 Posted by Mayank Jain - Product Manager, and Yasser Dbeis - Software Engineer; Android Studio
Posted by Mayank Jain - Product Manager, and Yasser Dbeis - Software Engineer; Android Studio
Android developers have been telling us they're looking for tools to help optimize power consumption for different devices on Android.
The new Power Profiler in Android Studio helps Android developers by showing power consumption happening on devices as the app is being used. Understanding power consumption across Android devices can help Android developers identify and fix power consumption issues in their apps. They can run A/B tests to compare the power consumption of different algorithms, features or even different versions of their app.
Apps which are optimized for lower power consumption lead to an improved battery and thermal performance of the device, which means an improved user experience on Android.
This power consumption data is made available through the On Device Power Monitor (ODPM) on Pixel 6+ devices, segmented by each sub-system called “Power Rails”. See Profileable power rails for a list of supported sub-systems.
The Power Profiler can help app developers detect problems in several areas:
- Detecting unoptimized code that is using more power than necessary.
- Finding background tasks that are causing unnecessary CPU usage.
- Identifying wakelocks that are keeping the device awake when they are not needed.
Once a power consumption issue has been identified, the Power Profiler can be used when testing different hypotheses to understand why the app could be consuming excessive power. For example, if the issue is caused by background tasks, the developer can try to stop the tasks from running unnecessarily or for longer periods. And if the issue is caused by wakelocks, the developer can try to release the wakelocks when the resource is not in use or use them more judiciously. Then compare the power consumption before/after the change using the Power Profiler.
In this blog post, we showcase a technique which uses A/B testing to understand how your app’s power consumption characteristics might change with different versions of the same feature - and how you can effectively measure them.
A real-life example of how the Power Profiler can be used to improve the battery life of an app.
Let’s assume you have an app through which users can purchase their favorite movies.
As your app becomes popular and is used by more users, you realize that a high quality 4K video takes very long to load every time the app is started. Because of its large size, you want to understand its impact on power consumption on the device.
Originally, this video was in 4K quality in the best of intentions, so as to showcase the best possible movie highlights to your customers.
This makes you think…
- Do you really need a 4K video banner on the home screen?
- Does it make sense to load a 4K video over the network every time your app is run?
- How will the power consumption characteristics of your app change if you replace the 4K video with something of lower quality (while still preserving the vivid look & feel of the video)?
This is a perfect scenario to perform an A/B test for power consumption
With an A/B test, you can test two slightly different variations of the video banner feature and choose the one with the better power consumption characteristics.
Scenario A : Run the app with 4K video banner on screen & measure power consumption
Scenario B : Run the app with lower resolution video banner on screen & measure power consumption
A/B Test setup
Let's take a moment and set up our Android Studio profiler to run this A/B test. We need to start the app and attach the CPU profiler to it and trigger a system trace (where the Power Profiler will be shown).
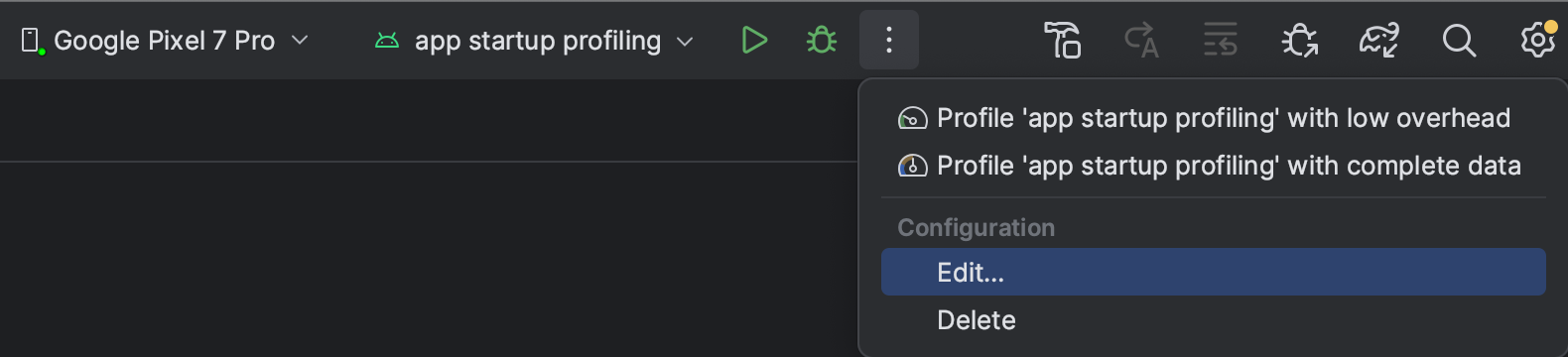
Step 1
Create a custom “Run configuration” by clicking the 3 dot menu > Edit
Step 2
Then select the “Profiling” tab and ensure that “Start this recording on startup” and CPU Activity > System Trace is selected. Then click “Apply”.
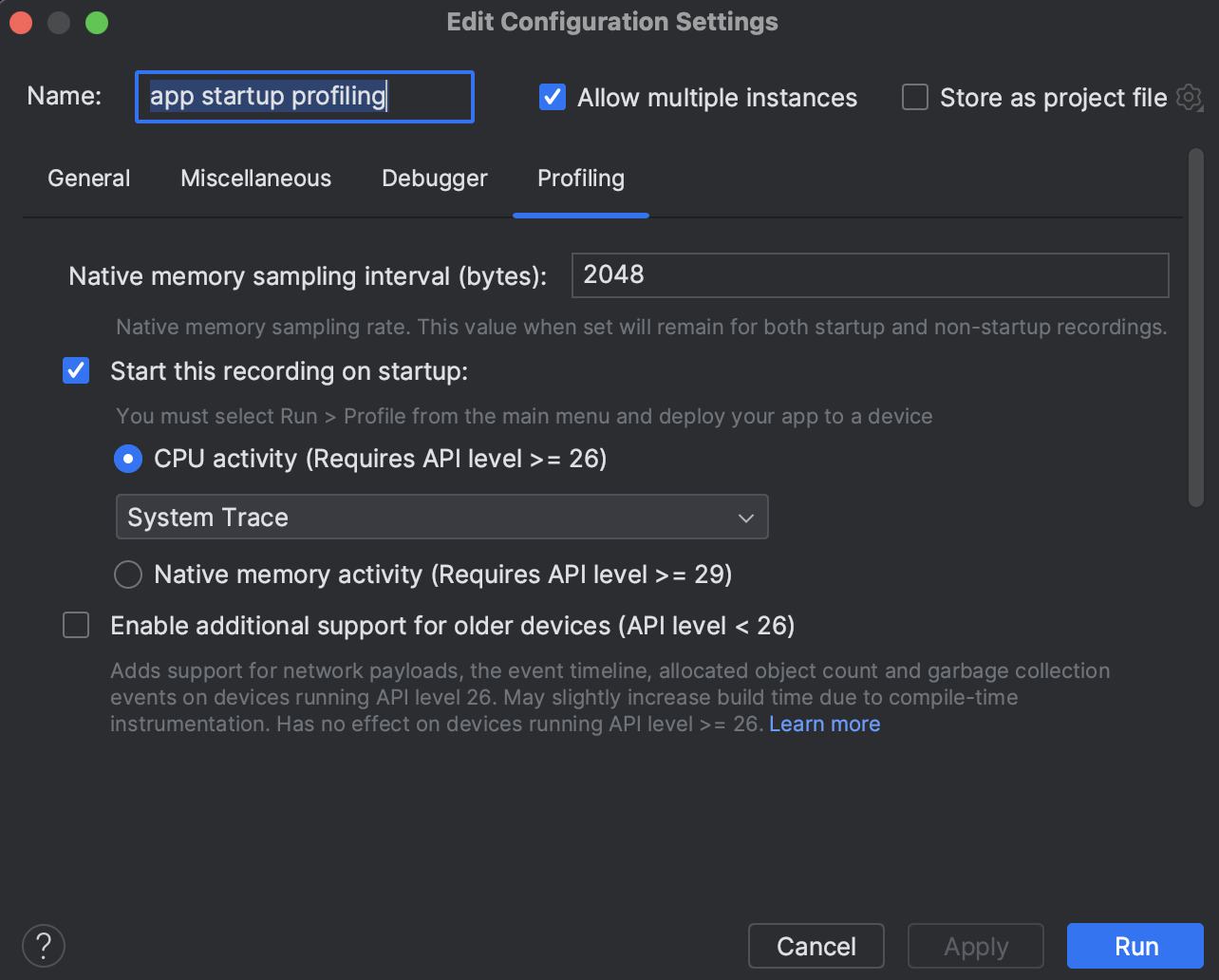
Now simply run the “Profile app startup profiling with low overhead” whenever you want to run this app from start and attach the CPU profiler to it.
Note on precision
The following example scenarios use the entire app startup for estimating the power consumption for this blog’s purpose. However you can use more advanced techniques to have even higher precision in getting power readings. Some techniques to try are:
- Isolate and measure power consumption for video playback only after a tap event on the video player
- Use the trace markers API to mark the start and stop time for power measurement timeline - and then only measure power consumption within that marked window
Scenario A
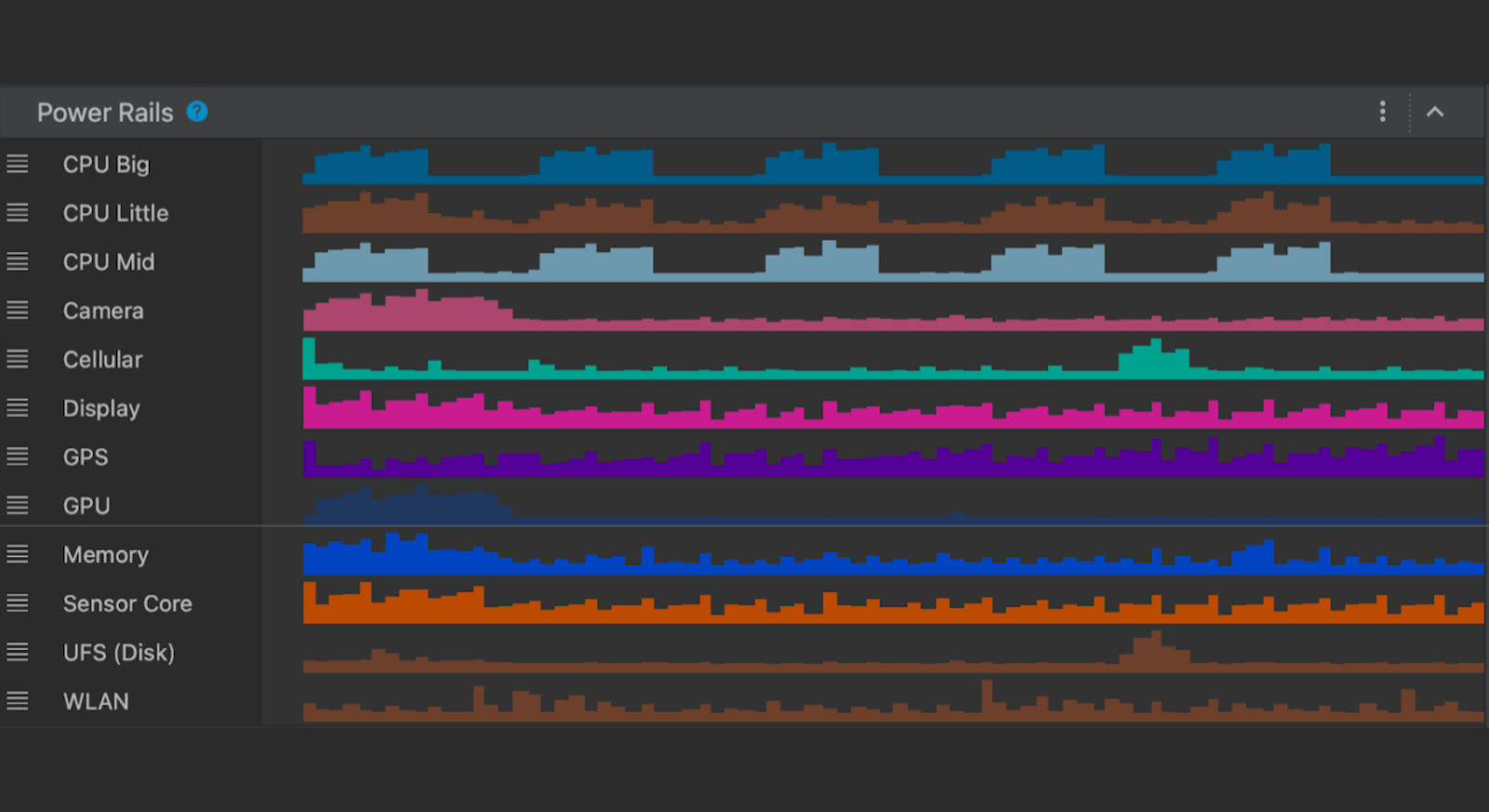
In this scenario, we run the app with 4K video playing and measure power consumption for the first 30 seconds. We can optionally also run the scenario A multiple times and average out the readings. Once the System trace is shown in Android Studio, select the 0-30 second time range from the timeline selection panel and record as a screenshot for comparing against scenario B
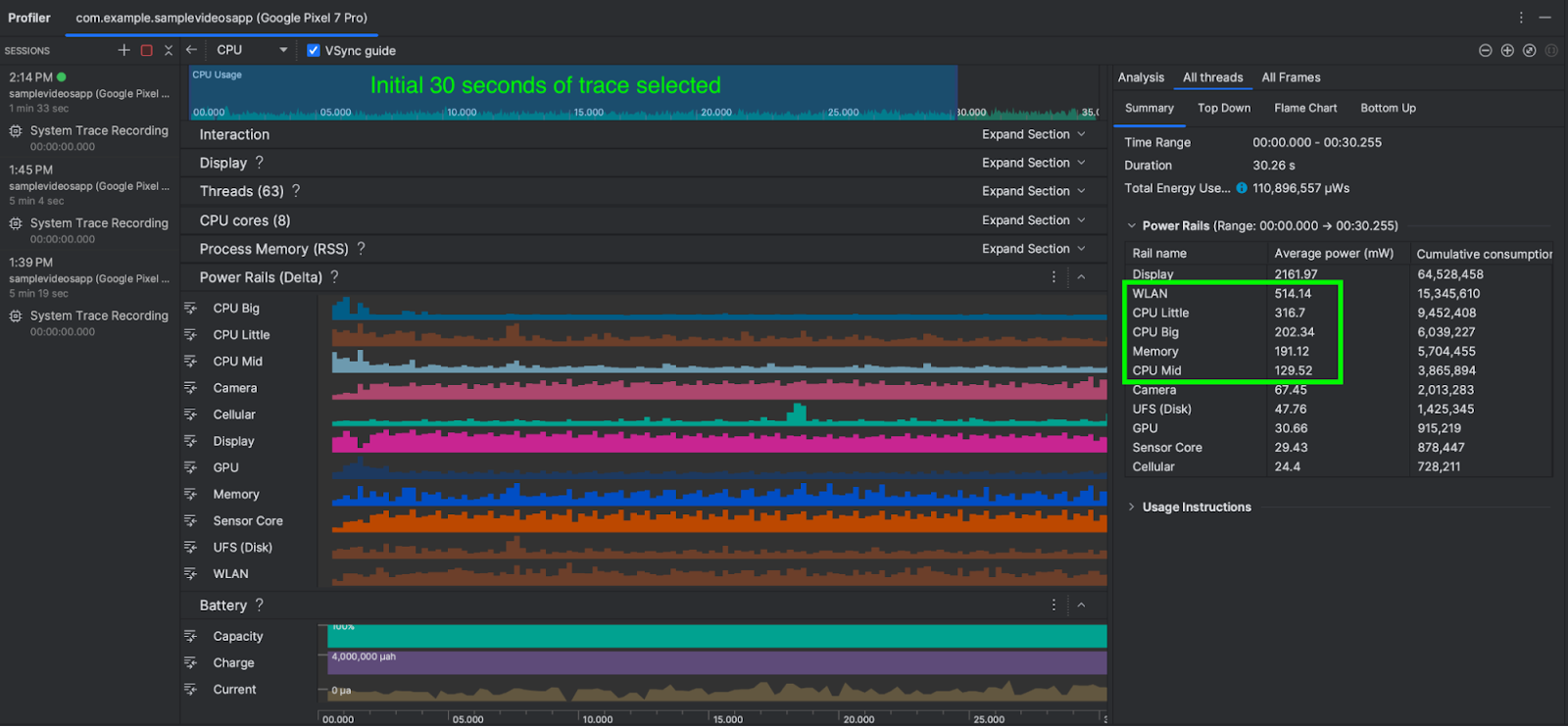
As you can see, the average power consumed by WLAN, CPU cores & Memory combined is about 1,352 mW (milliwatts)
Now let's compare and contrast how this power consumption changes in Scenario B
Scenario B
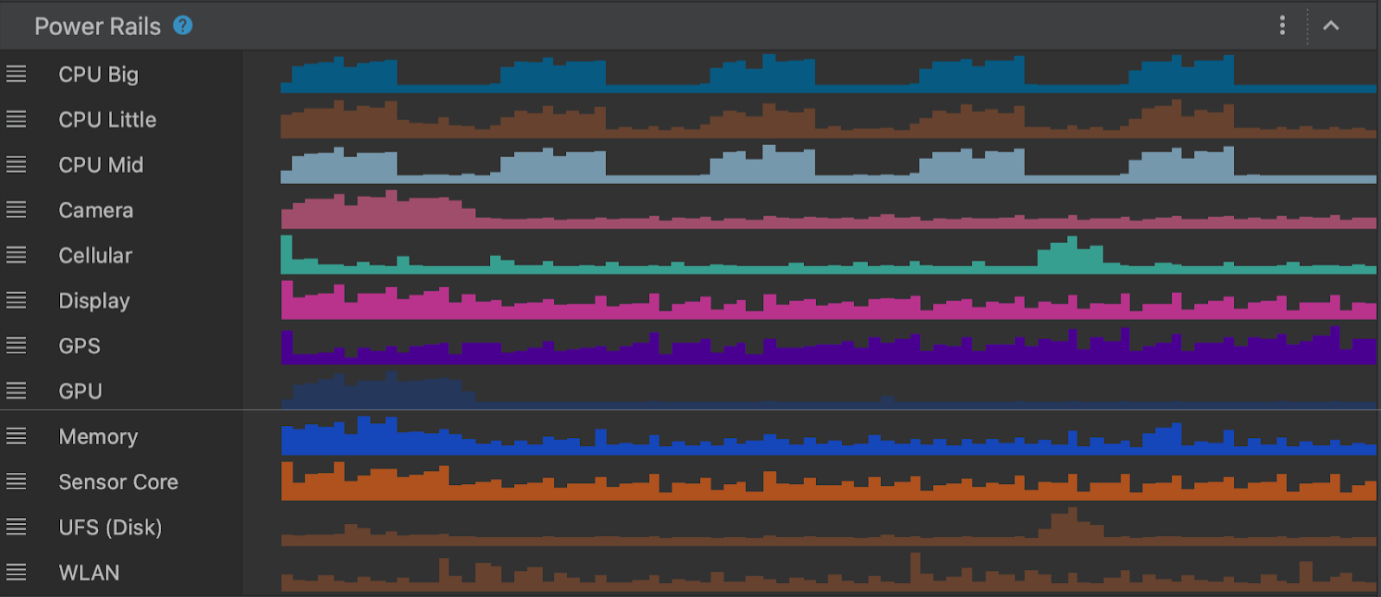
In this scenario, we run the app with low quality video playing and measure power consumption for the first 30 seconds. As before, we can also optionally run scenario B multiple times and average out the power consumption readings. Again, once the System trace is shown in Android Studio, select the 0-30 second time range from the timeline selection panel.
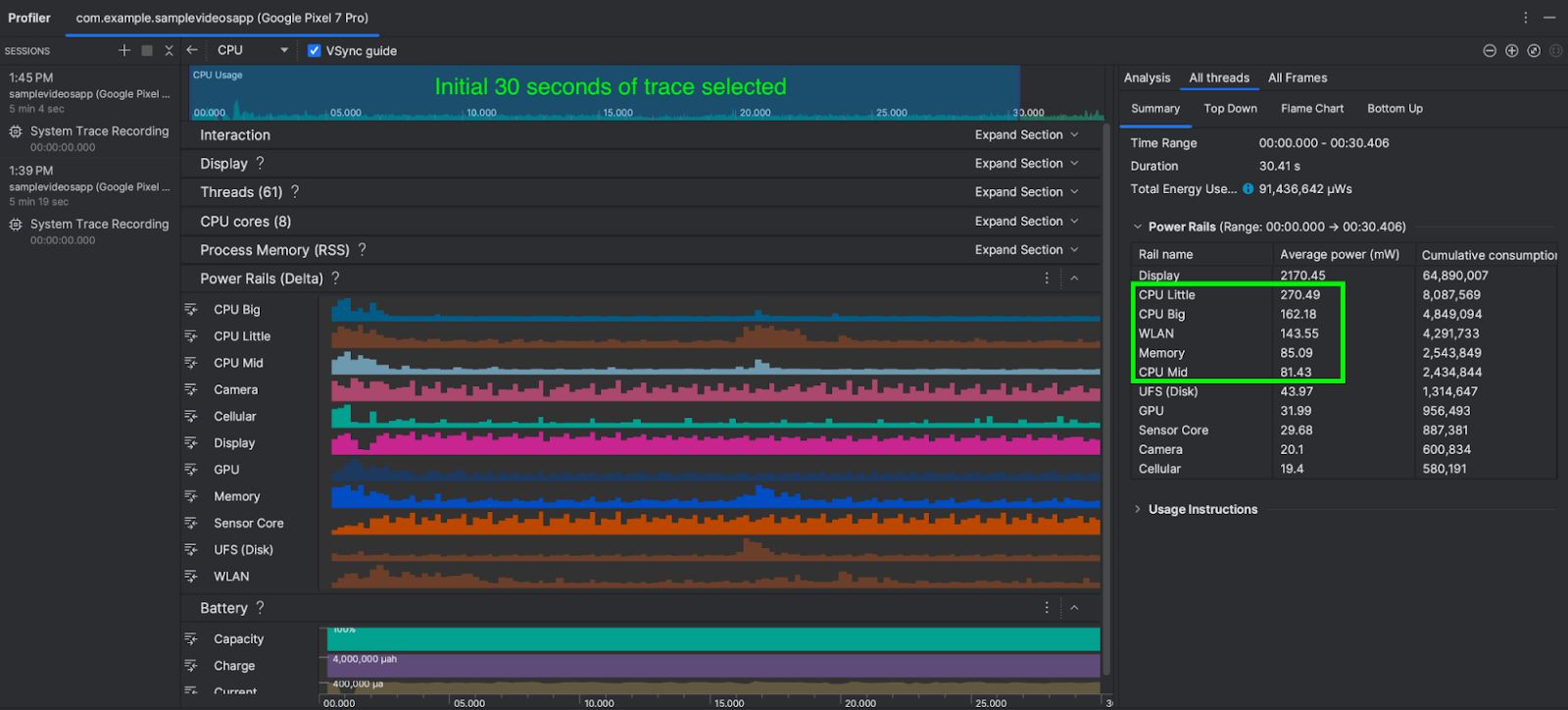
The total power consumed by WLAN, CPU Little, CPU Big and CPU Mid & Memory is about 741 mW (milliwatts)
Conclusion
All else being equal, Scenario B (with lower quality video) consumed 741 mW power as compared to Scenario A (with 4K video) which required 1,352 mW power.
Scenario B (lower quality video) took 45% less power than Scenario A (4K) - while the lower quality video provides little to no visual difference in perceived quality of the app’s screen.
As a result of this A/B test for power consumption, you conclude that replacing the 4K video with a lower quality video on our app’s home screen not only reduces power consumption by 45%, also reduces the required network bandwidth and can potentially also improve the thermal performance of the devices.
If your app’s business logic still requires the 4K video to be shown on the app’s screen, you can explore strategies like:
- Caching the 4K video across subsequent runs of the app.
- Loading video on a user tap.
- Loading an image initially and only load the video after the screen has fully rendered (delayed loading).
The overall power consumption numbers presented in the above A/B test scenario might seem small, but it shows the techniques that app developers can use to effectively A/B test power consumption for their app’s features using the Power Profiler in Android Studio.
Next Steps
The new Power Profiler is available in Android Studio Hedgehog onwards. To know more, please head over to the official documentation.
 Posted by Mark Sherwood – Senior Product Manager and Juhyun Lee – Staff Software Engineer
Posted by Mark Sherwood – Senior Product Manager and Juhyun Lee – Staff Software Engineer



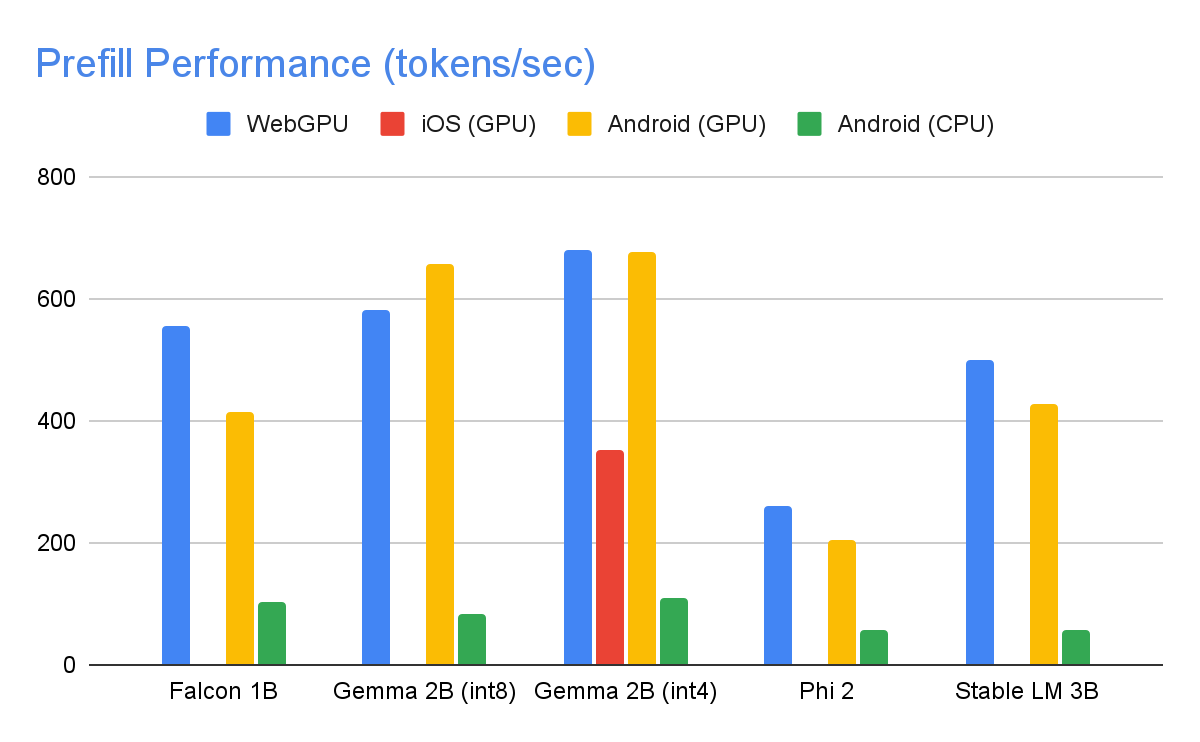


 Posted by Chanel Greco, Developer Advocate
Posted by Chanel Greco, Developer Advocate