Posted by Amy Zeppenfeld – Developer Relations Engineer
Passkeys are leading the charge towards a more secure future without passwords. Passkeys are a new type of cryptographic credential that leverages FIDO2 and WebAuthn to provide an authentication mechanism that is phishing-resistant, user friendly, simple to implement, and more secure than password-based authentication. Most major operating systems and browsers now feature full passkey support. Passkeys are expected to replace passwords as the predominant authentication mechanism in the not-too-distant future, and developers are advised to begin implementing passkey-enabled authentication solutions today.
This is a standardized way to advertise your support for passkeys and optimize user experience. This well-known URL will allow third party services like password managers, passkey providers, and other security tools to direct users to enroll and manage their passkeys for any site that supports them. You can use app-links or deep linking with the passkey-endpoints well-known URL to allow these pages to open directly in your app.
Password management tool usage has been steadily rising, and we expect most providers will integrate passkey management as well. You can allow third party tools and services to direct your users to your dedicated passkey management page by implementing the passkey-endpoints well-known URL.
The best part is that in most cases you can implement this feature in two hours or less! All you need to do is host a simple schema on your site. Check out the example below:
For a web service at https://example.com, the well-known URLwould be https://example.com/.well-known/passkey-endpoints
When the URL is queried, the response should use the following schema:
Note: You can decide the exact value of the URLs for both enroll and manage based on your website’s own configuration.
If you have a mobile app, we strongly recommend utilizing deep linking to have these URLs open the corresponding screen for each activity directly in your app to “enroll” or “manage” passkeys. This will keep your users focused and on track to enroll into passkeys.
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Introducing Credential Manager
At Google, we are dedicated to improving the sign in experience across platforms for developers and users. For Android developers, we recently announced the public availability of Credential Manager as the future of authentication on Android. Credential Manager is a new Jetpack library designed to consolidate authentication types for Android developers into a single UI, reducing complexity for your applications while increasing usability. Credential Manager also supports passkeys, creating a unified interface for users and a single API for developers.
Instead of having to integrate with multiple identity providers, developers can now use Credential Manager as a single, unified authentication API. Credential Manager simplifies integration and makes it easier to develop authentication solutions that can work with all password managers, identity providers, and authentication methods.
Implementing Credential Manager with your Android applications will provide a single authentication experience for all Android users, integrated directly with the operating system and aligned with high-trust surfaces such as system login. We encourage all developers to migrate to Credential Manager.
Authentication APIs moving from Google Identity Services to Credential Manager on Android
Since these APIs are now generally available in Credential Manager, these individual APIs will be deprecated in Google Identity Services.
Removal of Smart Lock for Passwords
Smart Lock for Passwords, which was deprecated in 2022, will be removed from the Google Play Services SDK in November 2023. To minimize breaking changes that may impact existing integrations, all existing apps in the Play Store will continue to work. New app versions compiled with the new SDK will not be able to access the Smart Lock for Password API, so we encourage all developers to migrate to Credential Manager as soon as possible.
Get started with your migration to Credential Manager
All Android developers should plan their migration to the new Credential Manager API. To assist you in this process, read the following guides and resources:
UX guide for designing user experiences for passkeys on Android.
Share your feedback
We are excited to improve Android authentication with the launch of Credential Manager API, delivering a simple and streamlined UX for secure sign-in methods such as Sign in with Google.
We value your feedback and invite you to share your experience integrating with Credential Manager or any other feedback you might have:
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Introducing Credential Manager
At Google, we are dedicated to improving the sign in experience across platforms for developers and users. For Android developers, we recently announced the public availability of Credential Manager as the future of authentication on Android. Credential Manager is a new Jetpack library designed to consolidate authentication types for Android developers into a single UI, reducing complexity for your applications while increasing usability. Credential Manager also supports passkeys, creating a unified interface for users and a single API for developers.
Instead of having to integrate with multiple identity providers, developers can now use Credential Manager as a single, unified authentication API. Credential Manager simplifies integration and makes it easier to develop authentication solutions that can work with all password managers, identity providers, and authentication methods.
Implementing Credential Manager with your Android applications will provide a single authentication experience for all Android users, integrated directly with the operating system and aligned with high-trust surfaces such as system login. We encourage all developers to migrate to Credential Manager.
Authentication APIs moving from Google Identity Services to Credential Manager on Android
Since these APIs are now generally available in Credential Manager, these individual APIs will be deprecated in Google Identity Services.
Removal of Smart Lock for Passwords
Smart Lock for Passwords, which was deprecated in 2022, will be removed from the Google Play Services SDK in November 2023. To minimize breaking changes that may impact existing integrations, all existing apps in the Play Store will continue to work. New app versions compiled with the new SDK will not be able to access the Smart Lock for Password API, so we encourage all developers to migrate to Credential Manager as soon as possible.
Get started with your migration to Credential Manager
All Android developers should plan their migration to the new Credential Manager API. To assist you in this process, read the following guides and resources:
UX guide for designing user experiences for passkeys on Android.
Share your feedback
We are excited to improve Android authentication with the launch of Credential Manager API, delivering a simple and streamlined UX for secure sign-in methods such as Sign in with Google.
We value your feedback and invite you to share your experience integrating with Credential Manager or any other feedback you might have:
Posted by Eliya Nachmani, Research Scientist, and Alon Levkovitch, Student Researcher, Google Research
The goal of natural language processing (NLP) is to develop computational models that can understand and generate natural language. By capturing the statistical patterns and structures of text-based natural language, language models can predict and generate coherent and meaningful sequences of words. Enabled by the increasing use of the highly successful Transformer model architecture and with training on large amounts of text (with proportionate compute and model size), large language models (LLMs) have demonstrated remarkable success in NLP tasks.
However, modeling spoken human language remains a challenging frontier. Spoken dialog systems have conventionally been built as a cascade of automatic speech recognition (ASR), natural language understanding (NLU), response generation, and text-to-speech (TTS) systems. However, to date there have been few capable end-to-end systems for the modeling of spoken language: i.e., single models that can take speech inputs and generate its continuation as speech outputs.
Today we present a new approach for spoken language modeling, called Spectron, published in “Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM.” Spectron is the first spoken language model that is trained end-to-end to directly process spectrograms as both input and output, instead of learning discrete speech representations. Using only a pre-trained text language model, it can be fine-tuned to generate high-quality, semantically accurate spoken language. Furthermore, the proposed model improves upon direct initialization in retaining the knowledge of the original LLM as demonstrated through spoken question answering datasets.
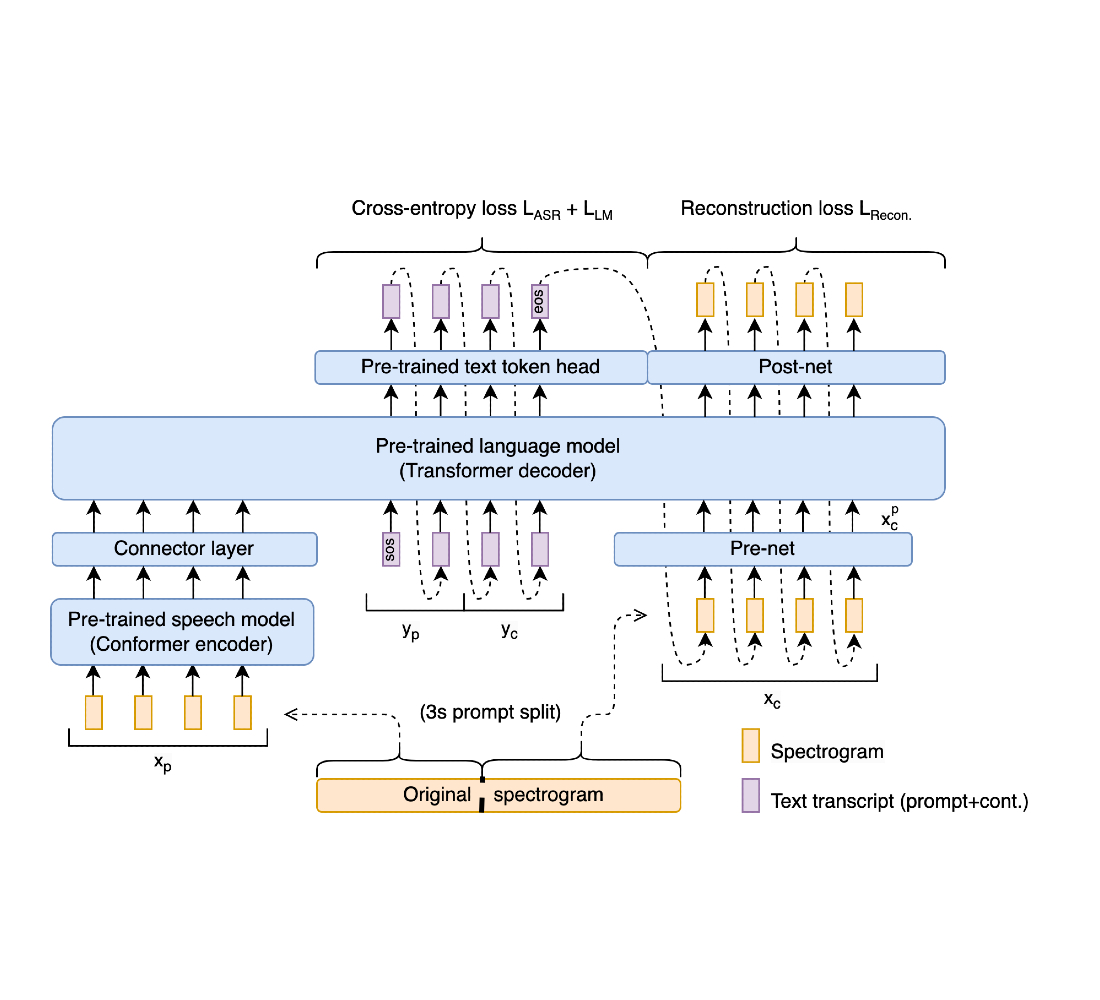
We show that a pre-trained speech encoder and a language model decoder enable end-to-end training and state-of-the-art performance without sacrificing representational fidelity. Key to this is a novel end-to-end training objective that implicitly supervises speech recognition, text continuation, and conditional speech synthesis in a joint manner. A new spectrogram regression loss also supervises the model to match the higher-order derivatives of the spectrogram in the time and frequency domain. These derivatives express information aggregated from multiple frames at once. Thus, they express rich, longer-range information about the shape of the signal. Our overall scheme is summarized in the following figure:
The Spectron model connects the encoder of a speech recognition model with a pre-trained Transformer-based decoder language model. At training, speech utterances split into a prompt and its continuation. Then the full transcript (prompt and continuation) is reconstructed along with the continuation’s speech features. At inference, only a prompt is provided; the prompt’s transcription, text continuation, and speech continuations are all generated by the model.
Spectron architecture
The architecture is initialized with a pre-trained speech encoder and a pre-trained decoder language model. The encoder is prompted with a speech utterance as input, which it encodes into continuous linguistic features. These features feed into the decoder as a prefix, and the whole encoder-decoder is optimized to jointly minimize a cross-entropy loss (for speech recognition and transcript continuation) and a novel reconstruction loss (for speech continuation). During inference, one provides a spoken speech prompt, which is encoded and then decoded to give both text and speech continuations.
Speech encoder
The speech encoder is a 600M-parameter conformer encoder pre-trained on large-scale data (12M hours). It takes the spectrogram of the source speech as input, generating a hidden representation that incorporates both linguistic and acoustic information. The input spectrogram is first subsampled using a convolutional layer and then processed by a series of conformer blocks. Each conformer block consists of a feed-forward layer, a self-attention layer, a convolution layer, and a second feed-forward layer. The outputs are passed through a projection layer to match the hidden representations to the embedding dimension of the language model.
Language model
We use a 350M or 1B parameter decoder language model (for the continuation and question-answering tasks, respectively) trained in the manner of PaLM 2. The model receives the encoded features of the prompt as a prefix. Note that this is the only connection between the speech encoder and the LM decoder; i.e., there is no cross-attention between the encoder and the decoder. Unlike most spoken language models, during training, the decoder is teacher-forced to predict the text transcription, text continuation, and speech embeddings. To convert the speech embeddings to and from spectrograms, we introduce lightweight modules pre- and post-network.
By having the same architecture decode the intermediate text and the spectrograms, we gain two benefits. First, the pre-training of the LM in the text domain allows continuation of the prompt in the text domain before synthesizing the speech. Secondly, the predicted text serves as intermediate reasoning, enhancing the quality of the synthesized speech, analogous to improvements in text-based language models when using intermediate scratchpads or chain-of-thought (CoT) reasoning.
Acoustic projection layers
To enable the language model decoder to model spectrogram frames, we employ a multi-layer perceptron “pre-net” to project the ground truth spectrogram speech continuations to the language model dimension. This pre-net compresses the spectrogram input into a lower dimension, creating a bottleneck that aids the decoding process. This bottleneck mechanism prevents the model from repetitively generating the same prediction in the decoding process. To project the LM output from the language model dimension to the spectrogram dimension, the model employs a “post-net”, which is also a multi-layer perceptron. Both pre- and post-networks are two-layer multi-layer perceptrons.
Training objective
The training methodology of Spectron uses two distinct loss functions: (i) cross-entropy loss, employed for both speech recognition and transcript continuation, and (ii) regression loss, employed for speech continuation. During training, all parameters are updated (speech encoder, projection layer, LM, pre-net, and post-net).
Audio samples
Following are examples of speech continuation and question answering from Spectron:
Speech Continuation
Prompt:
Continuation:
Prompt:
Continuation:
Prompt:
Continuation:
Prompt:
Continuation:
Question Answering
Question:
Answer:
Question:
Answer:
Performance
To empirically evaluate the performance of the proposed approach, we conducted experiments on the Libri-Light dataset. Libri-Light is a 60k hour English dataset consisting of unlabelled speech readings from LibriVox audiobooks. We utilized a frozen neural vocoder called WaveFit to convert the predicted spectrograms into raw audio. We experiment with two tasks, speech continuation and spoken question answering (QA). Speech continuation quality is tested on the LibriSpeech test set. Spoken QA is tested on the Spoken WebQuestions datasets and a new test set named LLama questions, which we created. For all experiments, we use a 3 second audio prompt as input. We compare our method against existing spoken language models: AudioLM, GSLM, TWIST and SpeechGPT. For the speech continuation task, we use the 350M parameter version of LM and the 1B version for the spoken QA task.
For the speech continuation task, we evaluate our method using three metrics. The first is log-perplexity, which uses an LM to evaluate the cohesion and semantic quality of the generated speech. The second is mean opinion score (MOS), which measures how natural the speech sounds to human evaluators. The third, speaker similarity, uses a speaker encoder to measure how similar the speaker in the output is to the speaker in the input. Performance in all 3 metrics can be seen in the following graphs.
Log-perplexity for completions of LibriSpeech utterances given a 3-second prompt. Lower is better.
Speaker similarity between the prompt speech and the generated speech using the speaker encoder. Higher is better.
MOS given by human users on speech naturalness. Raters rate 5-scale subjective mean opinion score (MOS) ranging between 0 - 5 in naturalness given a speech utterance. Higher is better.
As can be seen in the first graph, our method significantly outperforms GSLM and TWIST on the log-perplexity metric, and does slightly better than state-of-the-art methods AudioLM and SpeechGPT. In terms of MOS, Spectron exceeds the performance of all the other methods except for AudioLM. In terms of speaker similarity, our method outperforms all other methods.
To evaluate the ability of the models to perform question answering, we use two spoken question answering datasets. The first is the LLama Questions dataset, which uses general knowledge questions in different domains generated using the LLama2 70B LLM. The second dataset is the WebQuestions dataset which is a general question answering dataset. For evaluation we use only questions that fit into the 3 second prompt length. To compute accuracy, answers are transcribed and compared to the ground truth answers in text form.
Accuracy for Question Answering on the LLama Questions and Spoken WebQuestions datasets. Accuracy is computed using the ASR transcripts of spoken answers.
First, we observe that all methods have more difficulty answering questions from the Spoken WebQuestions dataset than from the LLama questions dataset. Second, we observe that methods centered around spoken language modeling such as GSLM, AudioLM and TWIST have a completion-centric behavior rather than direct question answering which hindered their ability to perform QA. On the LLama questions dataset our method outperforms all other methods, while SpeechGPT is very close in performance. On the Spoken WebQuestions dataset, our method outperforms all other methods except for SpeechGPT, which does marginally better.
Acknowledgements
The direct contributors to this work include Eliya Nachmani, Alon Levkovitch, Julian Salazar, Chulayutsh Asawaroengchai, Soroosh Mariooryad, RJ Skerry-Ryan and Michelle Tadmor Ramanovich. We also thank Heiga Zhen, Yifan Ding, Yu Zhang, Yuma Koizumi, Neil Zeghidour, Christian Frank, Marco Tagliasacchi, Nadav Bar, Benny Schlesinger and Blaise Aguera-Arcas.
The Beta channel has been updated to 119.0.6045.59 for Windows, Mac and Linux.
A partial list of changes is available in the Git log. Interested in switching release channels? Find out how. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
Fitbit has been used in over 1,700 research studies. Take a look at some of the most interesting findings related to Fitbit, physical activity and your health
Mihai Maruseac, Sarah Meiklejohn, Mark Lodato, Google Open Source Security Team (GOSST)
New AI innovations and applications are reaching consumers and businesses on an almost-daily basis. Building AI securely is a paramount concern, and we believe that Google’s Secure AI Framework (SAIF) can help chart a path for creating AI applications that users can trust. Today, we’re highlighting two new ways to make information about AI supply chain security universally discoverable and verifiable, so that AI can be created and used responsibly.
The first principle of SAIF is to ensure that the AI ecosystem has strong security foundations. In particular, the software supply chains for components specific to AI development, such as machine learning models, need to be secured against threats including model tampering, data poisoning, and the production of harmful content.
Even as machine learning and artificial intelligence continue to evolve rapidly, some solutions are now within reach of ML creators. We’re building on our prior work with the Open Source Security Foundation to show how ML model creators can and should protect against ML supply chain attacks by using SLSA and Sigstore.
Supply chain security for ML
For supply chain security of conventional software (software that does not use ML), we usually consider questions like:
Who published the software? Are they trustworthy? Did they use safe practices?
For open source software, what was the source code?
What dependencies went into building that software?
Could the software have been replaced by a tampered version following publication? Could this have occurred during build time?
All of these questions also apply to the hundreds of free ML models that are available for use on the internet. Using an ML model means trusting every part of it, just as you would any other piece of software. This includes concerns such as:
Who published the model? Are they trustworthy? Did they use safe practices?
For open source models, what was the training code?
What datasets went into training that model?
Could the model have been replaced by a tampered version following publication? Could this have occurred during training time?
We should treat tampering of ML models with the same severity as we treat injection of malware into conventional software. In fact, since models are programs, many allow the same types of arbitrary code execution exploits that are leveraged for attacks on conventional software. Furthermore, a tampered model could leak or steal data, cause harm from biases, or spread dangerous misinformation.
Inspection of an ML model is insufficient to determine whether bad behaviors were injected. This is similar to trying to reverse engineer an executable to identify malware. To protect supply chains at scale, we need to know how the model or software was created to answer the questions above.
Solutions for ML supply chain security
In recent years, we’ve seen how providing public and verifiable information about what happens during different stages of software development is an effective method of protecting conventional software against supply chain attacks. This supply chain transparency offers protection and insights with:
Digital signatures, such as those from Sigstore, which allow users to verify that the software wasn’t tampered with or replaced
Metadata such as SLSA provenance that tell us what’s in software and how it was built, allowing consumers to ensure license compatibility, identify known vulnerabilities, and detect more advanced threats
Together, these solutions help combat the enormous uptick in supply chain attacks that have turned every step in the software development lifecycle into a potential target for malicious activity.
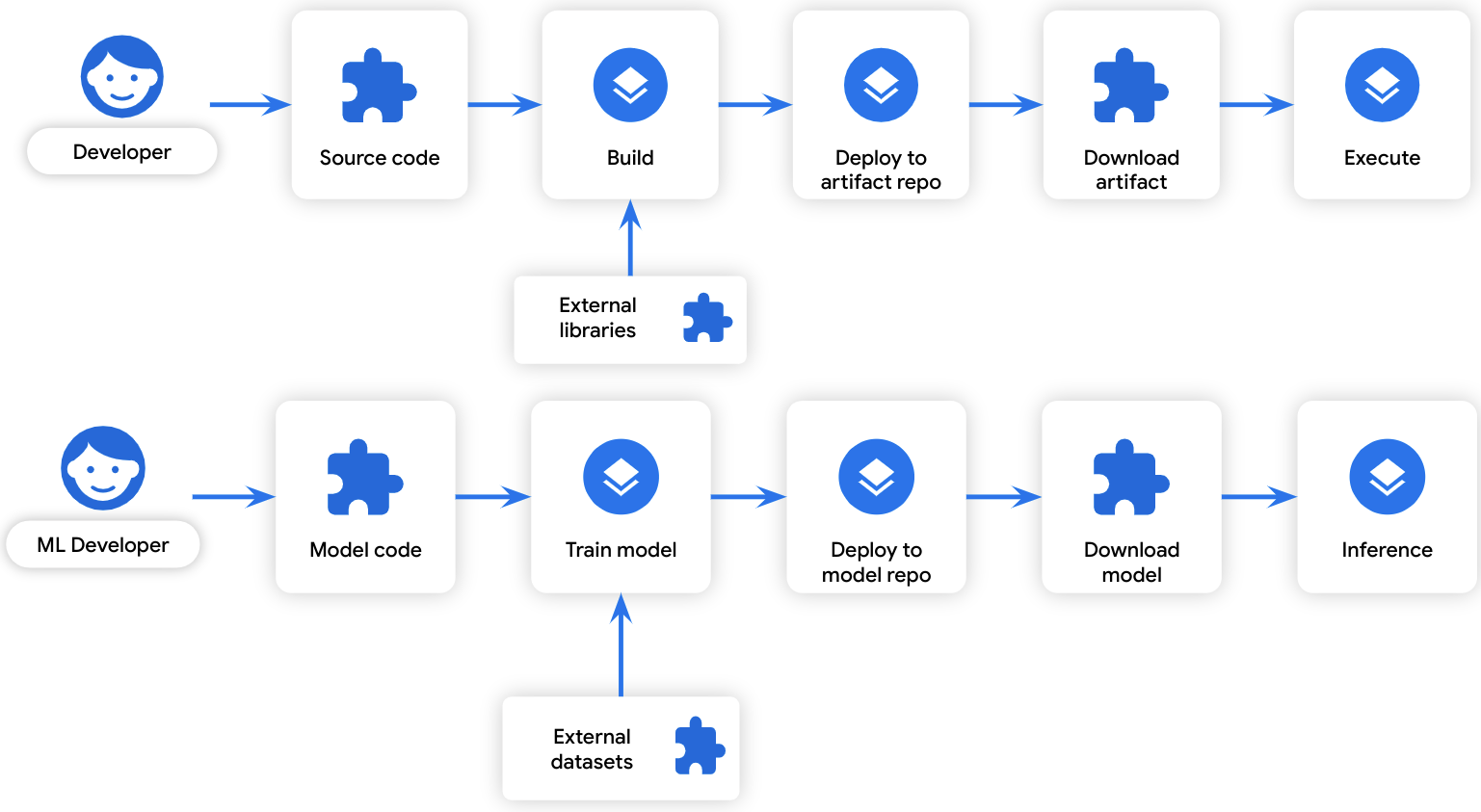
We believe transparency throughout the development lifecycle will also help secure ML models, since ML model development follows a similar lifecycle as for regular software artifacts:
Similarities between software development and ML model development
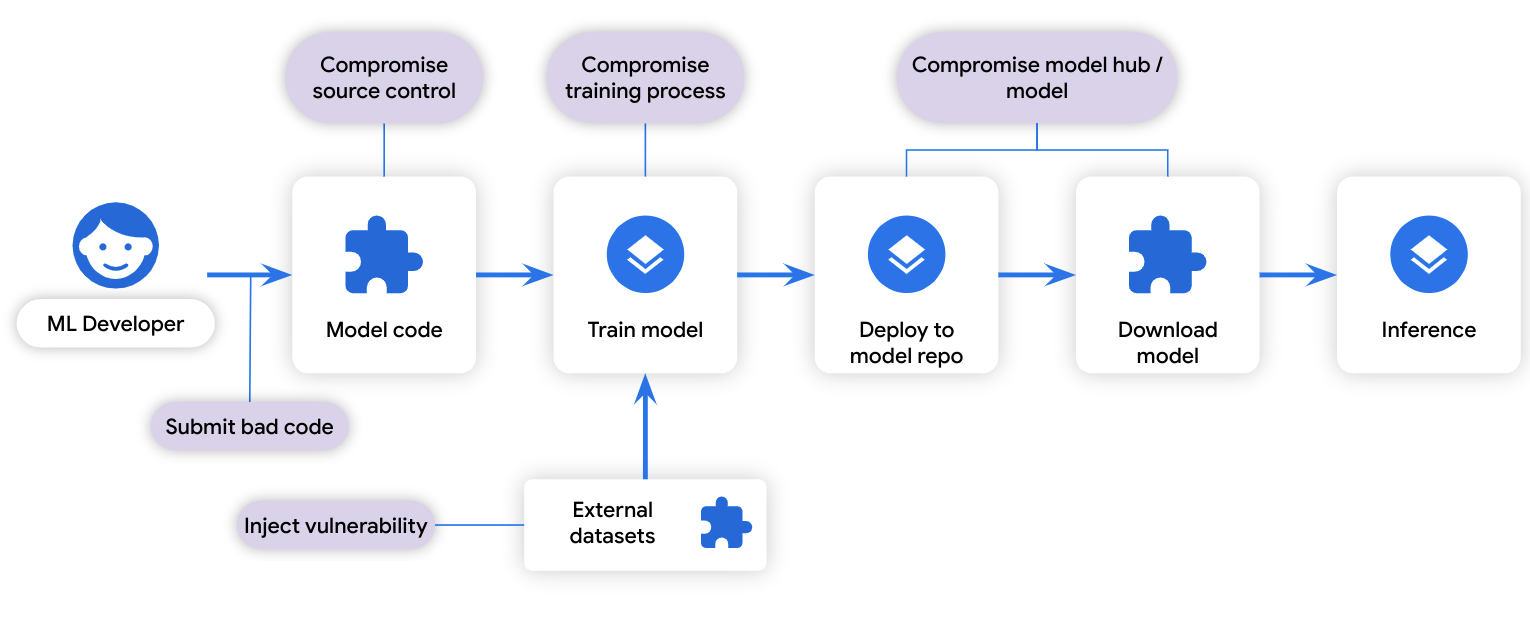
An ML training process can be thought of as a “build:” it transforms some input data to some output data. Similarly, training data can be thought of as a “dependency:” it is data that is used during the build process. Because of the similarity in the development lifecycles, the same software supply chain attack vectors that threaten software development also apply to model development:
Attack vectors on ML through the lens of the ML supply chain
Based on the similarities in development lifecycle and threat vectors, we propose applying the same supply chain solutions from SLSA and Sigstore to ML models to similarly protect them against supply chain attacks.
Sigstore for ML models
Code signing is a critical step in supply chain security. It identifies the producer of a piece of software and prevents tampering after publication. But normally code signing is difficult to set up—producers need to manage and rotate keys, set up infrastructure for verification, and instruct consumers on how to verify. Often times secrets are also leaked since security is hard to get right during the process.
We suggest bypassing these challenges by using Sigstore, a collection of tools and services that make code signing secure and easy. Sigstore allows any software producer to sign their software by simply using an OpenID Connect token bound to either a workload or developer identity—all without the need to manage or rotate long-lived secrets.
So how would signing ML models benefit users? By signing models after training, we can assure users that they have the exact model that the builder (aka “trainer”) uploaded. Signing models discourages model hub owners from swapping models, addresses the issue of a model hub compromise, and can help prevent users from being tricked into using a bad model.
Model signatures make attacks similar to PoisonGPT detectable. The tampered models will either fail signature verification or can be directly traced back to the malicious actor. Our current work to encourage this industry standard includes:
Having ML frameworks integrate signing and verification in the model save/load APIs
Having ML model hubs add a badge to all signed models, thus guiding users towards signed models and incentivizing signatures from model developers
Scaling model signing for LLMs
SLSA for ML Supply Chain Integrity
Signing with Sigstore provides users with confidence in the models that they are using, but it cannot answer every question they have about the model. SLSA goes a step further to provide more meaning behind those signatures.
SLSA (Supply-chain Levels for Software Artifacts) is a specification for describing how a software artifact was built. SLSA-enabled build platforms implement controls to prevent tampering and output signed provenance describing how the software artifact was produced, including all build inputs. This way, SLSA provides trustworthy metadata about what went into a software artifact.
Applying SLSA to ML could provide similar information about an ML model’s supply chain and address attack vectors not covered by model signing, such as compromised source control, compromised training process, and vulnerability injection.Our vision is to include specific ML information in a SLSA provenance file, which would help users spot an undertrained model or one trained on bad data. Upon detecting a vulnerability in an ML framework, users can quickly identify which models need to be retrained, thus reducing costs.
We don’t need special ML extensions for SLSA. Since an ML training process is a build (shown in the earlier diagram), we can apply the existing SLSA guidelines to ML training. The ML training process should be hardened against tampering and output provenance just like a conventional build process. More work on SLSA is needed to make it fully useful and applicable to ML, particularly around describing dependencies such as datasets and pretrained models. Most of these efforts will also benefit conventional software.
For models training on pipelines that do not require GPUs/TPUs, using an existing, SLSA-enabled build platform is a simple solution. For example, Google Cloud Build, GitHub Actions, or GitLab CI are all generally available SLSA-enabled build platforms. It is possible to run an ML training step on one of these platforms to make all of the built-in supply chain security features available to conventional software.
How to do model signing and SLSA for ML today
By incorporating supply chain security into the ML development lifecycle now, while the problem space is still unfolding, we can jumpstart work with the open source community to establish industry standards to solve pressing problems. This effort is already underway and available for testing.
Our repository of tooling for model signing and experimental SLSA provenance support for smaller ML models is available now. Our future ML framework and model hub integrations will be released in this repository as well.
We welcome collaboration with the ML community and are looking forward to reaching consensus on how to best integrate supply chain protection standards into existing tooling (such as Model Cards). If you have feedback or ideas, please feel free to open an issue and let us know.
Eduardo Vela, Jan Keller and Ryan Rinaldi, Google Engineering
In September, we shared how we are implementing the voluntary AI commitments that we and others in industry made at the White House in July. One of the most important developments involves expanding our existing Bug Hunter Program to foster third-party discovery and reporting of issues and vulnerabilities specific to our AI systems. Today, we’re publishing more details on these new reward program elements for the first time. Last year we issued over $12 million in rewards to security researchers who tested our products for vulnerabilities, and we expect today’s announcement to fuel even greater collaboration for years to come.
What’s in scope for rewards
In our recent AI Red Team report, we identified common tactics, techniques, and procedures (TTPs) that we consider most relevant and realistic for real-world adversaries to use against AI systems. The following table incorporates shared learnings from Google’s AI Red Team exercises to help the research community better understand what’s in scope for our reward program. We're detailing our criteria for AI bug reports to assist our bug hunting community in effectively testing the safety and security of AI products. Our scope aims to facilitate testing for traditional security vulnerabilities as well as risks specific to AI systems. It is important to note that reward amounts are dependent on severity of the attack scenario and the type of target affected (go here for more information on our reward table).
Category
Attack Scenario
Guidance
Prompt Attacks: Crafting adversarial prompts that allow an adversary to influence the behavior of the model, and hence the output in ways that were not intended by the application.
Prompt injections that are invisible to victims and change the state of the victim's account or or any of their assets.
In Scope
Prompt injections into any tools in which the response is used to make decisions that directly affect victim users.
In Scope
Prompt or preamble extraction in which a user is able to extract the initial prompt used to prime the model only when sensitive information is present in the extracted preamble.
In Scope
Using a product to generate violative, misleading, or factually incorrect content in your own session: e.g. 'jailbreaks'. This includes 'hallucinations' and factually inaccurate responses. Google's generative AI products already have a dedicated reporting channel for these types of content issues.
Out of Scope
Training Data Extraction: Attacks that are able to successfully reconstruct verbatim training examples that contain sensitive information. Also called membership inference.
Training data extraction that reconstructs items used in the training data set that leak sensitive, non-public information.
In Scope
Extraction that reconstructs nonsensitive/public information.
Out of Scope
Manipulating Models: An attacker able to covertly change the behavior of a model such that they can trigger pre-defined adversarial behaviors.
Adversarial output or behavior that an attacker can reliably trigger via specific input in a model owned and operated by Google ("backdoors"). Only in-scope when a model's output is used to change the state of a victim's account or data.
In Scope
Attacks in which an attacker manipulates the training data of the model to influence the model’s output in a victim's session according to the attacker’s preference. Only in-scope when a model's output is used to change the state of a victim's account or data.
In Scope
Adversarial Perturbation: Inputs that are provided to a model that results in a deterministic, but highly unexpected output from the model.
Contexts in which an adversary can reliably trigger a misclassification in a security control that can be abused for malicious use or adversarial gain.
In Scope
Contexts in which a model's incorrect output or classification does not pose a compelling attack scenario or feasible path to Google or user harm.
Out of Scope
Model Theft / Exfiltration: AI models often include sensitive intellectual property, so we place a high priority on protecting these assets. Exfiltration attacks allow attackers to steal details about a model such as its architecture or weights.
Attacks in which the exact architecture or weights of a confidential/proprietary model are extracted.
In Scope
Attacks in which the architecture and weights are not extracted precisely, or when they're extracted from a non-confidential model.
Out of Scope
If you find a flaw in an AI-powered tool other than what is listed above, you can still submit, provided that it meets the qualifications listed on our program page.
A bug or behavior that clearly meets our qualifications for a valid security or abuse issue.
In Scope
Using an AI product to do something potentially harmful that is already possible with other tools. For example, finding a vulnerability in open source software (already possible using publicly-available static analysis tools) and producing the answer to a harmful question when the answer is already available online.
Out of Scope
As consistent with our program, issues that we already know about are not eligible for reward.
Out of Scope
Potential copyright issues: findings in which products return content appearing to be copyright-protected. Google's generative AI products already have a dedicated reporting channel for these types of content issues.
Out of Scope
Conclusion
We look forward to continuing our work with the research community to discover and fix security and abuse issues in our AI-powered features. If you find a qualifying issue, please go to our Bug Hunter website to send us your bug report and–if the issue is found to be valid–be rewarded for helping us keep our users safe.
 Posted by Amy Zeppenfeld – Developer Relations Engineer
Posted by Amy Zeppenfeld – Developer Relations Engineer

 Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
 From London to San Francisco to more than 500 cities around the world, here are the ways we are making digital payments a reality for commuters.
From London to San Francisco to more than 500 cities around the world, here are the ways we are making digital payments a reality for commuters.





 New AI-powered Google Maps features include Immersive View for Routes, Lens in Maps, visual ways to search, navigation updates and more.
New AI-powered Google Maps features include Immersive View for Routes, Lens in Maps, visual ways to search, navigation updates and more.