linear bottlenecks between the layers, and 2) shortcut connections between the bottlenecks1. The basic structure is shown below.
Overview of MobileNetV2 Architecture. Blue blocks represent composite convolutional building blocks as shown above.
The intuition is that the bottlenecks encode the model’s intermediate inputs and outputs while the inner layer encapsulates the model’s ability to transform from lower-level concepts such as pixels to higher level descriptors such as image categories. Finally, as with traditional residual connections, shortcuts enable faster training and better accuracy. You can learn more about the technical details in our paper, “MobileNet V2: Inverted Residuals and Linear Bottlenecks”.
How does it compare to the first generation of MobileNets? Overall, the MobileNetV2 models are faster for the same accuracy across the entire latency spectrum. In particular, the new models use 2x fewer operations, need 30% fewer parameters and are about 30-40% faster on a Google Pixel phone than MobileNetV1 models, all while achieving higher accuracy.
MobileNetV2 improves speed (reduced latency) and increased ImageNet Top 1 accuracy
MobileNetV2 is a very effective feature extractor for object detection and segmentation. For example, for detection when paired with the newly introduced SSDLite [2] the new model is about 35% faster with the same accuracy than MobileNetV1. We have open sourced the model under the Tensorflow Object Detection API [4].
To enable on-device semantic segmentation, we employ MobileNetV2 as a feature extractor in a reduced form of DeepLabv3 [3], that was announced recently. On the semantic segmentation benchmark, PASCAL VOC 2012, our resulting model attains a similar performance as employing MobileNetV1 as feature extractor, but requires 5.3 times fewer parameters and 5.2 times fewer operations in terms of Multiply-Adds.
As we have seen MobileNetV2 provides a very efficient mobile-oriented model that can be used as a base for many visual recognition tasks. We hope by sharing it with the broader academic and open-source community we can help to advance research and application development.
Acknowledgements: We would like to acknowledge our core contributors Menglong Zhu, Andrey Zhmoginov and Liang-Chieh Chen. We also give special thanks to Bo Chen, Dmitry Kalenichenko, Skirmantas Kligys, Mathew Tang, Weijun Wang, Benoit Jacob, George Papandreou, Zhichao Lu, Vivek Rathod, Jonathan Huang, Yukun Zhu, and Hartwig Adam.
1 The shortcut (also known as skip) connections, popularized by ResNets[5] are commonly used to connect the non-bottleneck layers. MobilenNetV2 inverts this notion and connects the bottlenecks directly.↩