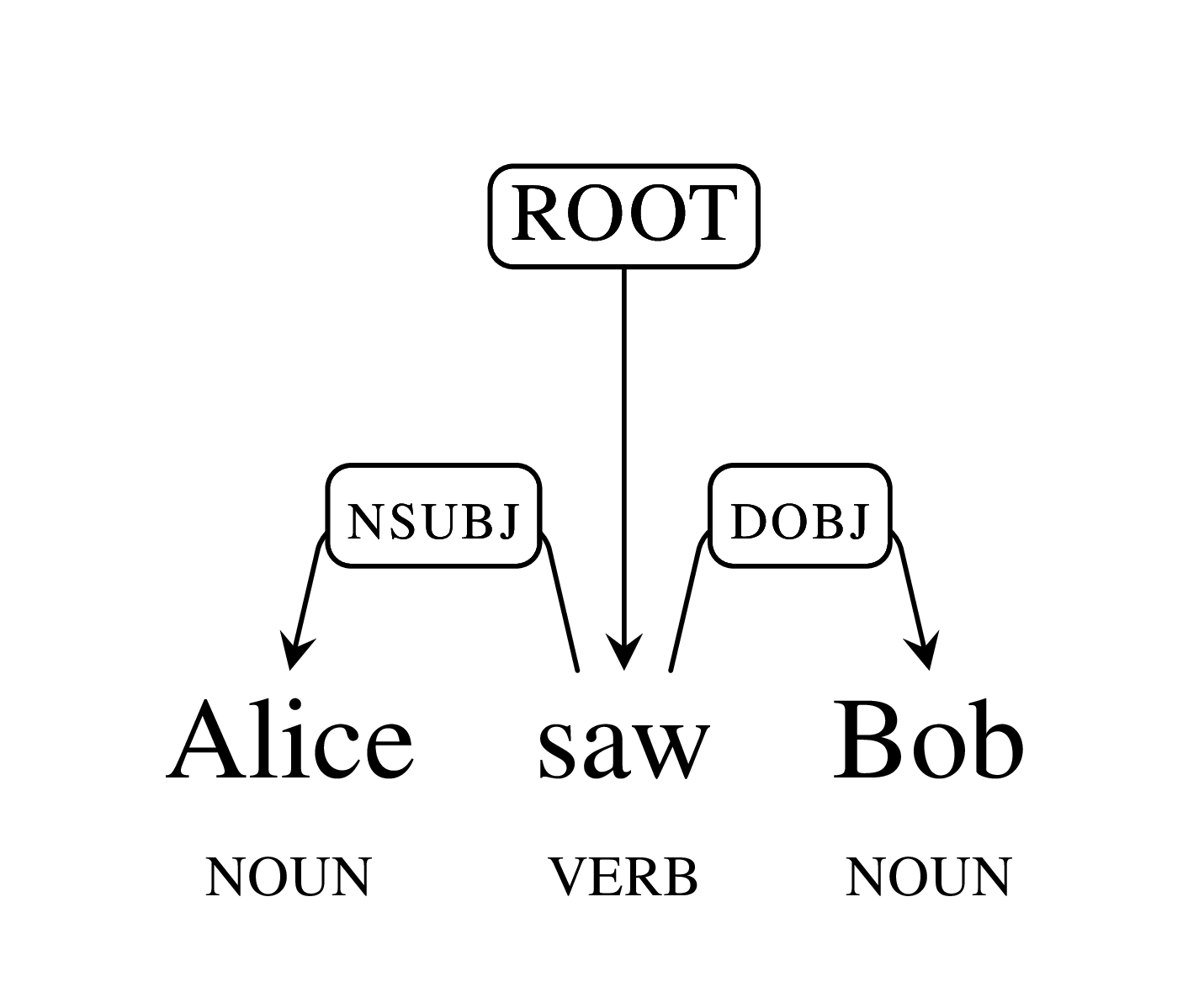
SyntaxNet Upgrade
We are releasing a major upgrade to SyntaxNet. This upgrade incorporates nearly a year’s worth of our research on multilingual language understanding, and is available to anyone interested in building systems for processing and understanding text. At the core of the upgrade is a new technology that enables learning of richly layered representations of input sentences. More specifically, the upgrade extends TensorFlow to allow joint modeling of multiple levels of linguistic structure, and to allow neural-network architectures to be created dynamically during processing of a sentence or document.
Our upgrade makes it, for example, easy to build character-based models that learn to compose individual characters into words (e.g. ‘c-a-t’ spells ‘cat’). By doing so, the models can learn that words can be related to each other because they share common parts (e.g. ‘cats’ is the plural of ‘cat’ and shares the same stem; ‘wildcat’ is a type of ‘cat’). Parsey and Parsey’s Cousins, on the other hand, operated over sequences of words. As a result, they were forced to memorize words seen during training and relied mostly on the context to determine the grammatical function of previously unseen words.
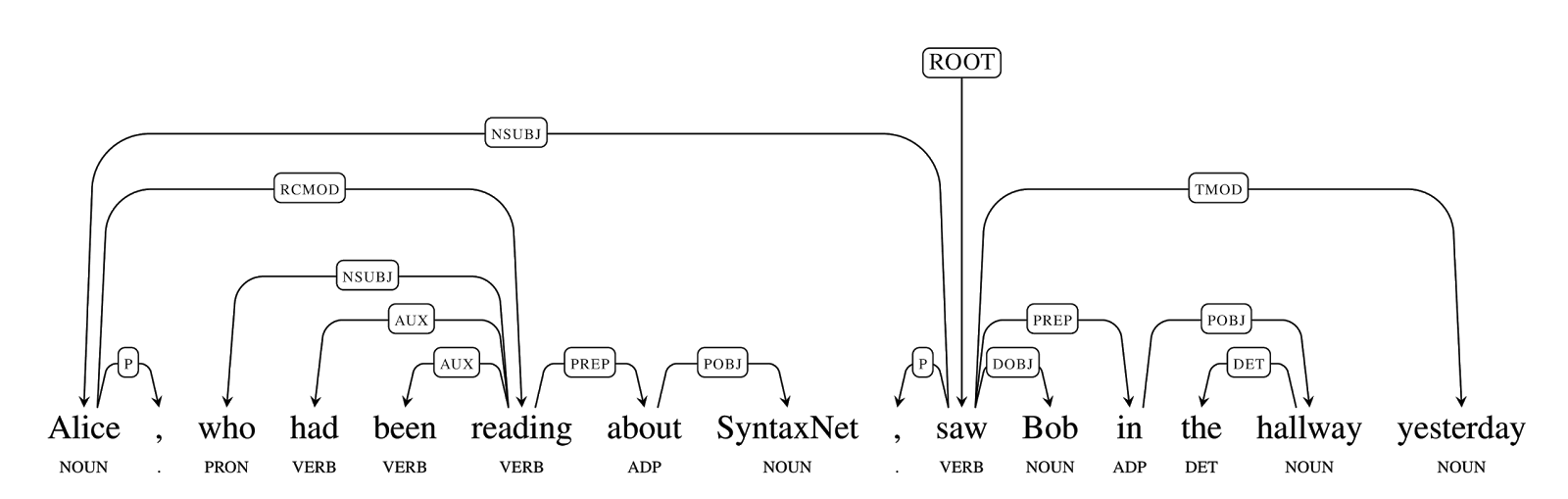
As an example, consider the following (meaningless but grammatically correct) sentence:

ParseySaurus
To showcase the new capabilities provided by our upgrade to SyntaxNet, we are releasing a set of new pretrained models called ParseySaurus. These models use the character-based input representation mentioned above and are thus much better at predicting the meaning of new words based both on their spelling and how they are used in context. The ParseySaurus models are far more accurate than Parsey’s Cousins (reducing errors by as much as 25%), particularly for morphologically-rich languages like Russian, or agglutinative languages like Turkish and Hungarian. In those languages there can be dozens of forms for each word and many of these forms might never be observed during training - even in a very large corpus.
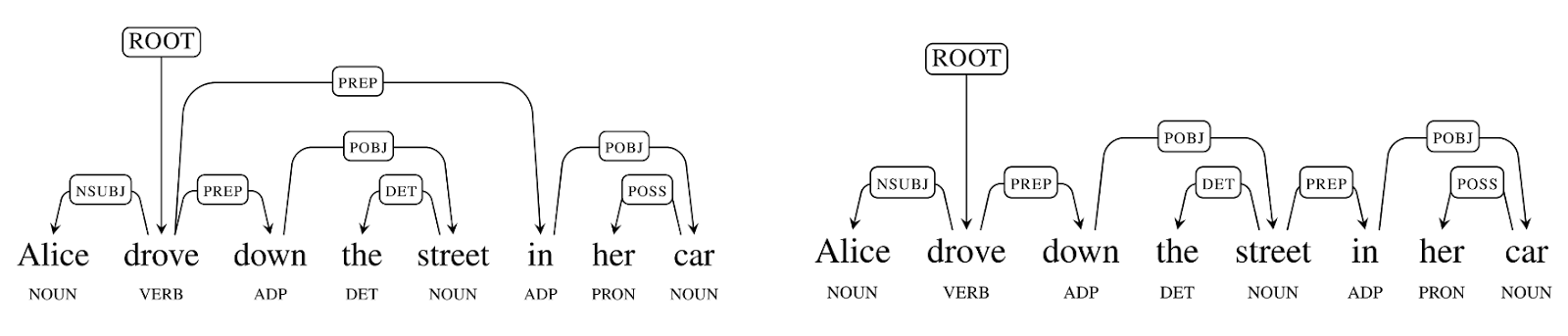
Consider the following fictitious Russian sentence, where again the stems are meaningless, but the suffixes define an unambiguous interpretation of the sentence structure:


A Competition
You might be wondering whether character-based modeling are all we need or whether there are other techniques that might be important. SyntaxNet has lots more to offer, like beam search and different training objectives, but there are of course also many other possibilities. To find out what works well in practice we are helping co-organize, together with Charles University and other colleagues, a multilingual parsing competition at this year’s Conference on Computational Natural Language Learning (CoNLL) with the goal of building syntactic parsing systems that work well in real-world settings and for 45 different languages.
The competition is made possible by the Universal Dependencies (UD) initiative, whose goal is to develop cross-linguistically consistent treebanks. Because machine learned models can only be as good as the data that they have access to, we have been contributing data to UD since 2013. For the competition, we partnered with UD and DFKI to build a new multilingual evaluation set consisting of 1000 sentences that have been translated into 20+ different languages and annotated by linguists with parse trees. This evaluation set is the first of its kind (in the past, each language had its own independent evaluation set) and will enable more consistent cross-lingual comparisons. Because the sentences have the same meaning and have been annotated according to the same guidelines, we will be able to get closer to answering the question of which languages might be harder to parse.
We hope that the upgraded SyntaxNet framework and our the pre-trained ParseySaurus models will inspire researchers to participate in the competition. We have additionally created a tutorial showing how to load a Docker image and train models on the Google Cloud Platform, to facilitate participation by smaller teams with limited resources. So, if you have an idea for making your own models with the SyntaxNet framework, sign up to compete! We believe that the configurations that we are releasing are a good place to start, but we look forward to seeing how participants will be able to extend and improve these models or perhaps create better ones!
Thanks to everyone involved who made this competition happen, including our collaborators at UD-Pipe, who provide another baseline implementation to make it easy to enter the competition. Happy parsing from the main developers, Chris Alberti, Daniel Andor, Ivan Bogatyy, Mark Omernick, Zora Tung and Ji Ma!
By David Weiss and Slav Petrov, Research Scientists

{kind=link}