Adaptive computation refers to the ability of a machine learning system to adjust its behavior in response to changes in the environment. While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
Adaptive computation in neural networks is appealing for two key reasons. First, the mechanism that introduces adaptivity provides an inductive bias that can play a key role in solving some challenging tasks. For instance, enabling different numbers of computational steps for different inputs can be crucial in solving arithmetic problems that require modeling hierarchies of different depths. Second, it gives practitioners the ability to tune the cost of inference through greater flexibility offered by dynamic computation, as these models can be adjusted to spend more FLOPs processing a new input.
Neural networks can be made adaptive by using different functions or computation budgets for various inputs. A deep neural network can be thought of as a function that outputs a result based on both the input and its parameters. To implement adaptive function types, a subset of parameters are selectively activated based on the input, a process referred to as conditional computation. Adaptivity based on the function type has been explored in studies on mixture-of-experts, where the sparsely activated parameters for each input sample are determined through routing.
Another area of research in adaptive computation involves dynamic computation budgets. Unlike in standard neural networks, such as T5, GPT-3, PaLM, and ViT, whose computation budget is fixed for different samples, recent research has demonstrated that adaptive computation budgets can improve performance on tasks where transformers fall short. Many of these works achieve adaptivity by using dynamic depth to allocate the computation budget. For example, the Adaptive Computation Time (ACT) algorithm was proposed to provide an adaptive computational budget for recurrent neural networks. The Universal Transformer extends the ACT algorithm to transformers by making the computation budget dependent on the number of transformer layers used for each input example or token. Recent studies, like PonderNet, follow a similar approach while improving the dynamic halting mechanisms.
In the paper “Adaptive Computation with Elastic Input Sequence”, we introduce a new model that utilizes adaptive computation, called AdaTape. This model is a Transformer-based architecture that uses a dynamic set of tokens to create elastic input sequences, providing a unique perspective on adaptivity in comparison to previous works. AdaTape uses an adaptive tape reading mechanism to determine a varying number of tape tokens that are added to each input based on input’s complexity. AdaTape is very simple to implement, provides an effective knob to increase the accuracy when needed, but is also much more efficient compared to other adaptive baselines because it directly injects adaptivity into the input sequence instead of the model depth. Finally, Adatape offers better performance on standard tasks, like image classification, as well as algorithmic tasks, while maintaining a favorable quality and cost tradeoff.
Adaptive computation transformer with elastic input sequence
AdaTape uses both the adaptive function types and a dynamic computation budget. Specifically, for a batch of input sequences after tokenization (e.g., a linear projection of non-overlapping patches from an image in the vision transformer), AdaTape uses a vector representing each input to dynamically select a variable-sized sequence of tape tokens.
AdaTape uses a bank of tokens, called a “tape bank”, to store all the candidate tape tokens that interact with the model through the adaptive tape reading mechanism. We explore two different methods for creating the tape bank: an input-driven bank and a learnable bank.
The general idea of the input-driven bank is to extract a bank of tokens from the input while employing a different approach than the original model tokenizer for mapping the raw input to a sequence of input tokens. This enables dynamic, on-demand access to information from the input that is obtained using a different point of view, e.g., a different image resolution or a different level of abstraction.
In some cases, tokenization in a different level of abstraction is not possible, thus an input-driven tape bank is not feasible, such as when it's difficult to further split each node in a graph transformer. To address this issue, AdaTape offers a more general approach for generating the tape bank by using a set of trainable vectors as tape tokens. This approach is referred to as the learnable bank and can be viewed as an embedding layer where the model can dynamically retrieve tokens based on the complexity of the input example. The learnable bank enables AdaTape to generate a more flexible tape bank, providing it with the ability to dynamically adjust its computation budget based on the complexity of each input example, e.g., more complex examples retrieve more tokens from the bank, which let the model not only use the knowledge stored in the bank, but also spend more FLOPs processing it, since the input is now larger.
Finally, the selected tape tokens are appended to the original input and fed to the following transformer layers. For each transformer layer, the same multi-head attention is used across all input and tape tokens. However, two different feed-forward networks (FFN) are used: one for all tokens from the original input and the other for all tape tokens. We observed slightly better quality by using separate feed-forward networks for input and tape tokens.
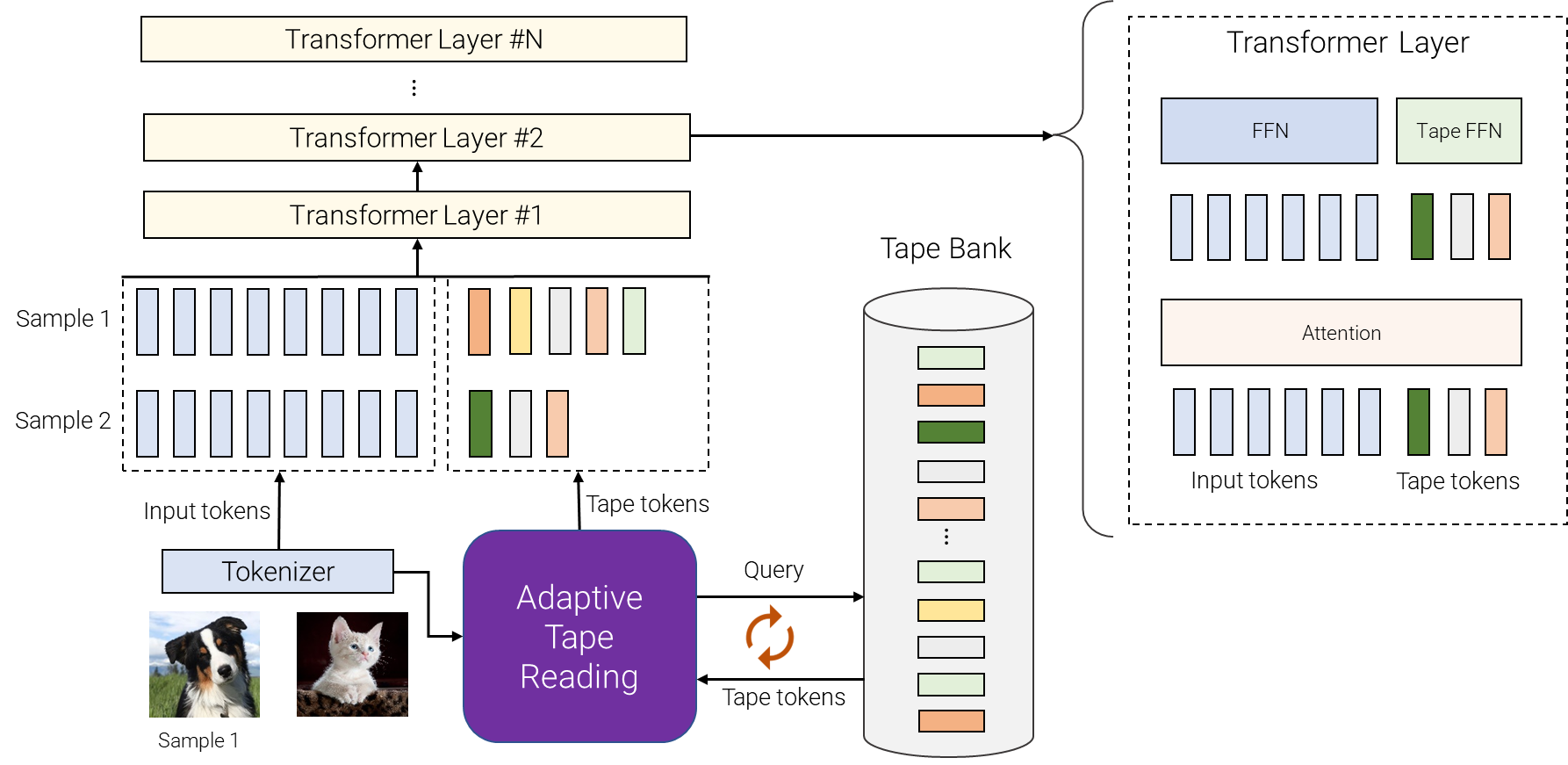 |
| An overview of AdaTape. For different samples, we pick a variable number of different tokens from the tape bank. The tape bank can be driven from input, e.g., by extracting some extra fine-grained information or it can be a set of trainable vectors. Adaptive tape reading is used to recursively select different sequences of tape tokens, with variable lengths, for different inputs. These tokens are then simply appended to inputs and fed to the transformer encoder. |
AdaTape provides helpful inductive bias
We evaluate AdaTape on parity, a very challenging task for the standard Transformer, to study the effect of inductive biases in AdaTape. With the parity task, given a sequence 1s, 0s, and -1s, the model has to predict the evenness or oddness of the number of 1s in the sequence. Parity is the simplest non-counter-free or periodic regular language, but perhaps surprisingly, the task is unsolvable by the standard Transformer.
 |
| Evaluation on the parity task. The standard Transformer and Universal Transformer were unable to perform this task, both showing performance at the level of a random guessing baseline. |
Despite being evaluated on short, simple sequences, both the standard Transformer and Universal Transformers were unable to perform the parity task as they are unable to maintain a counter within the model. However, AdaTape outperforms all baselines, as it incorporates a lightweight recurrence within its input selection mechanism, providing an inductive bias that enables the implicit maintenance of a counter, which is not possible in standard Transformers.
Evaluation on image classification
We also evaluate AdaTape on the image classification task. To do so, we trained AdaTape on ImageNet-1K from scratch. The figure below shows the accuracy of AdaTape and the baseline methods, including A-ViT, and the Universal Transformer ViT (UViT and U2T) versus their speed (measured as number of images, processed by each code, per second). In terms of quality and cost tradeoff, AdaTape performs much better than the alternative adaptive transformer baselines. In terms of efficiency, larger AdaTape models (in terms of parameter count) are faster than smaller baselines. Such results are consistent with the finding from previous work that shows that the adaptive model depth architectures are not well suited for many accelerators, like the TPU.
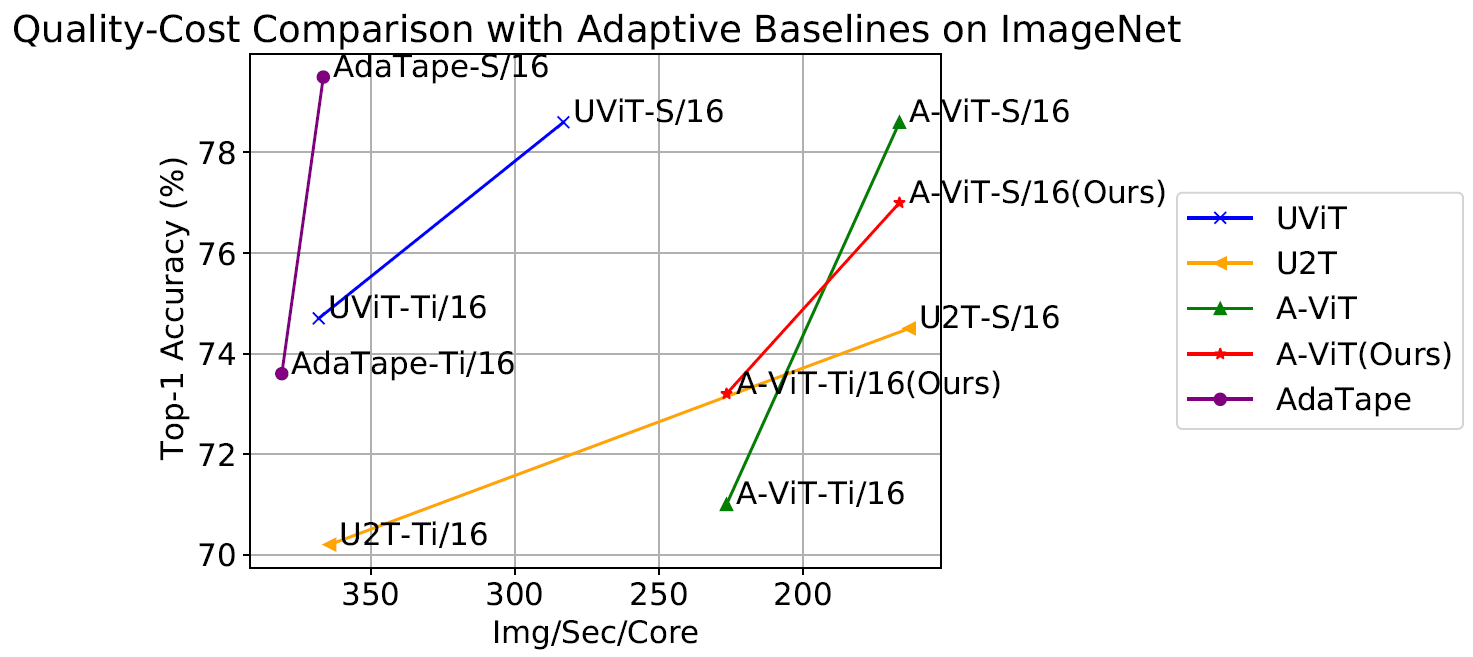 |
| We evaluate AdaTape by training on ImageNet from scratch. For A-ViT, we not only report their results from the paper but also re-implement A-ViT by training from scratch, i.e., A-ViT(Ours). |
A study of AdaTape’s behavior
In addition to its performance on the parity task and ImageNet-1K, we also evaluated the token selection behavior of AdaTape with an input-driven bank on the JFT-300M validation set. To better understand the model's behavior, we visualized the token selection results on the input-driven bank as heatmaps, where lighter colors mean that position is more frequently selected. The heatmaps reveal that AdaTape more frequently picks the central patches. This aligns with our prior knowledge, as central patches are typically more informative — especially in the context of datasets with natural images, where the main object is in the middle of the image. This result highlights the intelligence of AdaTape, as it can effectively identify and prioritize more informative patches to improve its performance.
 |
| We visualize the tape token selection heatmap of AdaTape-B/32 (left) and AdaTape-B/16 (right). The hotter / lighter color means the patch at this position is more frequently selected. |
Conclusion
AdaTape is characterized by elastic sequence lengths generated by the adaptive tape reading mechanism. This also introduces a new inductive bias that enables AdaTape to have the potential to solve tasks that are challenging for both standard transformers and existing adaptive transformers. By conducting comprehensive experiments on image recognition benchmarks, we demonstrate that AdaTape outperforms standard transformers and adaptive architecture transformers when computation is held constant.
Acknowledgments
One of the authors of this post, Mostafa Dehghani, is now at Google DeepMind.


.gif)
.gif)