The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. In Part 1 of this blog post, we shared some of our work in 2017 related to our broader research, from designing new machine learning algorithms and techniques to understanding them, as well as sharing data, software, and hardware with the community. In this post, we’ll dive into the research we do in some specific domains such as healthcare, robotics, creativity, fairness and inclusion, as well as share a little more about us.
Healthcare
We feel there is enormous potential for the application of machine learning techniques to healthcare. We are doing work across many different kinds of problems, including assisting pathologists in detecting cancer, understanding medical conversations to assist doctors and patients, and using machine learning to tackle a wide variety of problems in genomics, including an open-source release of a highly accurate variant calling system based on deep learning.
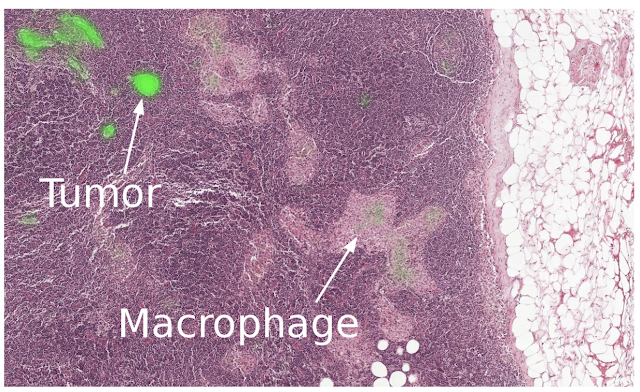 |
| A lymph node biopsy, where our algorithm correctly identifies the tumor and not the benign macrophage. |
 |
| First patient screened (top) and Iniya Paramasivam, a trained grader, viewing the output of the system (bottom). |
Robotics
Our long-term goal in robotics is to design learning algorithms to allow robots to operate in messy, real-world environments and to quickly acquire new skills and capabilities via learning, rather than the carefully-controlled conditions and the small set of hand-programmed tasks that characterize today’s robots. One thrust of our research is on developing techniques for physical robots to use their own experience and those of other robots to build new skills and capabilities, pooling the shared experiences in order to learn collectively. We are also exploring ways in which we can combine computer-based simulations of robotic tasks with physical robotic experience to learn new tasks more rapidly. While the physics of the simulator don’t entirely match up with the real world, we have observed that for robotics, simulated experience plus a small amount of real-world experience gives significantly better results than even large amounts of real-world experience on its own.
In addition to real-world robotic experience and simulated robotic environments, we have developed robotic learning algorithms that can learn by observing human demonstrations of desired behaviors, and believe that this imitation learning approach is a highly promising way of imparting new abilities to robots very quickly, without explicit programming or even explicit specification of the goal of an activity. For example, below is a video of a robot learning to pour from a cup in just 15 minutes of real world experience by observing humans performing this task from different viewpoints and then trying to imitate the behavior. As we might be with our own three-year-old child, we’re encouraged that it only spills a little!
We also co-organized and hosted the first occurrence of the new Conference on Robot Learning (CoRL) in November to bring together researchers working at the intersection of machine learning and robotics. The summary of the event contains more information, and we look forward to next year’s occurrence of the conference in Zürich.
Basic Science
We are also excited about the long term potential of using machine learning to help solve important problems in science. Last year, we utilized neural networks for predicting molecular properties in quantum chemistry, finding new exoplanets in astronomical datasets, earthquake aftershock prediction, and used deep learning to guide automated proof systems.
 |
| A Message Passing Neural Network predicts quantum properties of an organic molecule |
 |
| Finding a new exoplanet: observing brightness of stars when planets block their light. |
We’re very interested in how to leverage machine learning as a tool to assist people in creative endeavors. This year, we created an AI piano duet tool, helped YouTube musician Andrew Huang create new music (see also the behind the scenes video with Nat & Friends), and showed how to teach machines to draw.
 |
| A garden drawn by the SketchRNN model; an interactive demo is available. |
People + AI Research (PAIR) Initiative
Advances in machine learning offer entirely new possibilities for how people might interact with computers. At the same time, it’s critical to make sure that society can broadly benefit from the technology we’re building. We see these opportunities and challenges as an urgent matter, and teamed up with a number of people throughout Google to create the People + AI Research (PAIR) initiative.
PAIR’s goal is to study and design the most effective ways for people to interact with AI systems. We kicked off the initiative with a public symposium bringing together academics and practitioners across disciplines ranging from computer science, design, and even art. PAIR works on a wide range of topics, some of which we’ve already mentioned: helping researchers understand ML systems through work on interpretability and expanding the community of developers with deeplearn.js. Another example of our human-centered approach to ML engineering is the launch of Facets, a tool for visualizing and understanding training datasets.
 |
| Facets provides insights into your training datasets. |
As ML plays an increasing role in technology, considerations of inclusivity and fairness grow in importance. The Brain team and PAIR have been working hard to make progress in these areas. We’ve published on how to avoid discrimination in ML systems via causal reasoning, the importance of geodiversity in open datasets, and posted an analysis of an open dataset to understand diversity and cultural differences. We’ve also been working closely with the Partnership on AI, a cross-industry initiative, to help make sure that fairness and inclusion are promoted as goals for all ML practitioners.
 |
Cultural differences can surface in training data even in objects as “universal” as chairs, as observed in these doodle patterns on the left. The chart on the right shows how we uncovered geo-location biases in standard open source data sets such as ImageNet. Undetected or uncorrected, such biases may strongly influence model behavior. |
Our Culture
One aspect of our group’s research culture is to empower researchers and engineers to tackle the basic research problems that they view as most important. In September, we posted about our general approach to conducting research. Educating and mentoring young researchers is something we do through our research efforts. Our group hosted over 100 interns last year, and roughly 25% of our research publications in 2017 have intern co-authors. In 2016, we started the Google Brain Residency, a program for mentoring people who wanted to learn to do machine learning research. In the inaugural year (June 2016 to May 2017), 27 residents joined our group, and we posted updates about the first year of the program in halfway through and just after the end highlighting the research accomplishments of the residents. Many of the residents in the first year of the program have stayed on in our group as full-time researchers and research engineers, and most of those that did not have gone on to Ph.D. programs at top machine learning graduate programs like Berkeley, CMU, Stanford, NYU and Toronto. In July, 2017, we also welcomed our second cohort of 35 residents, who will be with us until July, 2018, and they’ve already done some exciting research and published at numerous research venues. We’ve now broadened the program to include many other research groups across Google and renamed it the Google AI Residency program (the application deadline for this year's program has just passed; look for information about next year's program at g.co/airesidency/apply).
Our work in 2017 spanned more than we’ve highlighted on in this two-part blog post. We believe in publishing our work in top research venues, and last year our group published 140 papers, including more than 60 at ICLR, ICML, and NIPS. To learn more about our work, you can peruse our research papers.
You can also meet some of our team members in this video, or read our responses to our second Ask Me Anything (AMA) post on r/MachineLearning (and check out the 2016’s AMA, too).
The Google Brain team is becoming more spread out, with team members across North America and Europe. If the work we’re doing sounds interesting and you’d like to join us, you can see our open positions and apply for internships, the AI Residency program, visiting faculty, or full-time research or engineering roles using the links at the bottom of g.co/brain. You can also follow our work throughout 2018 here on the Google Research blog, or on Twitter at @GoogleResearch. You can also follow my personal account at @JeffDean.
Thanks for reading!
