Anomaly detection (AD), the task of distinguishing anomalies from normal data, plays a vital role in many real-world applications, such as detecting faulty products from vision sensors in manufacturing, fraudulent behaviors in financial transactions, or network security threats. Depending on the availability of the type of data — negative (normal) vs. positive (anomalous) and the availability of their labels — the task of AD involves different challenges.
 |
| (a) Fully supervised anomaly detection, (b) normal-only anomaly detection, (c, d, e) semi-supervised anomaly detection, (f) unsupervised anomaly detection. |
While most previous works were shown to be effective for cases with fully-labeled data (either (a) or (b) in the above figure), such settings are less common in practice because labels are particularly tedious to obtain. In most scenarios users have a limited labeling budget, and sometimes there aren’t even any labeled samples during training. Furthermore, even when labeled data are available, there could be biases in the way samples are labeled, causing distribution differences. Such real-world data challenges limit the achievable accuracy of prior methods in detecting anomalies.
This post covers two of our recent papers on AD, published in Transactions on Machine Learning Research (TMLR), that address the above challenges in unsupervised and semi-supervised settings. Using data-centric approaches, we show state-of-the-art results in both. In “Self-supervised, Refine, Repeat: Improving Unsupervised Anomaly Detection”, we propose a novel unsupervised AD framework that relies on the principles of self-supervised learning without labels and iterative data refinement based on the agreement of one-class classifier (OCC) outputs. In “SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch”, we propose a novel semi-supervised AD framework that yields robust performance even under distribution mismatch with limited labeled samples.
Unsupervised anomaly detection with SRR: Self-supervised, Refine, Repeat
Discovering a decision boundary for a one-class (normal) distribution (i.e., OCC training) is challenging in fully unsupervised settings as unlabeled training data include two classes (normal and abnormal). The challenge gets further exacerbated as the anomaly ratio gets higher for unlabeled data. To construct a robust OCC with unlabeled data, excluding likely-positive (anomalous) samples from the unlabeled data, the process referred to as data refinement, is critical. The refined data, with a lower anomaly ratio, are shown to yield superior anomaly detection models.
SRR first refines data from an unlabeled dataset, then iteratively trains deep representations using refined data while improving the refinement of unlabeled data by excluding likely-positive samples. For data refinement, an ensemble of OCCs is employed, each of which is trained on a disjoint subset of unlabeled training data. If there is consensus among all the OCCs in the ensemble, the data that are predicted to be negative (normal) are included in the refined data. Finally, the refined training data are used to train the final OCC to generate the anomaly predictions.
 |
| Training SRR with a data refinement module (OCCs ensemble), representation learner, and final OCC. (Green/red dots represent normal/abnormal samples, respectively). |
SRR results
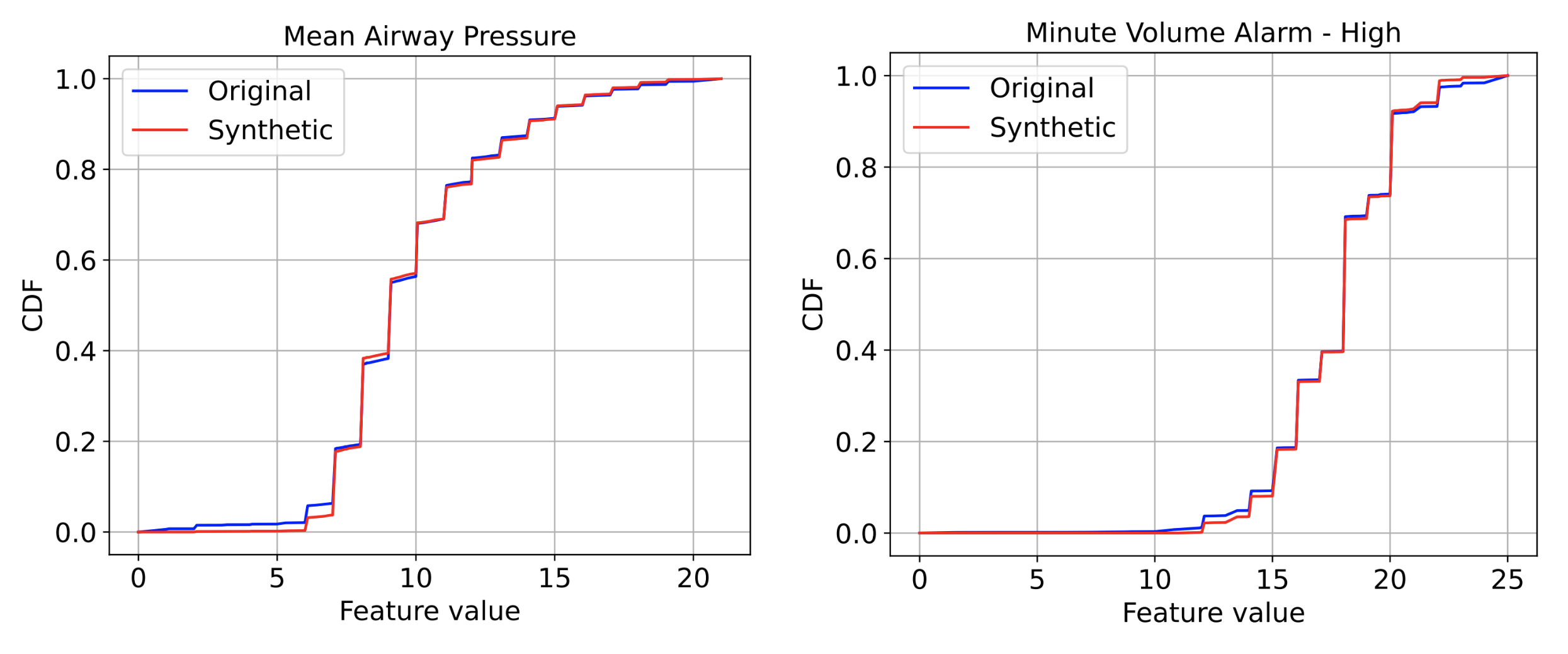
We conduct extensive experiments across various datasets from different domains, including semantic AD (CIFAR-10, Dog-vs-Cat), real-world manufacturing visual AD (MVTec), and real-world tabular AD benchmarks such as detecting medical (Thyroid) or network security (KDD 1999) anomalies. We consider methods with both shallow (e.g., OC-SVM) and deep (e.g., GOAD, CutPaste) models. Since the anomaly ratio of real-world data can vary, we evaluate models at different anomaly ratios of unlabeled training data and show that SRR significantly boosts AD performance. For example, SRR improves more than 15.0 average precision (AP) with a 10% anomaly ratio compared to a state-of-the-art one-class deep model on CIFAR-10. Similarly, on MVTec, SRR retains solid performance, dropping less than 1.0 AUC with a 10% anomaly ratio, while the best existing OCC drops more than 6.0 AUC. Lastly, on Thyroid (tabular data), SRR outperforms a state-of-the-art one-class classifier by 22.9 F1 score with a 2.5% anomaly ratio.
.png) |
| Across various domains, SRR (blue line) significantly boosts AD performance with various anomaly ratios in fully unsupervised settings. |
SPADE: Semi-supervised Pseudo-labeler Anomaly Detection with Ensembling
Most semi-supervised learning methods (e.g., FixMatch, VIME) assume that the labeled and unlabeled data come from the same distributions. However, in practice, distribution mismatch commonly occurs, with labeled and unlabeled data coming from different distributions. One such case is positive and unlabeled (PU) or negative and unlabeled (NU) settings, where the distributions between labeled (either positive or negative) and unlabeled (both positive and negative) samples are different. Another cause of distribution shift is additional unlabeled data being gathered after labeling. For example, manufacturing processes may keep evolving, causing the corresponding defects to change and the defect types at labeling to differ from the defect types in unlabeled data. In addition, for applications like financial fraud detection and anti-money laundering, new anomalies can appear after the data labeling process, as criminal behavior may adapt. Lastly, labelers are more confident on easy samples when they label them; thus, easy/difficult samples are more likely to be included in the labeled/unlabeled data. For example, with some crowd-sourcing–based labeling, only the samples with some consensus on the labels (as a measure of confidence) are included in the labeled set.
 |
| Three common real-world scenarios with distribution mismatches (blue box: normal samples, red box: known/easy anomaly samples, yellow box: new/difficult anomaly samples). |
Standard semi-supervised learning methods assume that labeled and unlabeled data come from the same distribution, so are sub-optimal for semi-supervised AD under distribution mismatch. SPADE utilizes an ensemble of OCCs to estimate the pseudo-labels of the unlabeled data — it does this independent of the given positive labeled data, thus reducing the dependency on the labels. This is especially beneficial when there is a distribution mismatch. In addition, SPADE employs partial matching to automatically select the critical hyper-parameters for pseudo-labeling without relying on labeled validation data, a crucial capability given limited labeled data.
 |
| Block diagram of SPADE with zoom in the detailed block diagram of the proposed pseudo-labelers. |
SPADE results
We conduct extensive experiments to showcase the benefits of SPADE in various real-world settings of semi-supervised learning with distribution mismatch. We consider multiple AD datasets for image (including MVTec) and tabular (including Covertype, Thyroid) data.
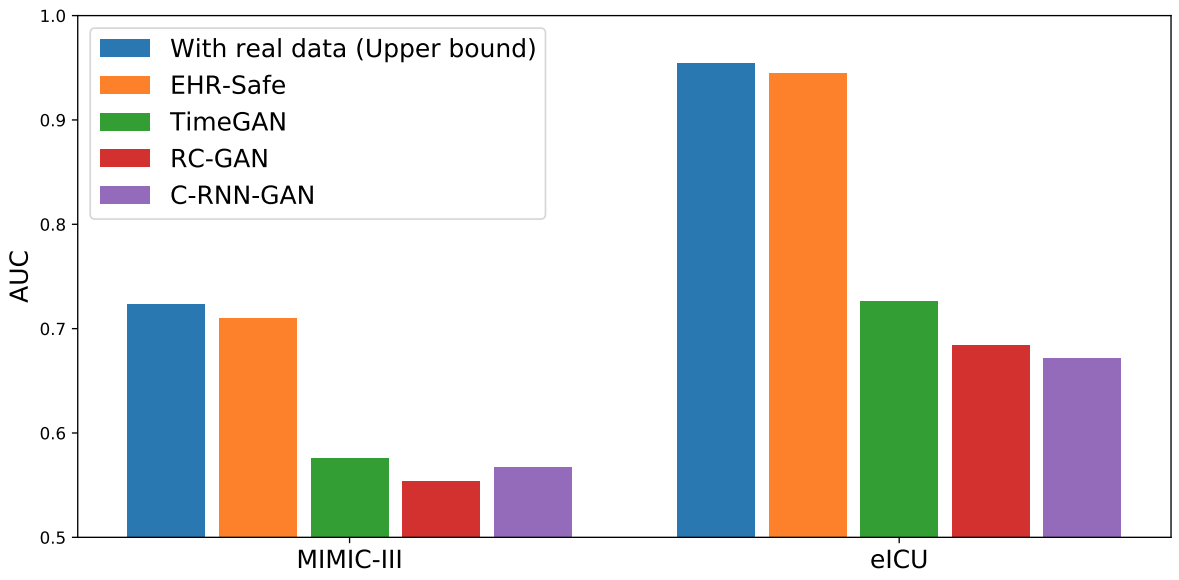
SPADE shows state-of-the-art semi-supervised anomaly detection performance across a wide range of scenarios: (i) new-types of anomalies, (ii) easy-to-label samples, and (iii) positive-unlabeled examples. As shown below, with new-types of anomalies, SPADE outperforms the state-of-the-art alternatives by 5% AUC on average.
 |
| AD performances with three different scenarios across various datasets (Covertype, MVTec, Thyroid) in terms of AUC. Some baselines are only applicable to some scenarios. More results with other baselines and datasets can be found in the paper. |
We also evaluate SPADE on real-world financial fraud detection datasets: Kaggle credit card fraud and Xente fraud detection. For these, anomalies evolve (i.e., their distributions change over time) and to identify evolving anomalies, we need to keep labeling for new anomalies and retrain the AD model. However, labeling would be costly and time consuming. Even without additional labeling, SPADE can improve the AD performance using both labeled data and newly-gathered unlabeled data.
 |
| AD performances with time-varying distributions using two real-world fraud detection datasets with 10% labeling ratio. More baselines can be found in the paper. |
As shown above, SPADE consistently outperforms alternatives on both datasets, taking advantage of the unlabeled data and showing robustness to evolving distributions.
Conclusions
AD has a wide range of use cases with significant importance in real-world applications, from detecting security threats in financial systems to identifying faulty behaviors of manufacturing machines.
One challenging and costly aspect of building an AD system is that anomalies are rare and not easily detectable by people. To this end, we have proposed SRR, a canonical AD framework to enable high performance AD without the need for manual labels for training. SRR can be flexibly integrated with any OCC, and applied on raw data or on trainable representations.
Semi-supervised AD is another highly-important challenge — in many scenarios, the distributions of labeled and unlabeled samples don’t match. SPADE introduces a robust pseudo-labeling mechanism using an ensemble of OCCs and a judicious way of combining supervised and self-supervised learning. In addition, SPADE introduces an efficient approach to pick critical hyperparameters without a validation set, a crucial component for data-efficient AD.
Overall, we demonstrate that SRR and SPADE consistently outperform the alternatives in various scenarios across multiple types of datasets.
Acknowledgements
We gratefully acknowledge the contributions of Kihyuk Sohn, Chun-Liang Li, Chen-Yu Lee, Kyle Ziegler, Nate Yoder, and Tomas Pfister.