Posted by Ankur Bapna, Software Engineer and Orhan Firat, Research Scientist, Google Research “... perhaps the way [of translation] is to descend, from each language, down to the common base of human communication — the real but as yet undiscovered universal language — and then re-emerge by whatever particular route is convenient.” —
Warren Weaver, 1949
Over the last few years there has been enormous progress in the quality of machine translation (MT) systems, breaking language barriers around the world thanks to the developments in
neural machine translation (NMT). The success of NMT however, owes largely to the great amounts of supervised training data. But what about languages where data is scarce, or even absent? Multilingual NMT, with the inductive bias that “
the learning signal from one language should benefit the quality of translation to other languages”, is a potential remedy.
Multilingual machine translation processes multiple languages using a single translation model. The success of multilingual training for data-scarce languages has been demonstrated for
automatic speech recognition and
text-to-speech systems, and by prior research on multilingual translation [
1,
2,
3]. We previously studied the effect of
scaling up the number of languages that can be learned in a single neural network, while controlling the amount of training data per language. But what happens once all constraints are removed? Can we train a single model using all of the available data, despite the huge differences across languages in data size, scripts, complexity and domains?
In “
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges” and follow-up papers [
4,
5,
6,
7], we push the limits of research on multilingual NMT by training a single NMT model on 25+ billion sentence pairs, from 100+ languages to and from English, with 50+ billion parameters. The result is an approach for massively multilingual, massive neural machine translation (M4) that demonstrates large quality improvements on both low- and high-resource languages and can be easily adapted to individual domains/languages, while showing great efficacy on cross-lingual downstream transfer tasks.
Massively Multilingual Machine TranslationThough data skew across language-pairs is a
great challenge in NMT, it also creates an ideal scenario in which to study
transfer, where insights gained through training on one language can be applied to the translation of other languages. On one end of the distribution, there are high-resource languages like French, German and Spanish where there are billions of parallel examples, while on the other end, supervised data for low-resource languages such as Yoruba, Sindhi and Hawaiian, is limited to a few tens of thousands.
 |
| The data distribution over all language pairs (in log scale) and the relative translation quality (BLEU score) of the bilingual baselines trained on each one of these specific language pairs. |
Once trained using all of the available data (25+ billion examples from 103 languages), we observe strong
positive transfer towards low-resource languages, dramatically improving the translation quality of 30+ languages at the tail of the distribution by an average of 5
BLEU points. This effect is
already known, but surprisingly encouraging, considering the comparison is between bilingual baselines (i.e., models trained only on specific language pairs) and a single multilingual model with
representational capacity similar to a single bilingual model. This finding hints that massively multilingual models are effective at generalization, and capable of capturing the representational similarity across a large body of languages.
 |
| Translation quality comparison of a single massively multilingual model against bilingual baselines that are trained for each one of the 103 language pairs. |
In our EMNLP’19 paper [
5], we compare the representations of multilingual models across different languages. We find that multilingual models learn shared representations for
linguistically similar languages without the need for external constraints, validating
long-standing intuitions and empirical results that
exploit these similarities. In [
6], we further demonstrate the effectiveness of these learned representations on cross-lingual transfer on downstream tasks.
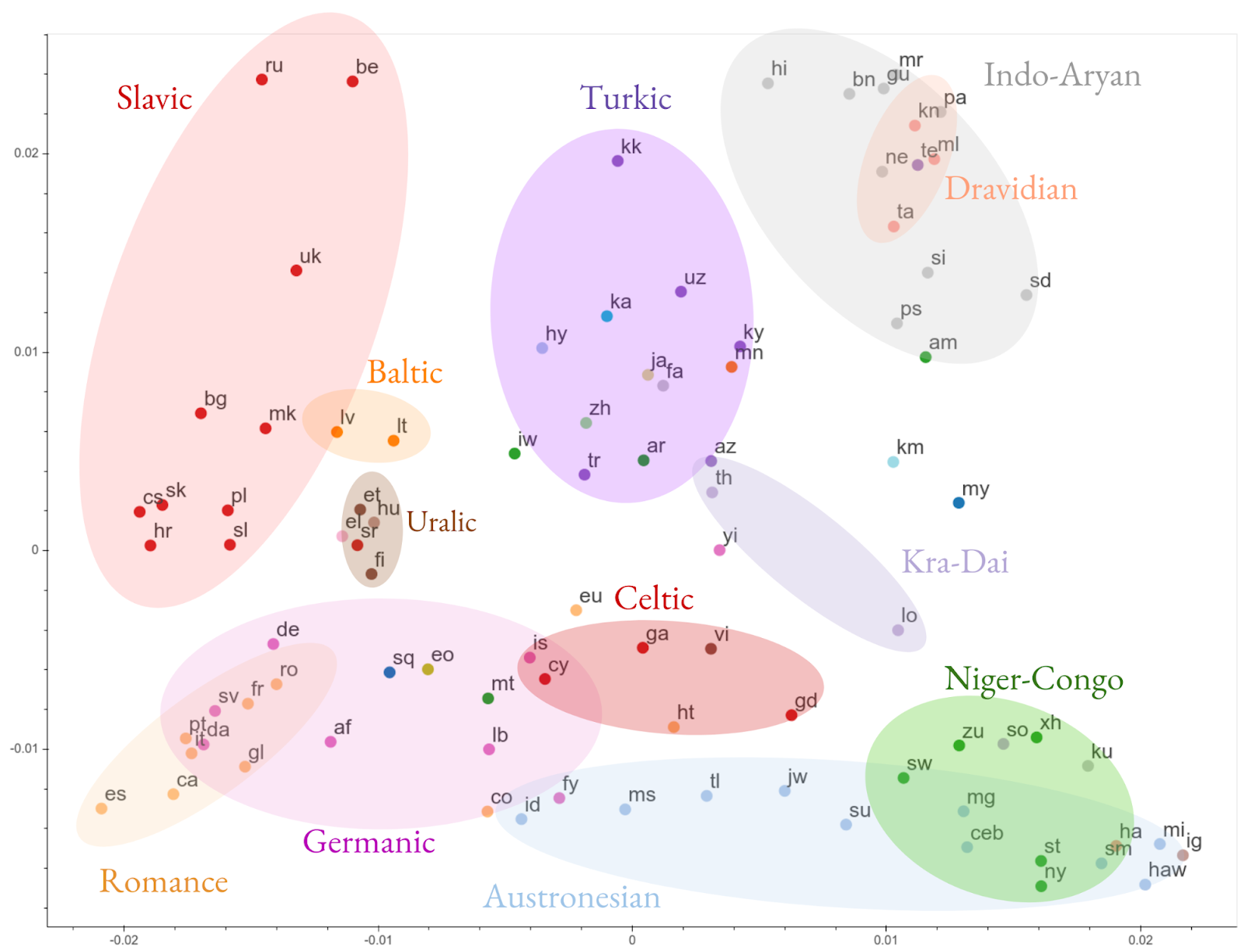
 |
| Visualization of the clustering of the encoded representations of all 103 languages, based on representational similarity. Languages are color-coded by their linguistic family. |
Building Massive Neural NetworksAs we increase the number of low-resource languages in the model, the quality of high-resource language translations starts to decline. This regression is
recognized in multi-task setups, arising from inter-task competition and the unidirectional nature of transfer (i.e., from high- to low-resource)
. While working on
better learning and
capacity control algorithms to mitigate this
negative transfer, we also extend the representational capacity of our neural networks by making them bigger by increasing the number of model parameters to improve the quality of translation for high-resource languages.
Numerous design choices can be made to scale neural network capacity, including adding more layers or making the hidden representations wider. Continuing
our study on training deeper networks for translation, we utilized
GPipe [
4] to train 128-layer
Transformers with over 6 billion parameters. Increasing the model capacity resulted in significantly improved performance across all languages by an average of 5
BLEU points. We also studied other properties of very deep networks, including the
depth-width trade-off, trainability challenges and design choices for scaling Transformers to over 1500 layers with 84 billion parameters.
While scaling depth is one approach to increasing model capacity, exploring architectures that can exploit the multi-task nature of the problem is a very plausible complementary way forward. By modifying the Transformer architecture through the substitution of the vanilla feed-forward layers with
sparsely-gated mixture of experts, we drastically scale up the model capacity, allowing us to successfully train and pass 50 billion parameters, which further improved translation quality across the board.
 |
| Translation quality improvement of a single massively multilingual model as we increase the capacity (number of parameters) compared to 103 individual bilingual baselines. |
Making M4 PracticalIt is inefficient to train large models with extremely high computational costs for every individual language, domain or transfer task. Instead, we present methods [
7] to make these models more practical by using capacity tunable layers to adapt a new model to specific languages or domains, without altering the original.
Next StepsAt least half of the 7,000 languages currently spoken will no longer exist by the end of this century
*. Can multilingual machine translation come to the rescue? We see the M4 approach as a stepping stone towards serving the next 1,000 languages; starting from such multilingual models will allow us to easily extend to new languages, domains and down-stream tasks, even when parallel data is unavailable. Indeed the path is rocky, and on the road to universal MT many promising solutions appear to be interdisciplinary. This makes multilingual NMT a plausible test bed for machine learning practitioners and theoreticians interested in exploring the annals of multi-task learning, meta-learning, training dynamics of deep nets and much more. We still have a long way to go.
Acknowledgements This effort is built on contributions from Naveen Arivazhagan, Dmitry Lepikhin, Melvin Johnson, Maxim Krikun, Mia Chen, Yuan Cao, Yanping Huang, Sneha Kudugunta, Isaac Caswell, Aditya Siddhant, Wei Wang, Roee Aharoni, Sébastien Jean, George Foster, Colin Cherry, Wolfgang Macherey, Zhifeng Chen and Yonghui Wu. We would also like to acknowledge support from the Google Translate, Brain, and Lingvo development teams, Jakob Uszkoreit, Noam Shazeer, Hyouk Joong Lee, Dehao Chen, Youlong Cheng, David Grangier, Colin Raffel, Katherine Lee, Thang Luong, Geoffrey Hinton, Manisha Jain, Pendar Yousefi and Macduff Hughes.
* The Cambridge Handbook of Endangered Languages (Austin and Sallabank, 2011). ↩








 Posted by Takuo Suzuki
Posted by Takuo Suzuki  In 2016
In 2016  We are a small group of like minded developers living and working in Uganda. Most of our relatives grow maize so the impact of the worm was very close to home. We really felt like we needed to do something about it.
We are a small group of like minded developers living and working in Uganda. Most of our relatives grow maize so the impact of the worm was very close to home. We really felt like we needed to do something about it.  The vast damage and yield losses in maize production, due to FAW, got the attention of global organizations, who are calling for innovators to help. It is the perfect time to apply machine learning. Our goal is to build an intelligent agent to help local farmers fight this pest in order to increase our food security.
The vast damage and yield losses in maize production, due to FAW, got the attention of global organizations, who are calling for innovators to help. It is the perfect time to apply machine learning. Our goal is to build an intelligent agent to help local farmers fight this pest in order to increase our food security.  We started with about 3956 images, but our dataset is growing exponentially. We are actively collecting more and more data to improve our model’s accuracy. The improvements in TensorFlow, with Keras high level APIs, has really made our approach to deep learning easy and enjoyable and we are now experimenting with
We started with about 3956 images, but our dataset is growing exponentially. We are actively collecting more and more data to improve our model’s accuracy. The improvements in TensorFlow, with Keras high level APIs, has really made our approach to deep learning easy and enjoyable and we are now experimenting with 










 Posted by Vikram Tank (Product Manager), Coral Team
Posted by Vikram Tank (Product Manager), Coral Team