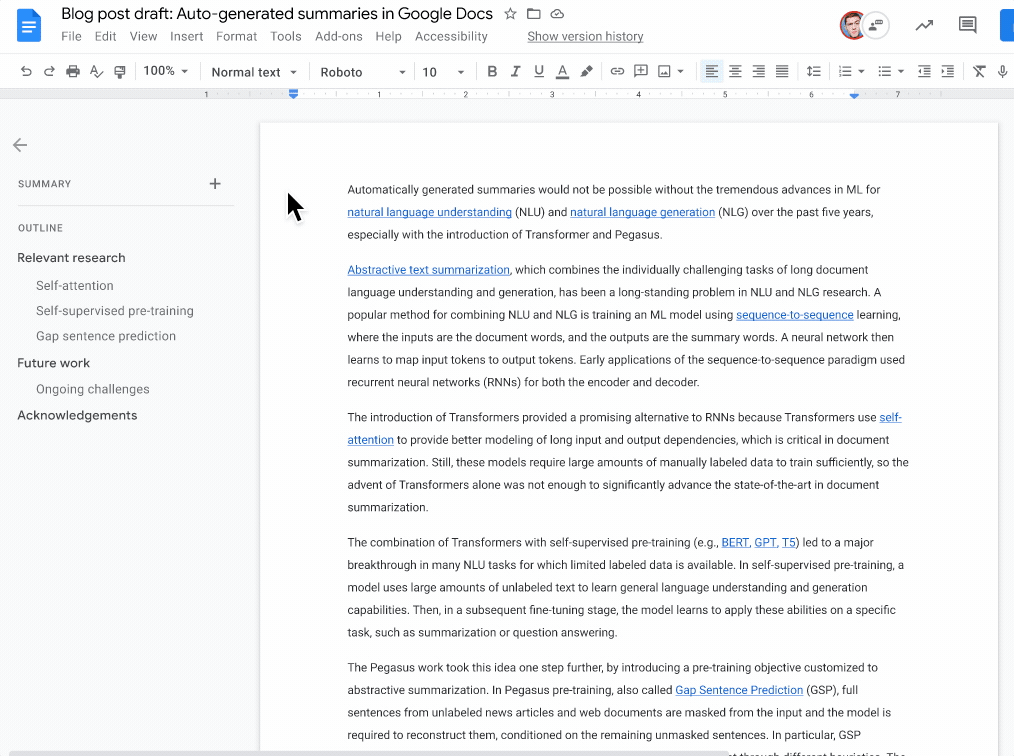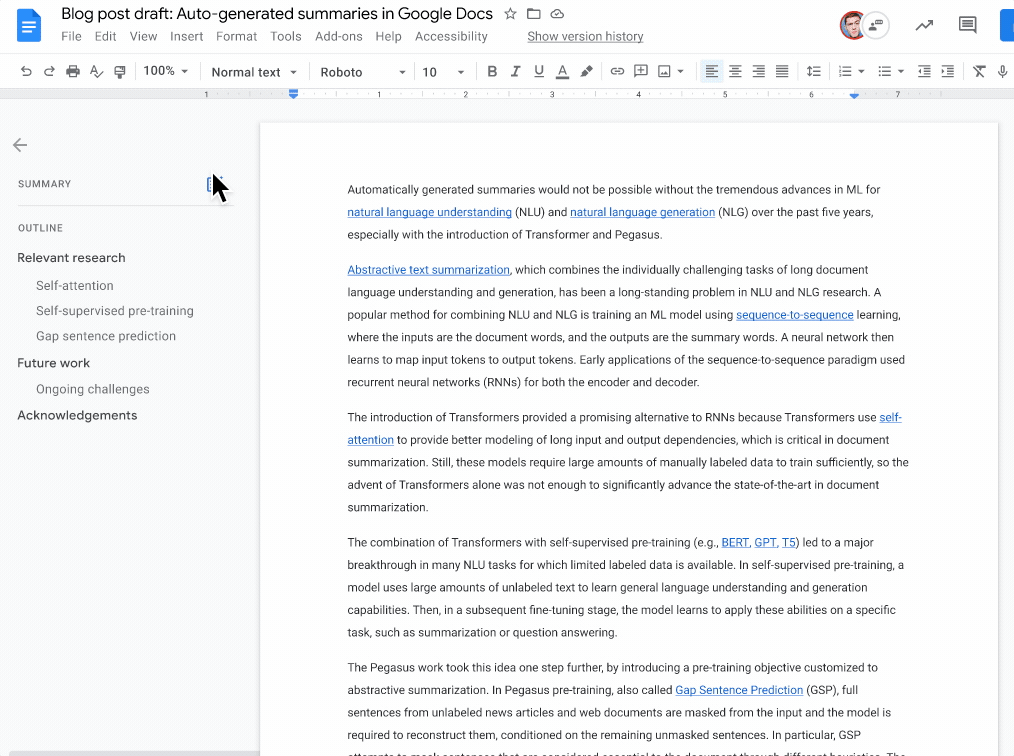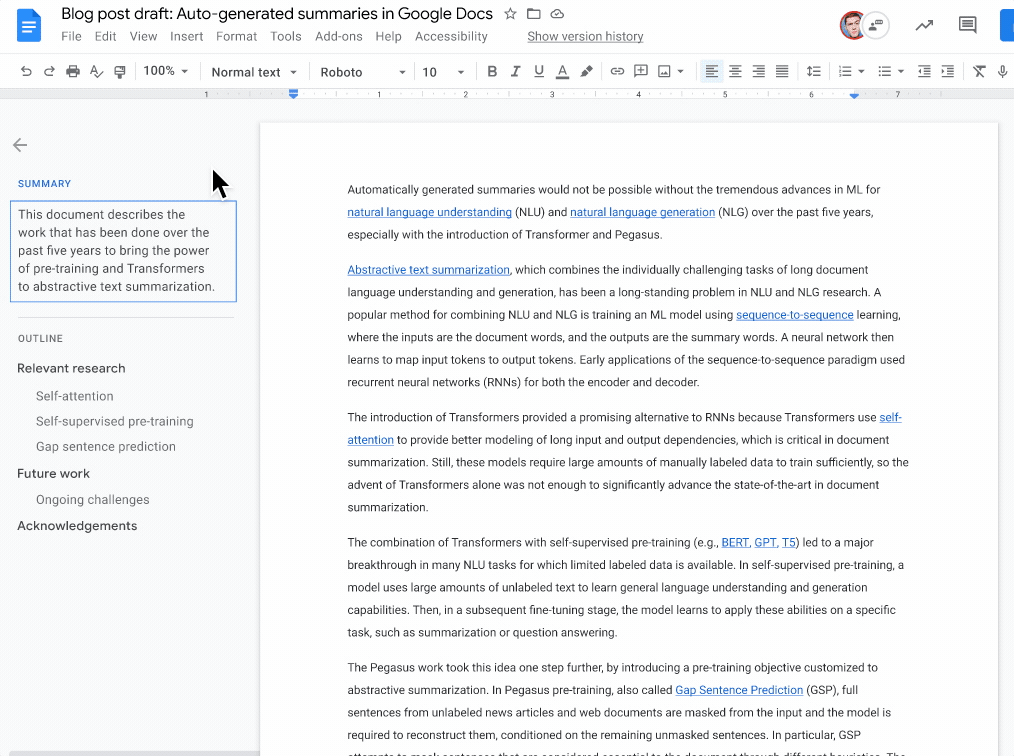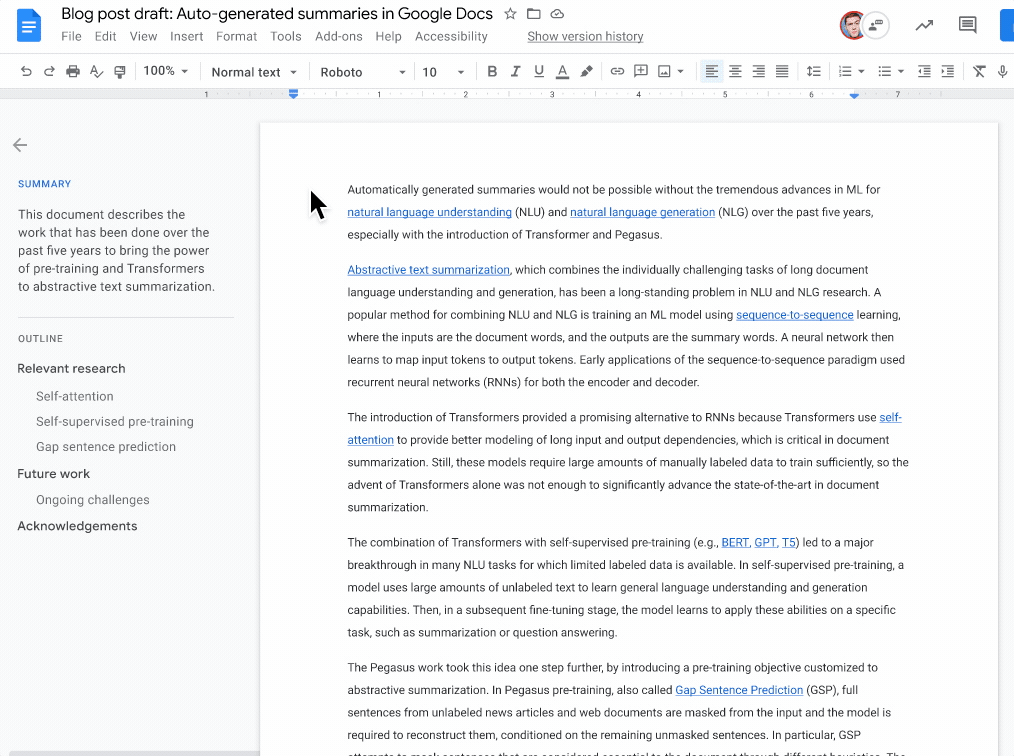
A common approach used to control robots is to program them with code to detect objects, sequencing commands to move actuators, and feedback loops to specify how the robot should perform a task. While these programs can be expressive, re-programming policies for each new task can be time consuming, and requires domain expertise.
What if when given instructions from people, robots could autonomously write their own code to interact with the world? It turns out that the latest generation of language models, such as PaLM, are capable of complex reasoning and have also been trained on millions of lines of code. Given natural language instructions, current language models are highly proficient at writing not only generic code but, as we’ve discovered, code that can control robot actions as well. When provided with several example instructions (formatted as comments) paired with corresponding code (via in-context learning), language models can take in new instructions and autonomously generate new code that re-composes API calls, synthesizes new functions, and expresses feedback loops to assemble new behaviors at runtime. More broadly, this suggests an alternative approach to using machine learning for robots that (i) pursues generalization through modularity and (ii) leverages the abundance of open-source code and data available on the Internet.
 |
| Given code for an example task (left), language models can re-compose API calls to assemble new robot behaviors for new tasks (right) that use the same functions but in different ways. |
To explore this possibility, we developed Code as Policies (CaP), a robot-centric formulation of language model-generated programs executed on physical systems. CaP extends our prior work, PaLM-SayCan, by enabling language models to complete even more complex robotic tasks with the full expression of general-purpose Python code. With CaP, we propose using language models to directly write robot code through few-shot prompting. Our experiments demonstrate that outputting code led to improved generalization and task performance over directly learning robot tasks and outputting natural language actions. CaP allows a single system to perform a variety of complex and varied robotic tasks without task-specific training.
| We demonstrate, across several robot systems, including a robot from Everyday Robots, that language models can autonomously interpret language instructions to generate and execute CaPs that represent reactive low-level policies (e.g., proportional-derivative or impedance controllers) and waypoint-based policies (e.g., vision-based pick and place, trajectory-based control). |
A Different Way to Think about Robot Generalization
To generate code for a new task given natural language instructions, CaP uses a code-writing language model that, when prompted with hints (i.e., import statements that inform which APIs are available) and examples (instruction-to-code pairs that present few-shot "demonstrations" of how instructions should be converted into code), writes new code for new instructions. Central to this approach is hierarchical code generation, which prompts language models to recursively define new functions, accumulate their own libraries over time, and self-architect a dynamic codebase. Hierarchical code generation improves state-of-the-art on both robotics as well as standard code-gen benchmarks in natural language processing (NLP) subfields, with 39.8% pass@1 on HumanEval, a benchmark of hand-written coding problems used to measure the functional correctness of synthesized programs.
Code-writing language models can express a variety of arithmetic operations and feedback loops grounded in language. Pythonic language model programs can use classic logic structures, e.g., sequences, selection (if/else), and loops (for/while), to assemble new behaviors at runtime. They can also use third-party libraries to interpolate points (NumPy), analyze and generate shapes (Shapely) for spatial-geometric reasoning, etc. These models not only generalize to new instructions, but they can also translate precise values (e.g., velocities) to ambiguous descriptions ("faster" and "to the left") depending on the context to elicit behavioral commonsense.
 |
| Code as Policies uses code-writing language models to map natural language instructions to robot code to complete tasks. Generated code can call existing perception action APIs, third party libraries, or write new functions at runtime. |
CaP generalizes at a specific layer in the robot: interpreting natural language instructions, processing perception outputs (e.g., from off-the-shelf object detectors), and then parameterizing control primitives. This fits into systems with factorized perception and control, and imparts a degree of generalization (acquired from pre-trained language models) without the magnitude of data collection needed for end-to-end robot learning. CaP also inherits language model capabilities that are unrelated to code writing, such as supporting instructions with non-English languages and emojis.
 |
| CaP inherits the capabilities of language models, such as multilingual and emoji support. |
By characterizing the types of generalization encountered in code generation problems, we can also study how hierarchical code generation improves generalization. For example, "systematicity" evaluates the ability to recombine known parts to form new sequences, "substitutivity" evaluates robustness to synonymous code snippets, while "productivity" evaluates the ability to write policy code longer than those seen in the examples (e.g., for new long horizon tasks that may require defining and nesting new functions). Our paper presents a new open-source benchmark to evaluate language models on a set of robotics-related code generation problems. Using this benchmark, we find that, in general, bigger models perform better across most metrics, and that hierarchical code generation improves "productivity" generalization the most.
 |
| Performance on our RoboCodeGen Benchmark across different generalization types. The larger model (Davinci) performs better than the smaller model (Cushman), with hierarchical code generation improving productivity the most. |
We're also excited about the potential for code-writing models to express cross-embodied plans for robots with different morphologies that perform the same task differently depending on the available APIs (perception action spaces), which is an important aspect of any robotics foundation model.
 |
| Language model code-generation exhibits cross-embodiment capabilities, completing the same task in different ways depending on the available APIs (that define perception action spaces). |
Limitations
Code as policies today are restricted by the scope of (i) what the perception APIs can describe (e.g., few visual-language models to date can describe whether a trajectory is "bumpy" or "more C-shaped"), and (ii) which control primitives are available. Only a handful of named primitive parameters can be adjusted without over-saturating the prompts. Our approach also assumes all given instructions are feasible, and we cannot tell if generated code will be useful a priori. CaPs also struggle to interpret instructions that are significantly more complex or operate at a different abstraction level than the few-shot examples provided to the language model prompts. Thus, for example, in the tabletop domain, it would be difficult for our specific instantiation of CaPs to "build a house with the blocks" since there are no examples of building complex 3D structures. These limitations point to avenues for future work, including extending visual language models to describe low-level robot behaviors (e.g., trajectories) or combining CaPs with exploration algorithms that can autonomously add to the set of control primitives.
Open-Source Release
We have released the code needed to reproduce our experiments and an interactive simulated robot demo on the project website, which also contains additional real-world demos with videos and generated code.
Conclusion
Code as policies is a step towards robots that can modify their behaviors and expand their capabilities accordingly. This can be enabling, but the flexibility also raises potential risks since synthesized programs (unless manually checked per runtime) may result in unintended behaviors with physical hardware. We can mitigate these risks with built-in safety checks that bound the control primitives that the system can access, but more work is needed to ensure new combinations of known primitives are equally safe. We welcome broad discussion on how to minimize these risks while maximizing the potential positive impacts towards more general-purpose robots.
Acknowledgements
This research was done by Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng. Special thanks to Vikas Sindhwani, Vincent Vanhoucke for helpful feedback on writing, Chad Boodoo for operations and hardware support. An early preprint is available on arXiv.























.gif)