Getting started
Getting started with Node.js on App Engine is easy. We’ve built a collection of getting started guides, samples, and interactive tutorials that walk you through creating your code, using our APIs and services and deploying to production.
When running Node.js on App Engine, you can use the tools and databases you already know and love. Use Express, Hapi, Parse-server or any other web server to build your app. Use MongoDB, Redis, or Google Cloud Datastore to store your data. The runtime is flexible enough to manage most applications and services — but if you want more control over the underlying infrastructure, you can easily migrate to Google Container Engine or Google Compute Engine for full flexibility and control.
Using the gcloud npm module, you can take advantage of Google’s advanced APIs and services, including Google BigQuery, Google Cloud Pub/Sub, and the Google Cloud Vision API:
var gcloud = require('gcloud')({
projectId: 'my-project',
keyFilename: 'keyfile.json'
});
var vision = gcloud.vision();
vision.detectText('./image.jpg', function(err, text) {
if (text.length > 0) {
console.log('We found text on this image...');
}
});
Services like the Vision API allow you to take advantage of Google’s unique technology in the cloud to bring life to your applications.
Advanced diagnostic tooling
Deploying Node.js applications to Cloud Platform is just the first step. During the lifespan of any application, you’ll need the ability to diagnose issues in production. Google Cloud Debugger lets you inspect the state of Node.js applications at any code location without stopping or slowing it down. You can set breakpoints, and analyze the state of your application in real time:
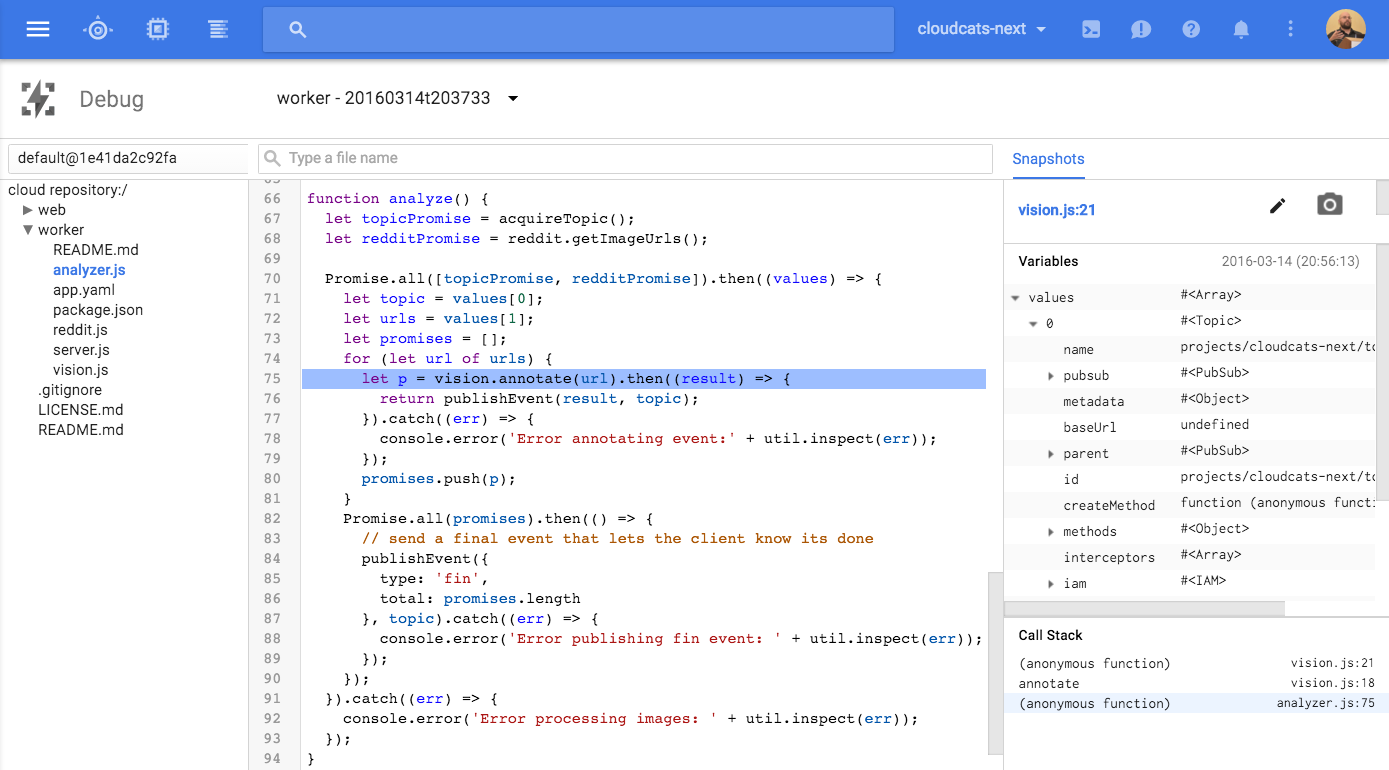
When you’re ready to address performance, Google Cloud Trace will help you analyze performance by collecting end-to-end latency data for requests to App Engine URIs and additional data for round-trip RPC calls to App Engine services like Datastore, and Memcache.
NodeSource partnership
Along with the Cloud Debug and Trace tools, we’re also announcing a partnership with NodeSource. NodeSource delivers enterprise-grade tools and software targeting the unique needs of running server-side JavaScript at scale. The N|Solid™ platform extends the capabilities of Node.js to provide increased developer productivity, protection of critical applications and peak application performance. N|Solid and Cloud Platform make a great match for running enterprise Node.js applications. You can learn more about using N|Solid on Cloud Platform from the NodeSource blog.

Committent to Node.js and open source
At Google, we’re committed to open source. The new core node.js Docker runtime, debug module, trace tools, gcloud NPM module, everything — all open source:
- https://github.com/GoogleCloudPlatform/nodejs-docker
- https://github.com/GoogleCloudPlatform/gcloud-node
- https://github.com/GoogleCloudPlatform/cloud-trace-nodejs
- https://github.com/GoogleCloudPlatform/cloud-debug-nodejs
- https://github.com/google/google-api-nodejs-client
We’re thrilled to welcome Node.js developers to Cloud Platform, and we’re committed to making further investments to help make you as productive as possible. This is just the start — keep your ear to the ground to catch the next wave of Node.js support on Cloud Platform.
We can’t wait to hear what you think. Feel free to reach out to us on Twitter @googlecloud, or request an invite to the Google Cloud Slack community and join the #nodejs channel.
- Posted by Justin Beckwith, Product Manager, Google Cloud Platform