Worldwide bird populations are declining at an alarming rate, with approximately 48% of existing bird species known or suspected to be experiencing population declines. For instance, the U.S. and Canada have reported 29% fewer birds since 1970.
Effective monitoring of bird populations is essential for the development of solutions that promote conservation. Monitoring allows researchers to better understand the severity of the problem for specific bird populations and evaluate whether existing interventions are working. To scale monitoring, bird researchers have started analyzing ecosystems remotely using bird sound recordings instead of physically in-person via passive acoustic monitoring. Researchers can gather thousands of hours of audio with remote recording devices, and then use machine learning (ML) techniques to process the data. While this is an exciting development, existing ML models struggle with tropical ecosystem audio data due to higher bird species diversity and overlapping bird sounds.
Annotated audio data is needed to understand model quality in the real world. However, creating high-quality annotated datasets — especially for areas with high biodiversity — can be expensive and tedious, often requiring tens of hours of expert analyst time to annotate a single hour of audio. Furthermore, existing annotated datasets are rare and cover only a small geographic region, such as Sapsucker Woods or the Peruvian rainforest. Thousands of unique ecosystems in the world still need to be analyzed.
In an effort to tackle this problem, over the past 3 years, we've hosted ML competitions on Kaggle in partnership with specialized organizations focused on high-impact ecologies. In each competition, participants are challenged with building ML models that can take sounds from an ecology-specific dataset and accurately identify bird species by sound. The best entries can train reliable classifiers with limited training data. Last year’s competition focused on Hawaiian bird species, which are some of the most endangered in the world.
The 2023 BirdCLEF ML competition
This year we partnered with The Cornell Lab of Ornithology's K. Lisa Yang Center for Conservation Bioacoustics and NATURAL STATE to host the 2023 BirdCLEF ML competition focused on Kenyan birds. The total prize pool is $50,000, the entry deadline is May 17, 2023, and the final submission deadline is May 24, 2023. See the competition website for detailed information on the dataset to be used, timelines, and rules.
Kenya is home to over 1,000 species of birds, covering a wide range of ecosystems, from the savannahs of the Maasai Mara to the Kakamega rainforest, and even alpine regions on Kilimanjaro and Mount Kenya. Tracking this vast number of species with ML can be challenging, especially with minimal training data available for many species.
NATURAL STATE is working in pilot areas around Northern Mount Kenya to test the effect of various management regimes and states of degradation on bird biodiversity in rangeland systems. By using the ML algorithms developed within the scope of this competition, NATURAL STATE will be able to demonstrate the efficacy of this approach in measuring the success and cost-effectiveness of restoration projects. In addition, the ability to cost-effectively monitor the impact of restoration efforts on biodiversity will allow NATURAL STATE to test and build some of the first biodiversity-focused financial mechanisms to channel much-needed investment into the restoration and protection of this landscape upon which so many people depend. These tools are necessary to scale this cost-effectively beyond the project area and achieve their vision of restoring and protecting the planet at scale.
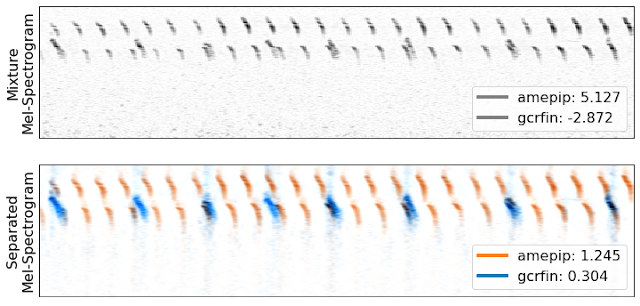
In previous competitions, we used metrics like the F1 score, which requires choosing specific detection thresholds for the models. This requires significant effort, and makes it difficult to assess the underlying model quality: A bad thresholding strategy on a good model may underperform. This year we are using a threshold-free model quality metric: class mean average precision. This metric treats each bird species output as a separate binary classifier to compute an average AUC score for each, and then averages these scores. Switching to an uncalibrated metric should increase the focus on core model quality by removing the need to choose a specific detection threshold.
How to get started
This will be the first Kaggle competition where participants can use the recently launched Kaggle Models platform that provides access to over 2,300 public, pre-trained models, including most of the TensorFlow Hub models. This new resource will have deep integrations with the rest of Kaggle, including Kaggle notebook, datasets, and competitions.
If you are interested in participating in this competition, a great place to get started quickly is to use our recently open-sourced Bird Vocalization Classifier model that is available on Kaggle Models. This global bird embedding and classification model provides output logits for more than 10k bird species and also creates embedding vectors that can be used for other tasks. Follow the steps shown in the figure below to use the Bird Vocalization Classifier model on Kaggle.
 |
| To try the model on Kaggle, navigate to the model here. 1) Click “New Notebook”; 2) click on the "Copy Code" button to copy the example lines of code needed to load the model; 3) click on the "Add Model" button to add this model as a data source to your notebook; and 4) paste the example code in the editor to load the model. |
Alternatively, the competition starter notebook includes the model and extra code to more easily generate a competition submission.
We invite the research community to consider participating in the BirdCLEF competition. As a result of this effort, we hope that it will be easier for researchers and conservation practitioners to survey bird population trends and build effective conservation strategies.
Acknowledgements
Compiling these extensive datasets was a major undertaking, and we are very thankful to the many domain experts who helped to collect and manually annotate the data for this competition. Specifically, we would like to thank (institutions and individual contributors in alphabetic order): Julie Cattiau and Tom Denton on the Brain team, Maximilian Eibl and Stefan Kahl at Chemnitz University of Technology, Stefan Kahl and Holger Klinck from the K. Lisa Yang Center for Conservation Bioacoustics at the Cornell Lab of Ornithology, Alexis Joly and Henning Müller at LifeCLEF, Jonathan Baillie from NATURAL STATE, Hendrik Reers, Alain Jacot and Francis Cherutich from OekoFor GbR, and Willem-Pier Vellinga from xeno-canto. We would also like to thank Ian Davies from the Cornell Lab of Ornithology for allowing us to use the hero image in this post.