In 2015, our early attempts to visualize how neural networks understand images led to psychedelic images. Soon after, we open sourced our code as DeepDream and it grew into a small art movement producing allsortsof amazing things. But we also continued the original line of research behind DeepDream, trying to address one of the most exciting questions in Deep Learning: how do neural networks do what they do?
Last year in the online journal Distill, we demonstrated how those same techniques could show what individual neurons in a network do, rather than just what is “interesting to the network” as in DeepDream. This allowed us to see how neurons in the middle of the network are detectors for all sorts of things — buttons, patches of cloth, buildings — and see how those build up to be more and more sophisticated over the networks layers.
Visualizations of neurons in GoogLeNet. Neurons in higher layers represent higher level ideas.
While visualizing neurons is exciting, our work last year was missing something important: how do these neurons actually connect to what the network does in practice?
Today, we’re excited to publish “The Building Blocks of Interpretability,” a new Distill article exploring how feature visualization can combine together with other interpretability techniques to understand aspects of how networks make decisions. We show that these combinations can allow us to sort of “stand in the middle of a neural network” and see some of the decisions being made at that point, and how they influence the final output. For example, we can see things like how a network detects a floppy ear, and then that increases the probability it gives to the image being a “Labrador retriever” or “beagle”.
We explore techniques for understanding which neurons fire in the network. Normally, if we ask which neurons fire, we get something meaningless like “neuron 538 fired a little bit,” which isn’t very helpful even to experts. Our techniques make things more meaningful to humans by attaching visualizations to each neuron, so we can see things like “the floppy ear detector fired”. It’s almost a kind of MRI for neural networks.
We can also zoom out and show how the entire image was “perceived” at different layers. This allows us to really see the transition from the network detecting very simple combinations of edges, to rich textures and 3d structure, to high-level structures like ears, snouts, heads and legs.
These insights are exciting by themselves, but they become even more exciting when we can relate them to the final decision the network makes. So not only can we see that the network detected a floppy ear, but we can also see how that increases the probability of the image being a labrador retriever.
In addition to our paper, we’re also releasing Lucid, a neural network visualization library building off our work on DeepDream. It allows you to make the sort lucid feature visualizations we see above, in addition to more artistic DeepDream images.
We’re also releasing colab notebooks. These notebooks make it extremely easy to use Lucid to reproduce visualizations in our article! Just open the notebook, click a button to run code — no setup required!
In colab notebooks you can click a button to run code, and see the result below.
This work only scratches the surface of the kind of interfaces that we think it’s possible to build for understanding neural networks. We’re excited to see what the community will do — and we’re excited to work together towards deeper human understanding of neural networks.
Posted by Patrik Sundberg, Software Engineer and Eyal Oren, Product Manager, Google Brain Team
Over the past 10 years, healthcare data has moved from being largely on paper to being almost completely digitized in electronic health records. But making sense of this data involves a few key challenges. First, there is no common data representation across vendors; each uses a different way to structure their data. Second, even sites that use the same vendor may differ significantly, for example, they typically use different codes for the same medication. Third, data can be spread over many tables, some containing encounters, some containing lab results, and yet others containing vital signs.
The Fast Healthcare Interoperability Resources (FHIR) standard addresses most of these challenges: it has a solid yet extensible data-model, is built on established Web standards, and is rapidly becoming the de-facto standard for both individual records and bulk-data access. But to enable large-scale machine learning, we needed a few additions: implementations in various programming languages, an efficient way to serialize large amounts of data to disk, and a representation that allows analyses of large datasets.
Today, we are happy to open source a protocol buffer implementation of the FHIR standard, which addresses these issues. The current version supports Java, and support for C++, Go, and Python will follow soon. Support for profiles will follow shortly as well, plus tools to help convert legacy data into FHIR.
FHIR as the core data model Over the past few years, as we’ve been partnering with academic medical centers to apply machine learning to de-identified medical records, it became clear that we needed to address the complexity of healthcare data head-on. Indeed, for machine learning to be effective on medical data, we need a holistic view of what happened to each patient over time. And as a bonus, we want a data representation that is directly applicable in a clinical setting.
While the FHIR standard addresses most of our needs, making healthcare data substantially easier to manage than “legacy” data structures and enabling large-scale machine-learning independent of vendors, we believe the introduction of protocol buffers can help both application developers and (machine-learning) researchers use FHIR.
Current release of protocol buffers We’ve taken care to make our protocol buffer representation suitable for both programmatic access and database queries. One of the provided examples shows how to upload FHIR data into Google Cloud BigQuery and have it available for querying, and we are adding other examples that upload directly from bulk data export. Our protocol buffers adhere to the FHIR standard (they are in fact auto-generated from it) but make for more elegant queries.
The current release does not yet include support for training TensorFlow models, but keep an eye out for future updates. We aim to open-source as much as possible of our recent work, to help make our research more reproducible and applicable to real-world scenarios. Furthermore, we are working closely with our colleagues in Google Cloud on more tools for managing healthcare data at scale.
Posted by Patrik Sundberg, Software Engineer and Eyal Oren, Product Manager, Google Brain Team
Over the past 10 years, healthcare data has moved from being largely on paper to being almost completely digitized in electronic health records. But making sense of this data involves a few key challenges. First, there is no common data representation across vendors; each uses a different way to structure their data. Second, even sites that use the same vendor may differ significantly, for example, they typically use different codes for the same medication. Third, data can be spread over many tables, some containing encounters, some containing lab results, and yet others containing vital signs.
The Fast Healthcare Interoperability Resources (FHIR) standard addresses most of these challenges: it has a solid yet extensible data-model, is built on established Web standards, and is rapidly becoming the de-facto standard for both individual records and bulk-data access. But to enable large-scale machine learning, we needed a few additions: implementations in various programming languages, an efficient way to serialize large amounts of data to disk, and a representation that allows analyses of large datasets.
Today, we are happy to open source a protocol buffer implementation of the FHIR standard, which addresses these issues. The current version supports Java, and support for C++, Go, and Python will follow soon. Support for profiles will follow shortly as well, plus tools to help convert legacy data into FHIR.
FHIR as the core data model Over the past few years, as we’ve been partnering with academic medical centers to apply machine learning to de-identified medical records, it became clear that we needed to address the complexity of healthcare data head-on. Indeed, for machine learning to be effective on medical data, we need a holistic view of what happened to each patient over time. And as a bonus, we want a data representation that is directly applicable in a clinical setting.
While the FHIR standard addresses most of our needs, making healthcare data substantially easier to manage than “legacy” data structures and enabling large-scale machine-learning independent of vendors, we believe the introduction of protocol buffers can help both application developers and (machine-learning) researchers use FHIR.
Current release of protocol buffers We’ve taken care to make our protocol buffer representation suitable for both programmatic access and database queries. One of the provided examples shows how to upload FHIR data into Google Cloud BigQuery and have it available for querying, and we are adding other examples that upload directly from bulk data export. Our protocol buffers adhere to the FHIR standard (they are in fact auto-generated from it) but make for more elegant queries.
The current release does not yet include support for training TensorFlow models, but keep an eye out for future updates. We aim to open-source as much as possible of our recent work, to help make our research more reproducible and applicable to real-world scenarios. Furthermore, we are working closely with our colleagues in Google Cloud on more tools for managing healthcare data at scale.
Posted by Lily Peng MD PhD, Product Manager, Google Brain Team
Heart attacks, strokes and other cardiovascular (CV) diseases continue to be among the top public health issues. Assessing this risk is critical first step toward reducing the likelihood that a patient suffers a CV event in the future. To do this assessment, doctors take into account a variety of risk factors — some genetic (like age and sex), some with lifestyle components (like smoking and blood pressure). While most of these factors can be obtained by simply asking the patient, others factors, like cholesterol, require a blood draw. Doctors also take into account whether or not a patient has another disease, such as diabetes, which is associated with significantly increased risk of CV events.
Recently, we’ve seen many examples [1–4] of how deep learning techniques can help to increase the accuracy of diagnoses for medical imaging, especially for diabetic eye disease. In “Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning,” published in Nature Biomedical Engineering, we show that in addition to detecting eye disease, images of the eye can very accurately predict other indicators of CV health. This discovery is particularly exciting because it suggests we might discover even more ways to diagnose health issues from retinal images.
Using deep learning algorithms trained on data from 284,335 patients, we were able to predict CV risk factors from retinal images with surprisingly high accuracy for patients from two independent datasets of 12,026 and 999 patients. For example, our algorithm could distinguish the retinal images of a smoker from that of a non-smoker 71% of the time. In addition, while doctors can typically distinguish between the retinal images of patients with severe high blood pressure and normal patients, our algorithm could go further to predict the systolic blood pressure within 11 mmHg on average for patients overall, including those with and without high blood pressure.
LEFT: image of the back of the eye showing the macula (dark spot in the middle), optic disc (bright spot at the right), and blood vessels (dark red lines arcing out from the bright spot on the right). RIGHT: retinal image in gray, with the pixels used by the deep learning algorithm to make predictions about the blood pressure highlighted in shades of green (heatmap). We found that each CV risk factor prediction uses a distinct pattern, such as blood vessels for blood pressure, and optic disc for other predictions.
In addition to predicting the various risk factors (age, gender, smoking, blood pressure, etc) from retinal images, our algorithm was fairly accurate at predicting the risk of a CV event directly. Our algorithm used the entire image to quantify the association between the image and the risk of heart attack or stroke. Given the retinal image of one patient who (up to 5 years) later experienced a major CV event (such as a heart attack) and the image of another patient who did not, our algorithm could pick out the patient who had the CV event 70% of the time. This performance approaches the accuracy of other CV risk calculators that require a blood draw to measure cholesterol.
More importantly, we opened the “black box” by using attention techniques to look at how the algorithm was making its prediction. These techniques allow us to generate a heatmap that shows which pixels were the most important for a predicting a specific CV risk factor. For example, the algorithm paid more attention to blood vessels for making predictions about blood pressure, as shown in the image above. Explaining how the algorithm is making its prediction gives doctor more confidence in the algorithm itself. In addition, this technique could help generate hypotheses for future scientific investigations into CV risk and the retina.
At the broadest level, we are excited about this work because it may represent a new method of scientific discovery. Traditionally, medical discoveries are often made through a sophisticated form of guess and test — making hypotheses from observations and then designing and running experiments to test the hypotheses. However, with medical images, observing and quantifying associations can be difficult because of the wide variety of features, patterns, colors, values and shapes that are present in real images. Our approach uses deep learning to draw connections between changes in the human anatomy and disease, akin to how doctors learn to associate signs and symptoms with the diagnosis of a new disease. This could help scientists generate more targeted hypotheses and drive a wide range of future research.
With these promising results, a lot of scientific work remains. Our dataset had many images labeled with smoking status, systolic blood pressure, age, gender and other variables, but it only had a few hundred examples of CV events. We look forward to developing and testing our algorithm on larger and more comprehensive datasets. To make this useful for patients, we will be seeking to understand the effects of interventions such as lifestyle changes or medications on our risk predictions and we will be generating new hypotheses and theories to test.
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain Team
The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. In Part 1 of this blog post, we shared some of our work in 2017 related to our broader research, from designing new machine learning algorithms and techniques to understanding them, as well as sharing data, software, and hardware with the community. In this post, we’ll dive into the research we do in some specific domains such as healthcare, robotics, creativity, fairness and inclusion, as well as share a little more about us.
We have continued our work on early detection of diabetic retinopathy (DR) and macular edema, building on the research paper we published December 2016 in the Journal of the American Medical Association (JAMA). In 2017, we moved this project from research project to actual clinical impact. We partnered with Verily (a life sciences company within Alphabet) to guide this work through the regulatory process, and together we are incorporating this technology into Nikon's line of Optos ophthalmology cameras. In addition, we are working to deploy this system in India, where there is a shortage of 127,000 eye doctors and as a result, almost half of patients are diagnosed too late — after the disease has already caused vision loss. As a part of a pilot, we’ve launched this system to help graders at Aravind Eye Hospitals to better diagnose diabetic eye disease. We are also working with our partners to understand the human factors affecting diabetic eye care, from ethnographic studies of patients and healthcare providers, to investigations on how eye care clinicians interact with the AI-enabled system.
First patient screened (top) and Iniya Paramasivam, a trained grader, viewing the output of the system (bottom).
We have also teamed up with researchers at leading healthcare organizations and medical centers including Stanford, UCSF, and University of Chicago to demonstrate the effectiveness of using machine learning to predict medical outcomes from de-identified medical records (i.e. given the current state of a patient, we believe we can predict the future for a patient by learning from millions of other patients’ journeys, as a way of helping healthcare professionals make better decisions). We’re very excited about this avenue of work and we look to forward to telling you more about it in 2018.
Robotics Our long-term goal in robotics is to design learning algorithms to allow robots to operate in messy, real-world environments and to quickly acquire new skills and capabilities via learning, rather than the carefully-controlled conditions and the small set of hand-programmed tasks that characterize today’s robots. One thrust of our research is on developing techniques for physical robots to use their own experience and those of other robots to build new skills and capabilities, pooling the shared experiences in order to learn collectively. We are also exploring ways in which we can combine computer-based simulations of robotic tasks with physical robotic experience to learn new tasks more rapidly. While the physics of the simulator don’t entirely match up with the real world, we have observed that for robotics, simulated experience plus a small amount of real-world experience gives significantly better results than even large amounts of real-world experience on its own.
In addition to real-world robotic experience and simulated robotic environments, we have developed robotic learning algorithms that can learn by observing human demonstrations of desired behaviors, and believe that this imitation learning approach is a highly promising way of imparting new abilities to robots very quickly, without explicit programming or even explicit specification of the goal of an activity. For example, below is a video of a robot learning to pour from a cup in just 15 minutes of real world experience by observing humans performing this task from different viewpoints and then trying to imitate the behavior. As we might be with our own three-year-old child, we’re encouraged that it only spills a little!
We also co-organized and hosted the first occurrence of the new Conference on Robot Learning (CoRL) in November to bring together researchers working at the intersection of machine learning and robotics. The summary of the event contains more information, and we look forward to next year’s occurrence of the conference in Zürich.
Creativity We’re very interested in how to leverage machine learning as a tool to assist people in creative endeavors. This year, we created an AI piano duet tool, helped YouTube musician Andrew Huang create new music (see also the behind the scenes video with Nat & Friends), and showed how to teach machines to draw.
We also demonstrated how to control deep generative models running in the browser to create new music. This work won the NIPS 2017 Best Demo Award, making this the second year in a row that members of the Brain team’s Magenta project have won this award, following on our receipt of the NIPS 2016 Best Demo Award for Interactive musical improvisation with Magenta. In the YouTube video below, you can listen to one part of the demo, the MusicVAE variational autoencoder model morphing smoothly from one melody to another. People + AI Research (PAIR) Initiative Advances in machine learning offer entirely new possibilities for how people might interact with computers. At the same time, it’s critical to make sure that society can broadly benefit from the technology we’re building. We see these opportunities and challenges as an urgent matter, and teamed up with a number of people throughout Google to create the People + AI Research (PAIR) initiative.
PAIR’s goal is to study and design the most effective ways for people to interact with AI systems. We kicked off the initiative with a public symposium bringing together academics and practitioners across disciplines ranging from computer science, design, and even art. PAIR works on a wide range of topics, some of which we’ve already mentioned: helping researchers understand ML systems through work on interpretability and expanding the community of developers with deeplearn.js. Another example of our human-centered approach to ML engineering is the launch of Facets, a tool for visualizing and understanding training datasets.
Facets provides insights into your training datasets.
Cultural differences can surface in training data even in objects as “universal” as chairs, as observed in these doodle patterns on the left. The chart on the right shows how we uncovered geo-location biases in standard open source data sets such as ImageNet. Undetected or uncorrected, such biases may strongly influence model behavior.
We made this video in collaboration with our colleagues at Google Creative Lab as a non-technical introduction to some of the issues in this area. Our Culture One aspect of our group’s research culture is to empower researchers and engineers to tackle the basic research problems that they view as most important. In September, we posted about our general approach to conducting research. Educating and mentoring young researchers is something we do through our research efforts. Our group hosted over 100 interns last year, and roughly 25% of our research publications in 2017 have intern co-authors. In 2016, we started the Google Brain Residency, a program for mentoring people who wanted to learn to do machine learning research. In the inaugural year (June 2016 to May 2017), 27 residents joined our group, and we posted updates about the first year of the program in halfway through and just after the end highlighting the research accomplishments of the residents. Many of the residents in the first year of the program have stayed on in our group as full-time researchers and research engineers, and most of those that did not have gone on to Ph.D. programs at top machine learning graduate programs like Berkeley, CMU, Stanford, NYU and Toronto. In July, 2017, we also welcomed our second cohort of 35 residents, who will be with us until July, 2018, and they’ve already done some exciting research and published at numerous research venues. We’ve now broadened the program to include many other research groups across Google and renamed it the Google AI Residency program (the application deadline for this year's program has just passed; look for information about next year's program at g.co/airesidency/apply).
Our work in 2017 spanned more than we’ve highlighted on in this two-part blog post. We believe in publishing our work in top research venues, and last year our group published 140 papers, including more than 60 at ICLR, ICML, and NIPS. To learn more about our work, you can peruse our research papers.
The Google Brain team is becoming more spread out, with team members across North America and Europe. If the work we’re doing sounds interesting and you’d like to join us, you can see our open positions and apply for internships, the AI Residency program, visiting faculty, or full-time research or engineering roles using the links at the bottom of g.co/brain. You can also follow our work throughout 2018 here on the Google Research blog, or on Twitter at @GoogleResearch. You can also follow my personal account at @JeffDean.
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain Team
The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. Last year we shared a summary of our work in 2016. Since then, we’ve continued to make progress on our long-term research agenda of making machines intelligent, and have collaborated with a number of teams across Google and Alphabet to use the results of our research to improve people’s lives. This first of two posts will highlight some of our work in 2017, including some of our basic research work, as well as updates on open source software, datasets, and new hardware for machine learning. In the second post we’ll dive into the research we do in specific domains where machine learning can have a large impact, such as healthcare, robotics, and some areas of basic science, as well as cover our work on creativity, fairness and inclusion and tell you a bit more about who we are.
Core Research A significant focus of our team is pursuing research that advances our understanding and improves our ability to solve new problems in the field of machine learning. Below are several themes from our research last year.
AutoML The goal of automating machine learning is to develop techniques for computers to solve new machine learning problems automatically, without the need for human machine learning experts to intervene on every new problem. If we’re ever going to have truly intelligent systems, this is a fundamental capability that we will need. We developed new approaches for designing neural network architectures using both reinforcement learning and evolutionary algorithms, scaled this work to state-of-the-art results on ImageNet classification and detection, and also showed how to learn new optimization algorithms and effective activation functions automatically. We are actively working with our Cloud AI team to bring this technology into the hands of Google customers, as well as continuing to push the research in many directions.
Speech Understanding and Generation Another theme is on developing new techniques that improve the ability of our computing systems to understand and generate human speech, including our collaboration with the speech team at Google to develop a number of improvements for an end-to-end approach to speech recognition, which reduces the relative word error rate over Google’s production speech recognition system by 16%. One nice aspect of this work is that it required many separate threads of research to come together (which you can find on Arxiv: 1, 2, 3, 4, 5, 6, 7, 8, 9).
We also collaborated with our research colleagues on Google’s Machine Perception team to develop a new approach for performing text-to-speech generation (Tacotron 2) that dramatically improves the quality of the generated speech. This model achieves a mean opinion score (MOS) of 4.53 compared to a MOS of 4.58 for professionally recorded speech like you might find in an audiobook, and 4.34 for the previous best computer-generated speech system. You can listen for yourself.
New Machine Learning Algorithms and Approaches We continued to develop novel machine learning algorithms and approaches, including work on capsules (which explicitly look for agreement in activated features as a way of evaluating many different noisy hypotheses when performing visual tasks), sparsely-gated mixtures of experts (which enable very large models that are still computational efficient), hypernetworks (which use the weights of one model to generate weights for another model), new kinds of multi-modal models (which perform multi-task learning across audio, visual, and textual inputs in the same model), attention-based mechanisms (as an alternative to convolutional and recurrent models), symbolic and non-symbolic learned optimization methods, a technique to back-propagate through discrete variables, and a few new reinforcementlearning algorithmic improvements.
Understanding Machine Learning Systems While we have seen impressive results with deep learning, it is important to understand why it works, and when it won’t. In another one of the best paper awards of ICLR 2017, we showed that current machine learning theoretical frameworks fail to explain the impressive results of deep learning approaches. We also showed that the “flatness” of minima found by optimization methods is not as closely linked to good generalization as initially thought. In order to better understand how training proceeds in deep architectures, we published a series of papers analyzing randommatrices, as they are the starting point of most training approaches. Another important avenue to understand deep learning is to better measure their performance. We showed the importance of good experimental design and statistical rigor in a recent study comparing many GAN approaches that found many popular enhancements to generative models do not actually improve performance. We hope this study will give an example for other researchers to follow in making robust experimental studies.
We are developing methods that allow better interpretability of machine learning systems. And in March, in collaboration with OpenAI, DeepMind, YC Research and others, we announced the launch of Distill, a new online open science journal dedicated to supporting human understanding of machine learning. It has gained a reputation for clear exposition of machine learning concepts and for excellent interactive visualization tools in its articles. In its first year, Distill has published manyilluminatingarticles aimed at understanding the inner working of various machine learning techniques, and we look forward to the many more sure to come in 2018.
Open Datasets for Machine Learning Research Open datasets like MNIST, CIFAR-10, ImageNet, SVHN, and WMT have pushed the field of machine learning forward tremendously. Our team and Google Research as a whole have been active in open-sourcing interesting new datasets for open machine learning research over the past year or so, by providing access to more large labeled datasets including:
YouTube-8M: >7 million YouTube videos annotated with 4,716 different classes
Examples from the YouTube-Bounding Boxes dataset: Video segments sampled at 1 frame per second, with bounding boxes successfully identified around the items of interest.
TensorFlow and Open Source Software
A map showing the broad distribution of TensorFlow users (source)
Throughout our team’s history, we have built tools that help us to conduct machine learning research and deploy machine learning systems in Google’s many products. In November 2015, we open-sourced our second-generation machine learning framework, TensorFlow, with the hope of allowing the machine learning community as a whole to benefit from our investment in machine learning software tools. In February, we released TensorFlow 1.0, and in November, we released v1.4 with these significant additions: Eager execution for interactive imperative-style programming, XLA, an optimizing compiler for TensorFlow programs, and TensorFlow Lite, a lightweight solution for mobile and embedded devices. The pre-compiled TensorFlow binaries have now been downloaded more than 10 million times in over 180 countries, and the source code on GitHub now has more than 1,200 contributors.
In February, we hosted the first ever TensorFlow Developer Summit, with over 450 people attending live in Mountain View and more than 6,500 watching on live streams around the world, including at more than 85 local viewing events in 35 countries. All talks were recorded, with topics ranging from new features, techniques for using TensorFlow, or detailed looks under the hoods at low-level TensorFlow abstractions. We’ll be hosting another TensorFlow Developer Summit on March 30, 2018 in the Bay Area. Sign up now to save the date and stay updated on the latest news.
In November, TensorFlow celebrated its second anniversary as an open-source project. It has been incredibly rewarding to see a vibrant community of TensorFlow developers and users emerge. TensorFlow is the #1 machine learning platform on GitHub and one of the top five repositories on GitHub overall, used by many companies and organizations, big and small, with more than 24,500 distinct repositories on GitHub related to TensorFlow. Many research papers are now published with open-source TensorFlow implementations to accompany the research results, enabling the community to more easily understand the exact methods used and to reproduce or extend the work.
TensorFlow has also benefited from other Google Research teams open-sourcing related work, including TF-GAN, a lightweight library for generative adversarial models in TensorFlow, TensorFlow Lattice, a set of estimators for working with lattice models, as well as the TensorFlow Object Detection API. The TensorFlow model repository continues to grow with an ever-widening set of models.
In addition to TensorFlow, we released deeplearn.js, an open-source hardware-accelerated implementation of deep learning APIs right in the browser (with no need to download or install anything). The deeplearn.js homepage has a number of great examples, including Teachable Machine, a computer vision model you train using your webcam, and Performance RNN, a real-time neural-network based piano composition and performance demonstration. We’ll be working in 2018 to make it possible to deploy TensorFlow models directly into the deeplearn.js environment.
TPUs
Cloud TPUs deliver up to 180 teraflops of machine learning acceleration
About five years ago, we recognized that deep learning would dramatically change the kinds of hardware we would need. Deep learning computations are very computationally intensive, but they have two special properties: they are largely composed of dense linear algebra operations (matrix multiples, vector operations, etc.), and they are very tolerant of reduced precision. We realized that we could take advantage of these two properties to build specialized hardware that can run neural network computations very efficiently. We provided design input to Google’s Platforms team and they designed and produced our first generation Tensor Processing Unit (TPU): a single-chip ASIC designed to accelerate inference for deep learning models (inference is the use of an already-trained neural network, and is distinct from training). This first-generation TPU has been deployed in our data centers for three years, and it has been used to power deep learning models on every Google Search query, for Google Translate, for understanding images in Google Photos, for the AlphaGo matches against Lee Sedol and Ke Jie, and for many other research and product uses. In June, we published a paper at ISCA 2017, showing that this first-generation TPU was 15X - 30X faster than its contemporary GPU or CPU counterparts, with performance/Watt about 30X - 80X better.
Cloud TPU Pods deliver up to 11.5 petaflops of machine learning acceleration
Inference is important, but accelerating the training process is an even more important problem - and also much harder. The faster researchers can try a new idea, the more breakthroughs we can make. Our second-generation TPU, announced at Google I/O in May, is a whole system (custom ASIC chips, board and interconnect) that is designed to accelerate both training and inference, and we showed a single device configuration as well as a multi-rack deep learning supercomputer configuration called a TPU Pod. We announced that these second generation devices will be offered on the Google Cloud Platform as Cloud TPUs. We also unveiled the TensorFlow Research Cloud (TFRC), a program to provide top ML researchers who are committed to sharing their work with the world to access a cluster of 1,000 Cloud TPUs for free. In December, we presented work showing that we can train a ResNet-50 ImageNet model to a high level of accuracy in 22 minutes on a TPU Pod as compared to days or longer on a typical workstation. We think lowering research turnaround times in this fashion will dramatically increase the productivity of machine learning teams here at Google and at all of the organizations that use Cloud TPUs. If you’re interested in Cloud TPUs, TPU Pods, or the TensorFlow Research Cloud, you can sign up to learn more at g.co/tpusignup. We’re excited to enable many more engineers and researchers to use TPUs in 2018!
Thanks for reading!
(In part 2 we’ll discuss our research in the application of machine learning to domains like healthcare, robotics, different fields of science, and creativity, as well as cover our work on fairness and inclusion.)
Posted by Jonathan Shen and Ruoming Pang, Software Engineers, on behalf of the Google Brain and Machine Perception Teams
Generating very natural sounding speech from text (text-to-speech, TTS) has been a research goal for decades. There has been great progress in TTS research over the last few years and many individual pieces of a complete TTS system have greatly improved. Incorporating ideas from past work such as Tacotron and WaveNet, we added more improvements to end up with our new system, Tacotron 2. Our approach does not use complex linguistic and acoustic features as input. Instead, we generate human-like speech from text using neural networks trained using only speech examples and corresponding text transcripts.
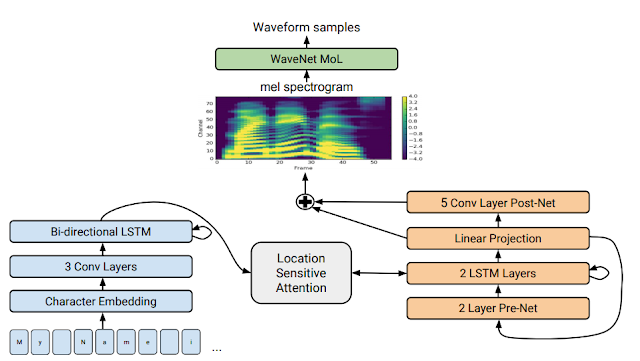
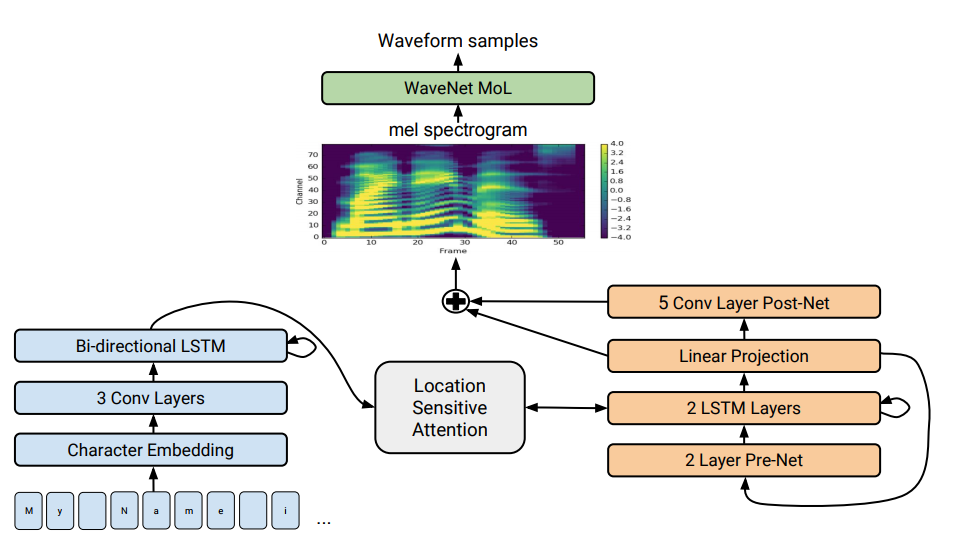
A full description of our new system can be found in our paper “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.” In a nutshell it works like this: We use a sequence-to-sequence model optimized for TTS to map a sequence of letters to a sequence of features that encode the audio. These features, an 80-dimensional audio spectrogram with frames computed every 12.5 milliseconds, capture not only pronunciation of words, but also various subtleties of human speech, including volume, speed and intonation. Finally these features are converted to a 24 kHz waveform using a WaveNet-like architecture.
A detailed look at Tacotron 2's model architecture. The lower half of the image describes the sequence-to-sequence model that maps a sequence of letters to a spectrogram. For technical details, please refer to the paper.
You can listen to some of the Tacotron 2 audio samples that demonstrate the results of our state-of-the-art TTS system. In an evaluation where we asked human listeners to rate the naturalness of the generated speech, we obtained a score that was comparable to that of professional recordings.
While our samples sound great, there are still some difficult problems to be tackled. For example, our system has difficulties pronouncing complex words (such as “decorum” and “merlot”), and in extreme cases it can even randomly generate strange noises. Also, our system cannot yet generate audio in realtime. Furthermore, we cannot yet control the generated speech, such as directing it to sound happy or sad. Each of these is an interesting research problem on its own.
Acknowledgements Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu, Sound Understanding team, TTS Research team, and TensorFlow team.
Posted by Tara N. Sainath, Research Scientist, Speech Team and Yonghui Wu, Research Scientist, Google Brain Team
Traditional automatic speech recognition (ASR) systems, used for a variety of voice search applications at Google, are comprised of an acoustic model (AM), a pronunciation model (PM) and a language model (LM), all of which are independently trained, and often manually designed, on different datasets [1]. AMs take acoustic features and predict a set of subword units, typically context-dependent or context-independent phonemes. Next, a hand-designed lexicon (the PM) maps a sequence of phonemes produced by the acoustic model to words. Finally, the LM assigns probabilities to word sequences. Training independent components creates added complexities and is suboptimal compared to training all components jointly. Over the last several years, there has been a growing popularity in developing end-to-end systems, which attempt to learn these separate components jointly as a single system. While these end-to-end models have shown promising results in the literature [2, 3], it is not yet clear if such approaches can improve on current state-of-the-art conventional systems.
Today we are excited to share “State-of-the-art Speech Recognition With Sequence-to-Sequence Models [4],” which describes a new end-to-end model that surpasses the performance of a conventional production system [1]. We show that our end-to-end system achieves a word error rate (WER) of 5.6%, which corresponds to a 16% relative improvement over a strong conventional system which achieves a 6.7% WER. Additionally, the end-to-end model used to output the initial word hypothesis, before any hypothesis rescoring, is 18 times smaller than the conventional model, as it contains no separate LM and PM.
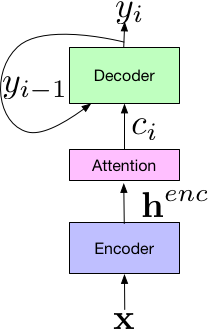
Our system builds on the Listen-Attend-Spell (LAS) end-to-end architecture, first presented in [2]. The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
Components of the LAS End-to-End Model.
All components of the LAS model are trained jointly as a single end-to-end neural network, instead of as separate modules like conventional systems, making it much simpler. Additionally, because the LAS model is fully neural, there is no need for external, manually designed components such as finite state transducers, a lexicon, or text normalization modules. Finally, unlike conventional models, training end-to-end models does not require bootstrapping from decision trees or time alignments generated from a separate system, and can be trained given pairs of text transcripts and the corresponding acoustics.
In [4], we introduce a variety of novel structural improvements, including improving the attention vectors passed to the decoder and training with longer subword units (i.e., wordpieces). In addition, we also introduce numerous optimization improvements for training, including the use of minimum word error rate training [5]. These structural and optimization improvements are what accounts for obtaining the 16% relative improvement over the conventional model.
Another exciting potential application for this research is multi-dialect and multi-lingual systems, where the simplicity of optimizing a single neural network makes such a model very attractive. Here data for all dialects/languages can be combined to train one network, without the need for a separate AM, PM and LM for each dialect/language. We find that these models work well on 7 english dialects [6] and 9 Indian languages [7], while outperforming a model trained separately on each individual language/dialect.
While we are excited by our results, our work is not done. Currently, these models cannot process speech in real time [8, 9], which is a strong requirement for latency-sensitive applications such as voice search. In addition, these models still compare negatively to production when evaluated on live production data. Furthermore, our end-to-end model is learned on 22,000 audio-text pair utterances compared to a conventional system that is typically trained on significantly larger corpora. In addition, our proposed model is not able to learn proper spellings for rarely used words such as proper nouns, which is normally performed with a hand-designed PM. Our ongoing efforts are focused now on addressing these challenges.
Acknowledgements This work was done as a strong collaborative effort between Google Brain and Speech teams. Contributors include Tara Sainath, Rohit Prabhavalkar, Bo Li, Kanishka Rao, Shankar Kumar, Shubham Toshniwal, Michiel Bacchiani and Johan Schalkwyk from the Speech team; as well as Yonghui Wu, Patrick Nguyen, Zhifeng Chen, Chung-cheng Chiu, Anjuli Kannan, Ron Weiss and Navdeep Jaitly from the Google Brain team. The work is described in more detail in papers [4-11]
Posted by Vincent Vanhoucke, Principal Scientist, Google Brain Team and Melanie Saldaña, Program Manager, University Relations
Whether in the form of autonomous vehicles, home assistants or disaster rescue units, robotic systems of the future will need to be able to operate safely and effectively in human-centric environments. In contrast to to their industrial counterparts, they will require a very high level of perceptual awareness of the world around them, and to adapt to continuous changes in both their goals and their environment. Machine learning is a natural answer to both the problems of perception and generalization to unseen environments, and with the recent rapid progress in computer vision and learning capabilities, applying these new technologies to the field of robotics is becoming a very central research question.
This past November, Google helped kickstart and host the first Conference on Robot Learning (CoRL) at our campus in Mountain View. The goal of CoRL was to bring machine learning and robotics experts together for the first time in a single-track conference, in order to foster new research avenues between the two disciplines. The sold-out conference attracted 350 researchers from many institutions worldwide, who collectively presented 74 original papers, along with 5 keynotes by some of the most innovative researchers in the field.
Prof. Sergey Levine, CoRL 2017 co-chair, answering audience questions.
Sayna Ebrahimi (UC Berkeley) presenting her research.
Across many scientific disciplines, but in particular in the field of genomics, major breakthroughs have often resulted from new technologies. From Sanger sequencing, which made it possible to sequence the human genome, to the microarray technologies that enabled the first large-scale genome-wide experiments, new instruments and tools have allowed us to look ever more deeply into the genome and apply the results broadly to health, agriculture and ecology.
One of the most transformative new technologies in genomics was high-throughput sequencing (HTS), which first became commercially available in the early 2000s. HTS allowed scientists and clinicians to produce sequencing data quickly, cheaply, and at scale. However, the output of HTS instruments is not the genome sequence for the individual being analyzed — for humans this is 3 billion paired bases (guanine, cytosine, adenine and thymine) organized into 23 pairs of chromosomes. Instead, these instruments generate ~1 billion short sequences, known as reads. Each read represents just 100 of the 3 billion bases, and per-base error rates range from 0.1-10%. Processing the HTS output into a single, accurate and complete genome sequence is a major outstanding challenge. The importance of this problem, for biomedical applications in particular, has motivated efforts such as the Genome in a Bottle Consortium (GIAB), which produces high confidence human reference genomes that can be used for validation and benchmarking, as well as the precisionFDA community challenges, which are designed to foster innovation that will improve the quality and accuracy of HTS-based genomic tests.
CAPTION: For any given location in the genome, there are multiple reads among the ~1 billion that include a base at that position. Each read is aligned to a reference, and then each of the bases in the read is compared to the base of the reference at that location. When a read includes a base that differs from the reference, it may indicate a variant (a difference in the true sequence), or it may be an error.
Today, we announce the open source release of DeepVariant, a deep learning technology to reconstruct the true genome sequence from HTS sequencer data with significantly greater accuracy than previous classical methods. This work is the product of more than two years of research by the Google Brain team, in collaboration with Verily Life Sciences. DeepVariant transforms the task of variant calling, as this reconstruction problem is known in genomics, into an image classification problem well-suited to Google's existing technology and expertise.
CAPTION: Each of the four images above is a visualization of actual sequencer reads aligned to a reference genome. A key question is how to use the reads to determine whether there is a variant on both chromosomes, on just one chromosome, or on neither chromosome. There is more than one type of variant, with SNPs and insertions/deletions being the most common. A: a true SNP on one chromosome pair, B: a deletion on one chromosome, C: a deletion on both chromosomes, D: a false variant caused by errors. It's easy to see that these look quite distinct when visualized in this manner.
We started with GIAB reference genomes, for which there is high-quality ground truth (or the closest approximation currently possible). Using multiple replicates of these genomes, we produced tens of millions of training examples in the form of multi-channel tensors encoding the HTS instrument data, and then trained a TensorFlow-based image classification model to identify the true genome sequence from the experimental data produced by the instruments. Although the resulting deep learning model, DeepVariant, had no specialized knowledge about genomics or HTS, within a year it had won the the highest SNP accuracy award at the precisionFDA Truth Challenge, outperforming state-of-the-art methods. Since then, we've further reduced the error rate by more than 50%.
DeepVariant is being released as open source software to encourage collaboration and to accelerate the use of this technology to solve real world problems. To further this goal, we partnered with Google Cloud Platform (GCP) to deploy DeepVariant workflows on GCP, available today, in configurations optimized for low-cost and fast turnarounds using scalable GCP technologies like the Pipelines API. This paired set of releases provides a smooth ramp for users to explore and evaluate the capabilities of DeepVariant in their current compute environment while providing a scalable, cloud-based solution to satisfy the needs of even the largest genomics datasets.
DeepVariant is the first of what we hope will be many contributions that leverage Google's computing infrastructure and ML expertise to both better understand the genome and to provide deep learning-based genomics tools to the community. This is all part of a broader goal to apply Google technologies to healthcare and other scientific applications, and to make the results of these efforts broadly accessible.
By Mark DePristo and Ryan Poplin, Google Brain Team