Templatic documents, such as receipts, bills, insurance quotes, and others, are extremely common and critical in a diverse range of business workflows. Currently, processing these documents is largely a manual effort, and automated systems that do exist are based on brittle and error-prone heuristics. Consider a document type like invoices, which can be laid out in thousands of different ways — invoices from different companies, or even different departments within the same company, may have slightly different formatting. However, there is a common understanding of the structured information that an invoice should contain, such as an invoice number, an invoice date, the amount due, the pay-by date, and the list of items for which the invoice was sent. A system that can automatically extract all this data has the potential to dramatically improve the efficiency of many business workflows by avoiding error-prone, manual work.
In “Representation Learning for Information Extraction from Form-like Documents”, accepted to ACL 2020, we present an approach to automatically extract structured data from templatic documents. In contrast to previous work on extraction from plain-text documents, we propose an approach that uses knowledge of target field types to identify candidate fields. These are then scored using a neural network that learns a dense representation of each candidate using the words in its neighborhood. Experiments on two corpora (invoices and receipts) show that we’re able to generalize well to unseen layouts.
Why Is This Hard?
The challenge in this information extraction problem arises because it straddles the natural language processing (NLP) and computer vision worlds. Unlike classic NLP tasks, such documents do not contain “natural language” as might be found in regular sentences and paragraphs, but instead resemble forms. Data is often presented in tables, but in addition many documents have multiple pages, frequently with a varying number of sections, and have a variety of layout and formatting clues to organize the information. An understanding of the two-dimensional layout of text on the page is key to understanding such documents. On the other hand, treating this purely as an image segmentation problem makes it difficult to take advantage of the semantics of the text.
Solution Overview
Our approach to this problem allows developers to train and deploy an extraction system for a given domain (like invoices) using two inputs — a target schema (i.e., a list of fields to extract and their corresponding types) and a small collection of documents labeled with the ground truth for use as a training set. Supported field types include basics, such as dates, integers, alphanumeric codes, currency amounts, phone-numbers, and URLs. We also take advantage of entity types commonly detected by the Google Knowledge Graph, such as addresses, names of companies, etc.
The input document is first run through an Optical Character Recognition (OCR) service to extract the text and layout information, which allows this to work with native digital documents, such as PDFs, and document images (e.g., scanned documents). We then run a candidate generator that identifies spans of text in the OCR output that might correspond to an instance of a given field. The candidate generator utilizes pre-existing libraries associated with each field type (date, number, phone-number, etc.), which avoids the need to write new code for each candidate generator. Each of these candidates is then scored using a trained neural network (the “scorer”, described below) to estimate the likelihood that it is indeed a value one might extract for that field. Finally, an assigner module matches the scored candidates to the target fields. By default, the assigner simply chooses the highest scoring candidate for the field, but additional domain-specific constraints can be incorporated, such as requiring that the invoice date field is chronologically before the payment date field.
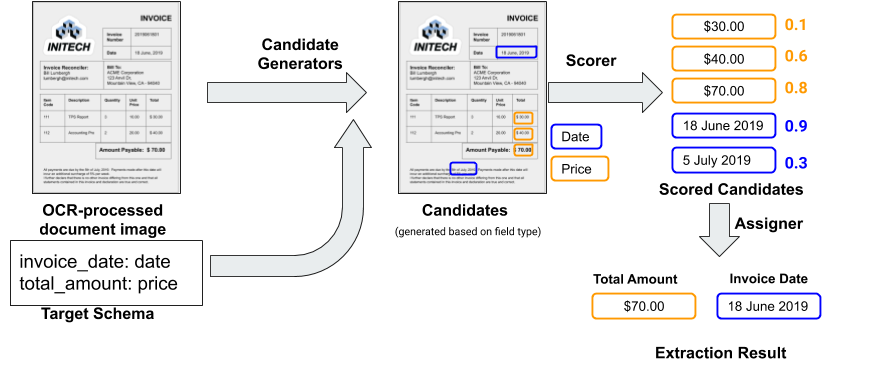 |
| The processing steps in the extraction system using a toy schema with two fields on an input invoice document. Blue boxes show the candidates for the invoice_date field and gold boxes for the amount_due field. |
The scorer is a neural model that is trained as a binary classifier. It takes as input the target field from the schema along with the extraction candidate and produces a prediction score between 0 and 1. The target label for a candidate is determined by whether the candidate matches the ground truth for that document and field. The model learns how to represent each field and each candidate in a vector space in which the nearer a field and candidate are in the vector space, the more likely it is that the candidate is the true extraction value for that field and document.
Candidate Representation
A candidate is represented by the tokens in its neighborhood along with the relative position of the token on the page with respect to the centroid of the bounding box identified for the candidate. Using the invoice_date field as an example, phrases in the neighborhood like “Invoice Date’” or “Inv Date” might indicate to the scorer that this is a likely candidate, while phrases like “Delivery Date” would indicate that this is likely not the invoice_date. We do not include the value of the candidate in its representation in order to avoid overfitting to values that happen to be present in a small training data set — e.g., “2019” for the invoice date, if the training corpus happened to include only invoices from that year.
 |
| A small snippet of an invoice. The green box shows a candidate for the invoice_date field, and the red box is a token in the neighborhood along with the arrow representing the relative position. Each of the other tokens (‘number’, ‘date’, ‘page’, ‘of’, etc along with the other occurrences of ‘invoice’) are part of the neighborhood for the invoice candidate. |
The figure below shows the general structure of the network. In order to construct the candidate encoding (i), each token in the neighborhood is embedded using a word embedding table (a). The relative position of each neighbor (b) is embedded using two fully connected ReLU layers that capture fine-grained non-linearities. The text and position embeddings for each neighbor are concatenated to form a neighbor encoding (d). A self attention mechanism is used to incorporate the neighborhood context for each neighbor (e), which is combined into a neighborhood encoding (f) using max-pooling. The absolute position of the candidate on the page (g) is embedded in a manner similar to the positional embedding for a neighbor, and concatenated with the neighborhood encoding for the candidate encoding (i). The final scoring layer computes the cosine similarity between the field embedding (k) and the candidate encoding (i) and then rescales it to be between 0 and 1.

Results
For training and validation, we used an internal dataset of invoices with a large variety of layouts. In order to test the ability of the model to generalize to unseen layouts, we used a test-set of invoices with layouts that were disjoint from the training and validation set. We report the F1 score of the extractions from this system on a few key fields below (higher is better):
| Field | F1 Score |
| amount_due | 0.801 |
| delivery_date | 0.667 |
| due_date | 0.861 |
| invoice_date | 0.940 |
| invoice_id | 0.949 |
| purchase_order | 0.896 |
| total_amount | 0.858 |
| total_tax_amount | 0.839 |
As you can see from the table above, the model does well on most fields. However, there’s room for improvement for fields like delivery_date. Additional investigation revealed that this field was present in a very small subset of the examples in our training data. We expect that gathering additional training data will help us improve on it.
What’s next?
Google Cloud recently announced an invoice parsing service as part of the Document AI product. The service uses the methods described above, along with other recent research breakthroughs like BERT, to extract more than a dozen key fields from invoices. You can upload an invoice at the demo page and see this technology in action!
For a given document type we expect to be able to build an extraction system given a modest sized labeled corpus. There are several follow-ons we are currently pursuing, including the improvement of data efficiency and accurately handling nested and repeated fields, and fields for which it is difficult to define a good candidate generator.
Acknowledgements
This work was a collaboration between Google Research and several engineers in Google Cloud. I’d like to thank Navneet Potti, James Wendt, Marc Najork, Qi Zhao, and Ivan Kuznetsov in Google Research as well as Lauro Costa, Evan Huang, Will Lu, Lukas Rutishauser, Mu Wang, and Yang Xu on the Cloud AI team for their support. And finally, our research interns Bodhisattwa Majumder and Beliz Gunel for their tireless experimentation on dozens of ideas.
