Posted by Shayne Longpre, Student Researcher, and Adam Roberts, Senior Staff Software Engineer, Google Research, Brain Team 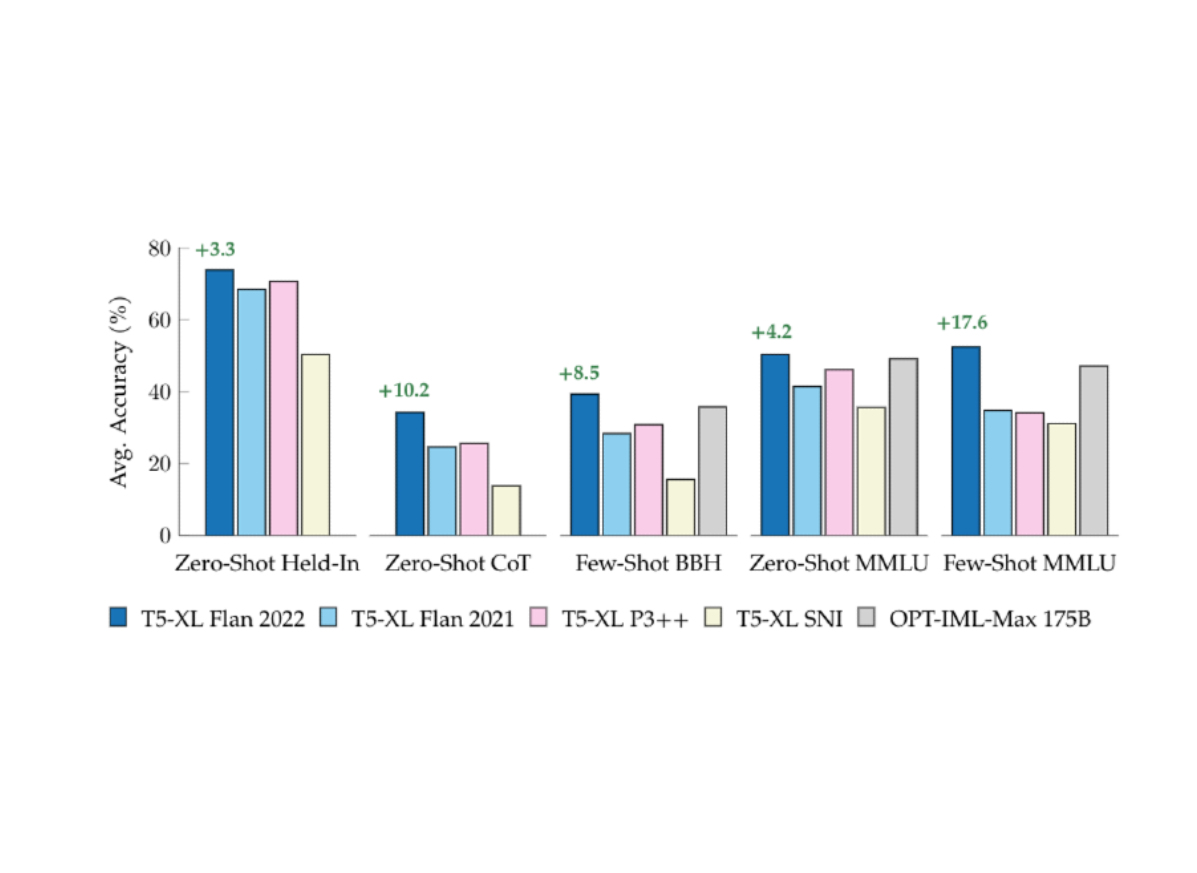
Language models are now capable of performing many new natural language processing (NLP) tasks by reading instructions, often that they hadn’t seen before. The ability to reason on new tasks is mostly credited to training models on a wide variety of unique instructions, known as “instruction tuning”, which was introduced by FLAN and extended in T0, Super-Natural Instructions, MetaICL, and InstructGPT. However, much of the data that drives these advances remain unreleased to the broader research community.
In “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning”, we closely examine and release a newer and more extensive publicly available collection of tasks, templates, and methods for instruction tuning to advance the community’s ability to analyze and improve instruction-tuning methods. This collection was first used in Flan-T5 and Flan-PaLM, for which the latter achieved significant improvements over PaLM. We show that training a model on this collection yields improved performance over comparable public collections on all tested evaluation benchmarks, e.g., a 3%+ improvement on the 57 tasks in the Massive Multitask Language Understanding (MMLU) evaluation suite and 8% improvement on BigBench Hard (BBH). Analysis suggests the improvements stem both from the larger and more diverse set of tasks and from applying a set of simple training and data augmentation techniques that are cheap and easy to implement: mixing zero-shot, few-shot, and chain of thought prompts at training, enriching tasks with input inversion, and balancing task mixtures. Together, these methods enable the resulting language models to reason more competently over arbitrary tasks, even those for which it hasn’t seen any fine-tuning examples. We hope making these findings and resources publicly available will accelerate research into more powerful and general-purpose language models.
Public instruction tuning data collections
Since 2020, several instruction tuning task collections have been released in rapid succession, shown in the timeline below. Recent research has yet to coalesce around a unified set of techniques, with different sets of tasks, model sizes, and input formats all represented. This new collection, referred to below as “Flan 2022”, combines prior collections from FLAN, P3/T0, and Natural Instructions with new dialog, program synthesis, and complex reasoning tasks.
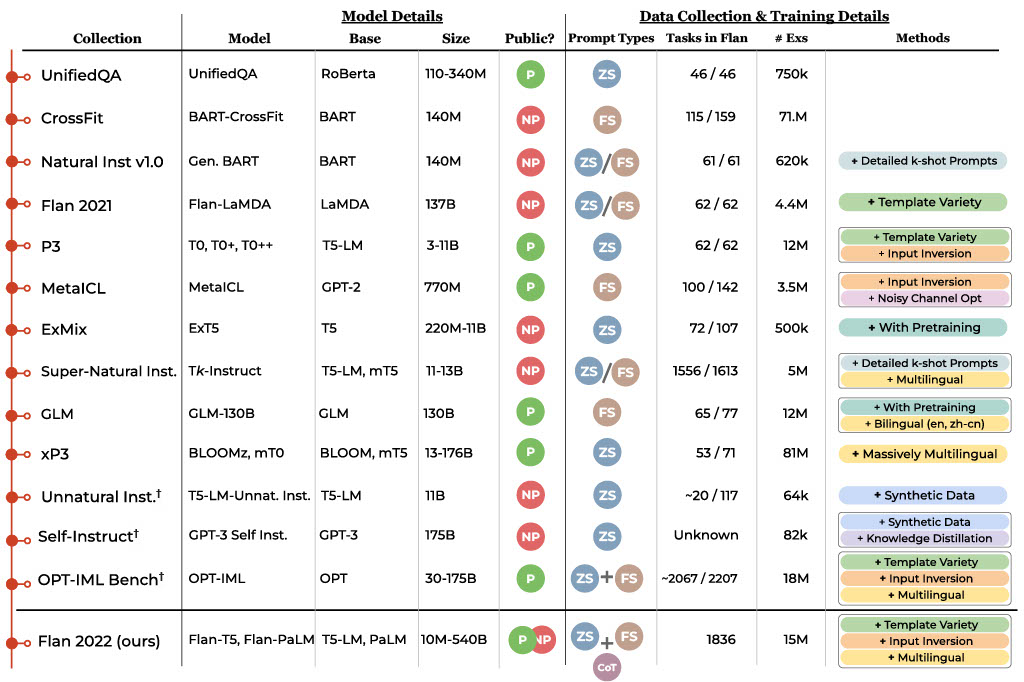 |
| A timeline of public instruction tuning collections, including: UnifiedQA, CrossFit, Natural Instructions, FLAN, P3/T0, MetaICL, ExT5, Super-Natural Instructions, mT0, Unnatural Instructions, Self-Instruct, and OPT-IML Bench. The table describes the release date, the task collection name, the model name, the base model(s) that were finetuned with this collection, the model size, whether the resulting model is Public (green) or Not Public (red), whether they train with zero-shot prompts (“ZS”), few-shot prompts (“FS”), chain-of-thought prompts (“CoT”) together (“+”) or separately (“/”), the number of tasks from this collection in Flan 2022, the total number of examples, and some notable methods, related to the collections, used in these works. Note that the number of tasks and examples vary under different assumptions and so are approximations. Counts for each are reported using task definitions from the respective works. |
In addition to scaling to more instructive training tasks, The Flan Collection combines training with different types of input-output specifications, including just instructions (zero-shot prompting), instructions with examples of the task (few-shot prompting), and instructions that ask for an explanation with the answer (chain of thought prompting). Except for InstructGPT, which leverages a collection of proprietary data, Flan 2022 is the first work to publicly demonstrate the strong benefits of mixing these prompting settings together during training. Instead of a trade-off between the various settings, mixing prompting settings during training improves all prompting settings at inference time, as shown below for both tasks held-in and held-out from the set of fine-tuning tasks.
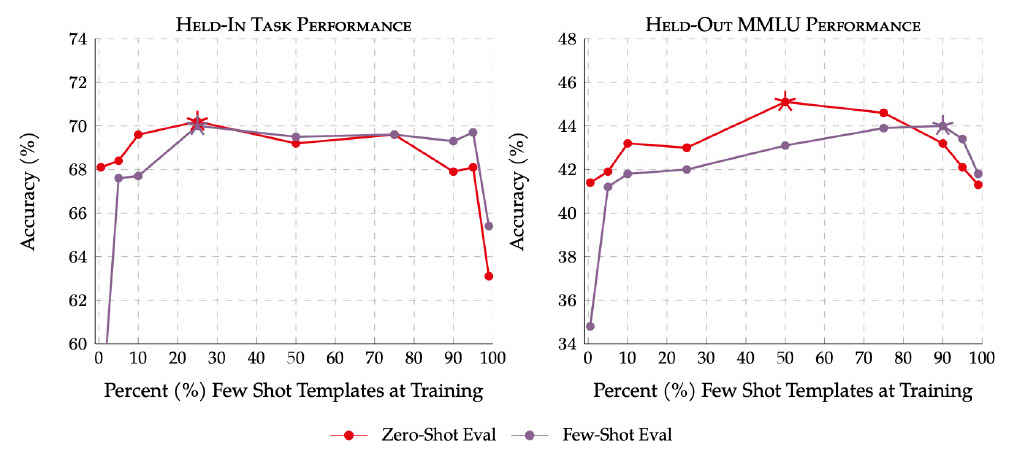 |
| Training jointly with zero-shot and few-shot prompt templates improves performance on both held-in and held-out tasks. The stars indicate the peak performance in each setting. Red lines denote the zero-shot prompted evaluation, lilac denotes few-shot prompted evaluation. |
Evaluating instruction tuning methods
To understand the overall effects of swapping one instruction tuning collection for another, we fine-tune equivalently-sized T5 models on popular public instruction-tuning collections, including Flan 2021, T0++, and Super-Natural Instructions. Each model is then evaluated on a set of tasks that are already included in each of the instruction tuning collections, a set of five chain-of-thought tasks, and then a set of 57 diverse tasks from the MMLU benchmark, both with zero-shot and few-shot prompts. In each case, the new Flan 2022 model, Flan-T5, outperforms these prior works, demonstrating a more powerful general-purpose NLP reasoner.
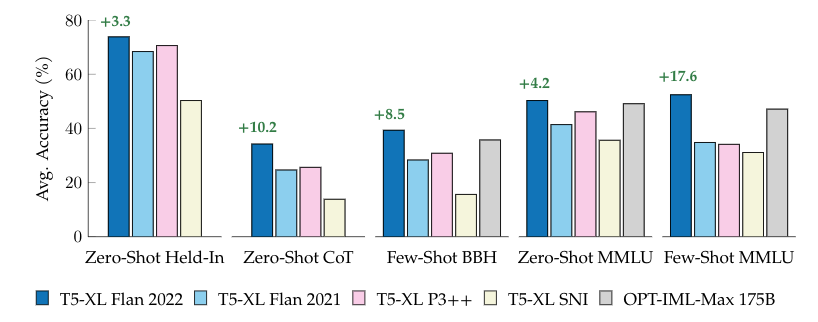 |
| Comparing public instruction tuning collections on held-in, chain-of-thought, and held-out evaluation suites, such as BigBench Hard and MMLU. All models except OPT-IML-Max (175B) are trained by us, using T5-XL with 3B parameters. Green text indicates improvement over the next best comparable T5-XL (3B) model. |
Single task fine-tuning
In applied settings, practitioners usually deploy NLP models fine-tuned specifically for one target task, where training data is already available. We examine this setting to understand how Flan-T5 compares to T5 models as a starting point for applied practitioners. Three settings are compared: fine-tuning T5 directly on the target task, using Flan-T5 without further fine-tuning on the target task, and fine-tuning Flan-T5 on the target task. For both held-in and held-out tasks, fine-tuning Flan-T5 offers an improvement over fine-tuning T5 directly. In some instances, usually where training data is limited for a target task, Flan-T5 without further fine-tuning outperforms T5 with direct fine-tuning.
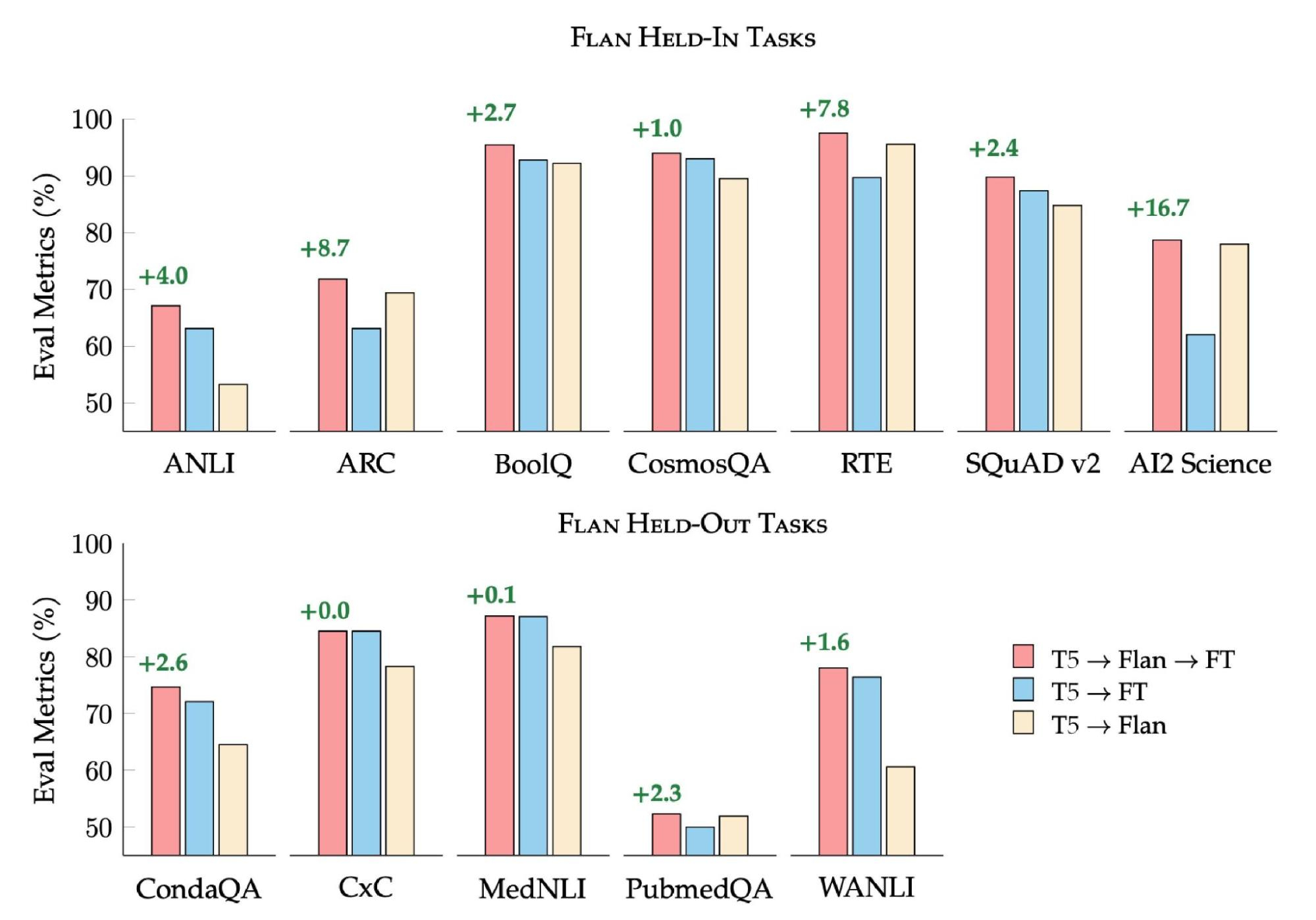 |
| Flan-T5 outperforms T5 on single-task fine-tuning. We compare single-task fine-tuned T5 (blue bars), single-task fine-tuned Flan-T5 (red), and Flan-T5 without any further fine-tuning (beige). |
An additional benefit of using Flan-T5 as a starting point is that training is significantly faster and cheaper, converging more quickly than T5 fine-tuning, and usually peaking at higher accuracies. This suggests less task-specific training data may be necessary to achieve similar or better results on a particular task.
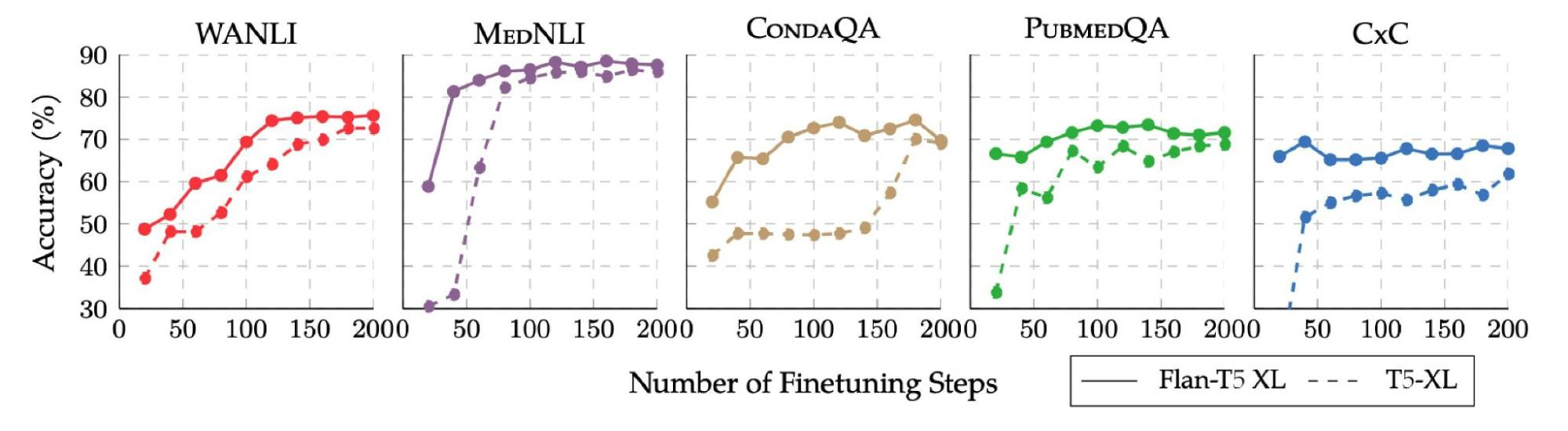 |
| Flan-T5 converges faster than T5 on single-task fine-tuning, for each of five held-out tasks from Flan fine-tuning. Flan-T5’s learning curve is indicated with the solid lines, and T5’s learning curve with the dashed line. All tasks are held-out during Flan finetuning. |
There are significant energy efficiency benefits for the NLP community to adopt instruction-tuned models like Flan-T5 for single task fine-tuning, rather than conventional non-instruction-tuned models. While pre-training and instruction fine-tuning are financially and computationally expensive, they are a one-time cost, usually amortized over millions of subsequent fine-tuning runs, which can become more costly in aggregate, for the most prominent models. Instruction-tuned models offer a promising solution in significantly reducing the amount of fine-tuning steps needed to achieve the same or better performance.
Conclusion
The new Flan instruction tuning collection unifies the most popular prior public collections and their methods, while adding new templates and simple improvements like training with mixed prompt settings. The resulting method outperforms Flan, P3, and Super-Natural Instructions on held-in, chain of thought, MMLU, and BBH benchmarks by 3–17% across zero-shot and few-shot variants. Results suggest this new collection serves as a more performant starting point for researchers and practitioners interested in both generalizing to new instructions or fine-tuning on a single new task.
Acknowledgements
It was a privilege to work with Jason Wei, Barret Zoph, Le Hou, Hyung Won Chung, Tu Vu, Albert Webson, Denny Zhou, and Quoc V Le on this project.
 Learn more about the ways Google is partnering with industry experts all year to celebrate Black culture.
Learn more about the ways Google is partnering with industry experts all year to celebrate Black culture.










 Save the date for the virtual Google for Games Developer Summit on March 14 at 9 a.m. PT.
Save the date for the virtual Google for Games Developer Summit on March 14 at 9 a.m. PT.