Posted by Matt Harvey, Software Engineer, Google AI PerceptionOver the last several years,
Google AI Perception teams have developed techniques for audio event analysis that have been applied on YouTube for
non-speech captions, video categorizations, and indexing. Furthermore, we have published the
AudioSet evaluation set and open-sourced some
model code in order to further spur research in the community. Recently, we’ve become increasingly aware that many conservation organizations were collecting large quantities of acoustic data, and wondered whether it might be possible to apply these same technologies to that data in order to assist wildlife monitoring and conservation.
As part of our
AI for Social Good program, and in partnership with the
Pacific Islands Fisheries Science Center of the U.S.
National Oceanic and Atmospheric Administration (NOAA), we developed algorithms to identify
humpback whale calls in 15 years of underwater recordings from a number of locations in the Pacific. The results of this research provide new and important information about humpback whale presence, seasonality, daily calling behavior, and population structure. This is especially important in remote, uninhabited islands, about which scientists have had no information until now. Additionally, because the dataset spans a large period of time, knowing when and where humpback whales are calling will provide information on whether or not the animals have changed their distribution over the years, especially in relation to increasing human ocean activity. That information will be a key ingredient for effective mitigation of anthropogenic impacts on humpback whales.
 |
| HARP deployment locations. Green: sites with currently active recorders. Red: previous recording sites. |
Passive Acoustic Monitoring and the NOAA HARP DatasetPassive acoustic monitoring is the process of listening to marine mammals with underwater microphones called
hydrophones, which can be used to record signals so that detection, classification, and localization tasks can be done offline. This has some advantages over ship-based visual surveys, including the ability to detect submerged animals, longer detection ranges and longer monitoring periods. Since 2005, NOAA has collected recordings from ocean-bottom hydrophones at 12 sites in the Pacific Island region, a winter breeding and calving destination for certain populations of humpback whales.
The data was recorded on devices called high-frequency acoustic recording packages, or HARPs (
Wiggins and Hildebrand, 2007;
full text PDF). In total, NOAA provided about 15 years of audio, or 9.2 terabytes after
decimation from 200 kHz to 10kHz. (Since most of the sound energy in humpback vocalizations is in the 100Hz-2000Hz range, little is lost in using the lower sample rate.)
From a research perspective, identifying species of interest in such large volumes of data is an important first stage that provides input for higher-level population abundance, behavioral or oceanographic analyses. However,
manually marking humpback whale calls, even with the aid of currently available computer-assisted methods, is extremely time-consuming.
Supervised Learning: Optimizing an Image Model for Humpback DetectionWe made the common choice of treating audio event detection as an image classification problem, where the image is a
spectrogram — a histogram of sound power plotted on time-frequency axes.
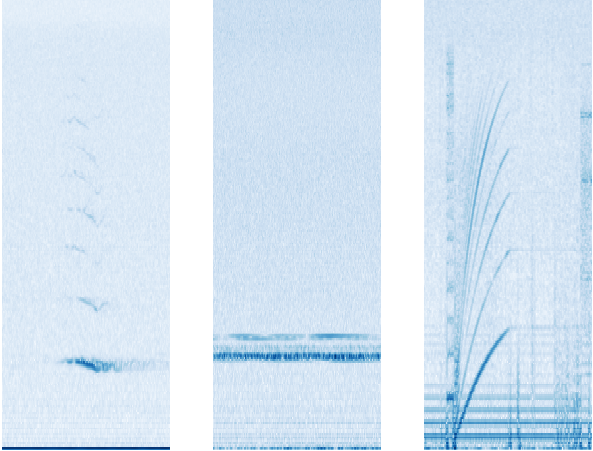 |
| Example spectrograms of audio events found in the dataset, with time on the x-axis and frequency on the y-axis. Left: a humpback whale call (in particular, a tonal unit), Center: narrow-band noise from an unknown source, Right: hard disk noise from the HARP |
This is a good representation for an image classifier, whose goal is to discriminate, because the different spectra (frequency decompositions) and time variations thereof (which are characteristic of distinct sound types) are represented in the spectrogram as visually dissimilar patterns. For the image model itself, we used
ResNet-50, a convolutional neural network architecture typically used for image classification that has shown
success at classifying non-speech audio. This is a
supervised learning setup, where only manually labeled data could be used for training (0.2% of the entire dataset — in the next section, we describe an approach that makes use of the unlabeled data.)
The process of going from waveform to spectrogram involves choices of parameters and gain-scaling functions. Common default choices (one of which was logarithmic compression) were a good starting point, but some domain-specific tuning was needed to optimize the detection of whale calls. Humpback vocalizations are varied, but sustained,
frequency-modulated,
tonal units occur frequently in time. You can listen to an example below:
If the frequency didn't vary at all, a tonal unit would appear in the spectrogram as a horizontal bar. Since the calls are frequency-modulated, we actually see arcs instead of bars, but parts of the arcs are close to horizontal.
A challenge particular to this dataset was narrow-band noise, most often caused by nearby boats and the equipment itself. In a spectrogram it appears as horizontal lines, and early versions of the model would confuse it with humpback calls. This motivated us to try
per-channel energy normalization (PCEN), which allows the suppression of stationary, narrow-band noise. This proved to be critical, providing a 24% reduction in error rate of whale call detection.
 |
| Spectrograms of the same 5-unit excerpt from humpback whale song beginning at 0:06 in the above recording. Top: PCEN. Bottom: log of squared magnitude. The dark blue horizontal bar along the bottom under log compression has become much lighter relative to the whale call when using PCEN |
Aside from PCEN, averaging predictions over a longer period of time led to much better precision. This same effect happens for general audio event detection, but for humpback calls the increase in precision was surprisingly large. A likely explanation is that the vocalizations in our dataset are mainly in the context of
whale song, a structured sequence of units than can last over 20 minutes. At the end of one unit in a song, there is a good chance another unit begins within two seconds. The input to the image model covers a short time window, but because the song is so long, model outputs from more distant time windows give extra information useful for making the correct prediction for the current time window.
Overall, evaluating on our test set of 75-second audio clips, the model identifies whether a clip contains humpback calls at over 90% precision and 90% recall. However, one should interpret these results with care; training and test data come from similar equipment and environmental conditions. That said, preliminary checks against some non-NOAA sources look promising.
Unsupervised Learning: Representation for Finding Similar Song UnitsA different way to approach the question, "
Where are all the humpback sounds in this data?", is to start with several examples of humpback sound and, for each of these, find more in the dataset that are similar to that example. The definition of
similar here can be learned by the same ResNet we used when this was framed as a supervised problem. There, we used the labels to learn a classifier on top of the ResNet output. Here, we encourage a pair of ResNet output vectors to be close in Euclidean distance when the corresponding audio examples are close in time. With that distance function, we can retrieve many more examples of audio similar to a given one. In the future, this may be useful input for a classifier that distinguishes different humpback unit types from each other.
To learn the distance function, we used a method described in "
Unsupervised Learning of Semantic Audio Representations", based on the idea that closeness in time is related to closeness in meaning. It randomly samples triplets, where each triplet is defined to consist of an
anchor, a
positive, and a
negative. The positive and the anchor are sampled so that they start around the same time. An example of a triplet in our application would be a humpback unit (anchor), a probable repeat of the same unit by the same whale (positive) and background noise from some other month (negative). Passing the 3 samples through the ResNet (with tied weights) represents them as 3 vectors. Minimizing a loss that forces the anchor-negative distance to exceed the anchor-positive distance by a margin learns a distance function faithful to semantic similarity.
Principal component analysis (PCA) on a sample of labeled points lets us visualize the results. Separation between humpback and non-humpback is apparent. Explore for yourself using the
TensorFlow Embedding Projector. Try changing
Color by to each of
class_label and
site. Also, try changing PCA to
t-SNE in the projector for a visualization that prioritizes preserving relative distances rather than sample variance.
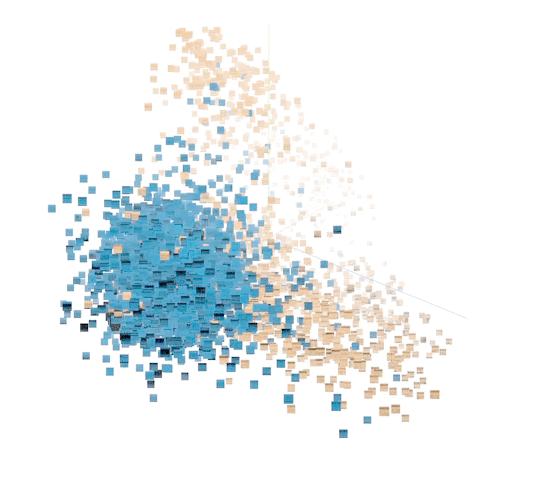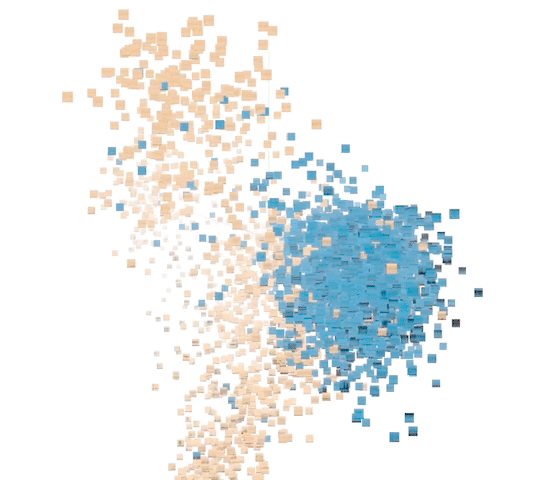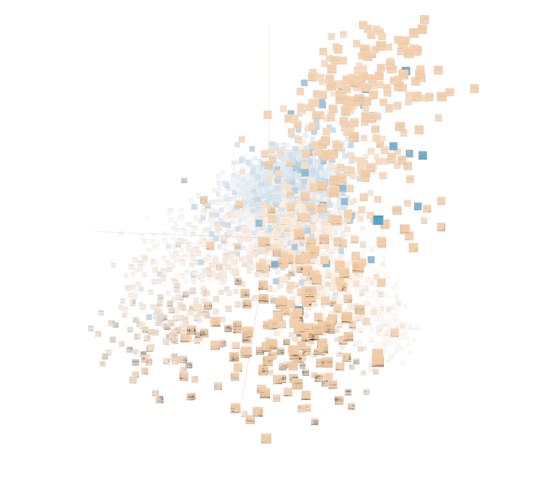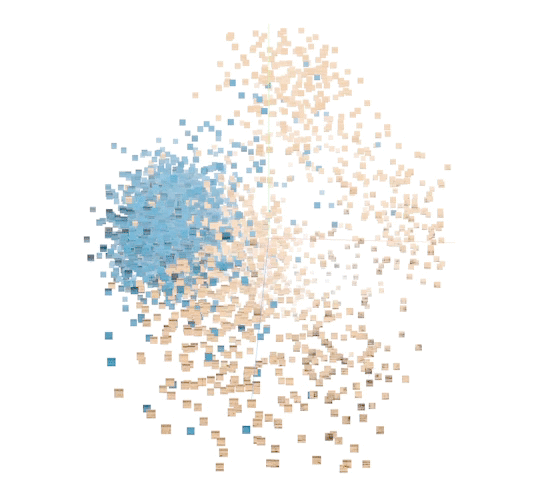 |
| A sample of 5000 data points in the unsupervised representation. (Orange: humpback. Blue: not humpback.) |
Given individual "query" units, we retrieved the nearest neighbors in the entire corpus using Euclidean distance between embedding vectors. In some cases we found hundreds more instances of the same unit with good precision.
 |
| Manually chosen query units (boxed) and nearest neighbors using the unsupervised representation. |
We intend to use these in the future to build a training set for a classifier that discriminates between song units. We could also use them to expand the training set used for learning a humpback detector.
Predictions from the Supervised Classifier on the Entire DatasetWe plotted summaries of the model output grouped by time and location. Not all sites had deployments in all years.
Duty cycling (example: 5 minutes on, 15 minutes off) allows longer deployments on limited battery power, but the schedule can vary. To deal with these sources of variability, we consider the proportion of sampled time in which humpback calling was detected to the total time recorded in a month:
 |
| Time density of presence on year / month axes for the Kona and Saipan sites. |
The apparent seasonal variation is consistent with a known pattern in which humpback populations spend summers feeding near Alaska and then migrate to the vicinity of the Hawaiian Islands to breed and give birth. This is a nice sanity check for the model.
We hope the predictions for the full dataset will equip experts at NOAA to reach deeper insights into the status of these populations and into the degree of any anthropogenic impacts on them. We also hope this is just one of the first few in a series of successes as Google works to accelerate the application of machine learning to the world's biggest humanitarian and environmental challenges.
AcknowledgementsWe would like to thank Ann Allen (NOAA Fisheries) for providing the bulk of the ground truth data, for many useful rounds of feedback, and for some of the words in this post. Karlina Merkens (NOAA affiliate) provided further useful guidance. We also thank the NOAA Pacific Islands Fisheries Science Center as a whole for collecting and sharing the acoustic data.
Within Google, Jiayang Liu, Julie Cattiau, Aren Jansen, Rif A. Saurous, and Lauren Harrell contributed to this work. Special thanks go to Lauren, who designed the plots in the analysis section and implemented them using ggplot.