
Posted by Jaclyn Konzelmann and Megan Li - Google Labs

Grab an API key in Google AI Studio, and get started with the Gemini API Cookbook
Less than two months ago, we made our next-generation Gemini 1.5 Pro model available in Google AI Studio for developers to try out. We’ve been amazed by what the community has been able to debug, create and learn using our groundbreaking 1 million context window.
Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio (speech) understanding capability and a new File API to make it easy to handle files. We’re also launching new features like system instructions and JSON mode to give developers more control over the model’s output. Lastly, we’re releasing our next generation text embedding model that outperforms comparable models. Go to Google AI Studio to create or access your API key, and start building.
Unlock new use cases with audio and video modalities
We’re expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
 |
| You can upload a recording of a lecture, like this 117,000+ token lecture from Jeff Dean, and Gemini 1.5 Pro can turn it into a quiz with an answer key. Video sped up for demo purposes. |
Gemini API Improvements
Today, we’re addressing a number of top developer requests:
1. System instructions: Guide the model’s responses with system instructions, now available in Google AI Studio and the Gemini API. Define roles, formats, goals, and rules to steer the model's behavior for your specific use case.
Set System Instructions easily in Google AI Studio
2. JSON mode: Instruct the model to only output JSON objects. This mode enables structured data extraction from text or images. You can get started with cURL, and Python SDK support is coming soon.
3. Improvements to function calling: You can now select modes to limit the model’s outputs, improving reliability. Choose text, function call, or just the function itself.

A new embedding model with improved performance
Starting today, developers will be able to access our next generation text embedding model via the Gemini API. The new model, text-embedding-004, (text-embedding-preview-0409 in Vertex AI), achieves a stronger retrieval performance and outperforms existing models with comparable dimensions, on the MTEB benchmarks.
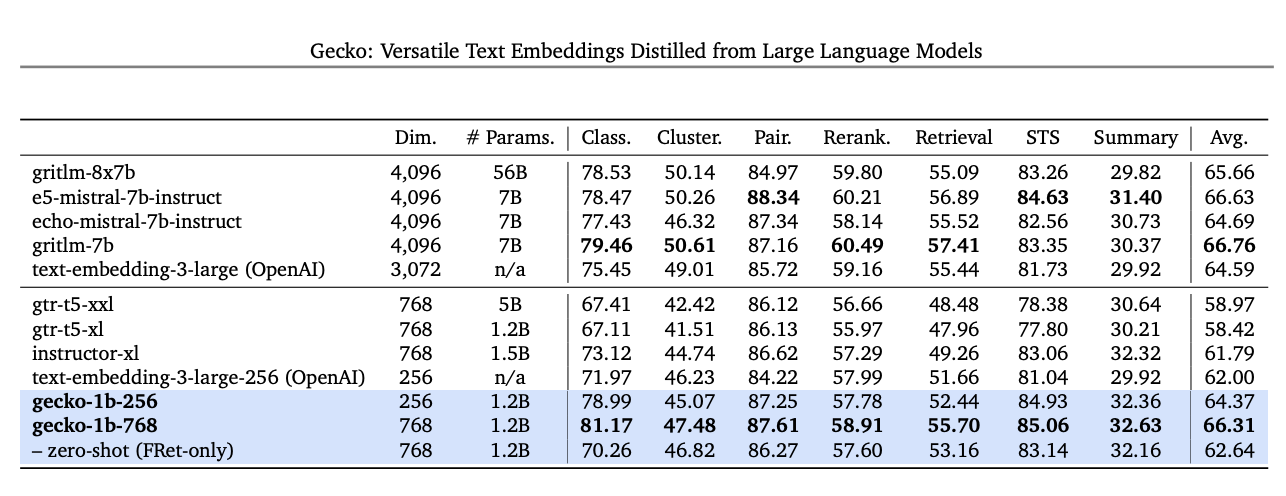 |
| 'Text-embedding-004' (aka Gecko) using 256 dims output outperforms all larger 768 dim output models on MTEB benchmarks |
These are just the first of many improvements coming to the Gemini API and Google AI Studio in the next few weeks. We’re continuing to work on making Google AI Studio and the Gemini API the easiest way to build with Gemini. Get started today in Google AI Studio with Gemini 1.5 Pro, explore code examples and quickstarts in our new Gemini API Cookbook, and join our community channel on Discord.
 Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager
Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager


