Google leaders take the stage at HLTH to discuss the transformative power of AI for health.
Google leaders take the stage at HLTH to discuss the transformative power of AI for health.
HLTH 2023: Bringing AI to health responsibly
Google leaders take the stage at HLTH to discuss the transformative power of AI for health.
Google leaders take the stage at HLTH to discuss the transformative power of AI for health.
 Dr. Karen DeSalvo on AI’s potential to improve health for everyone, everywhere. Along with how to approach it so it can benefit everyone.
Dr. Karen DeSalvo on AI’s potential to improve health for everyone, everywhere. Along with how to approach it so it can benefit everyone.
 Here are five ways to maximize your app experience.
Here are five ways to maximize your app experience.
 We’re introducing Google Cloud healthcare customers using Med-PaLM 2 and other generative AI solutions.
We’re introducing Google Cloud healthcare customers using Med-PaLM 2 and other generative AI solutions.
Medicine is an inherently multimodal discipline. When providing care, clinicians routinely interpret data from a wide range of modalities including medical images, clinical notes, lab tests, electronic health records, genomics, and more. Over the last decade or so, AI systems have achieved expert-level performance on specific tasks within specific modalities — some AI systems processing CT scans, while others analyzing high magnification pathology slides, and still others hunting for rare genetic variations. The inputs to these systems tend to be complex data such as images, and they typically provide structured outputs, whether in the form of discrete grades or dense image segmentation masks. In parallel, the capacities and capabilities of large language models (LLMs) have become so advanced that they have demonstrated comprehension and expertise in medical knowledge by both interpreting and responding in plain language. But how do we bring these capabilities together to build medical AI systems that can leverage information from all these sources?
In today’s blog post, we outline a spectrum of approaches to bringing multimodal capabilities to LLMs and share some exciting results on the tractability of building multimodal medical LLMs, as described in three recent research papers. The papers, in turn, outline how to introduce de novo modalities to an LLM, how to graft a state-of-the-art medical imaging foundation model onto a conversational LLM, and first steps towards building a truly generalist multimodal medical AI system. If successfully matured, multimodal medical LLMs might serve as the basis of new assistive technologies spanning professional medicine, medical research, and consumer applications. As with our prior work, we emphasize the need for careful evaluation of these technologies in collaboration with the medical community and healthcare ecosystem.
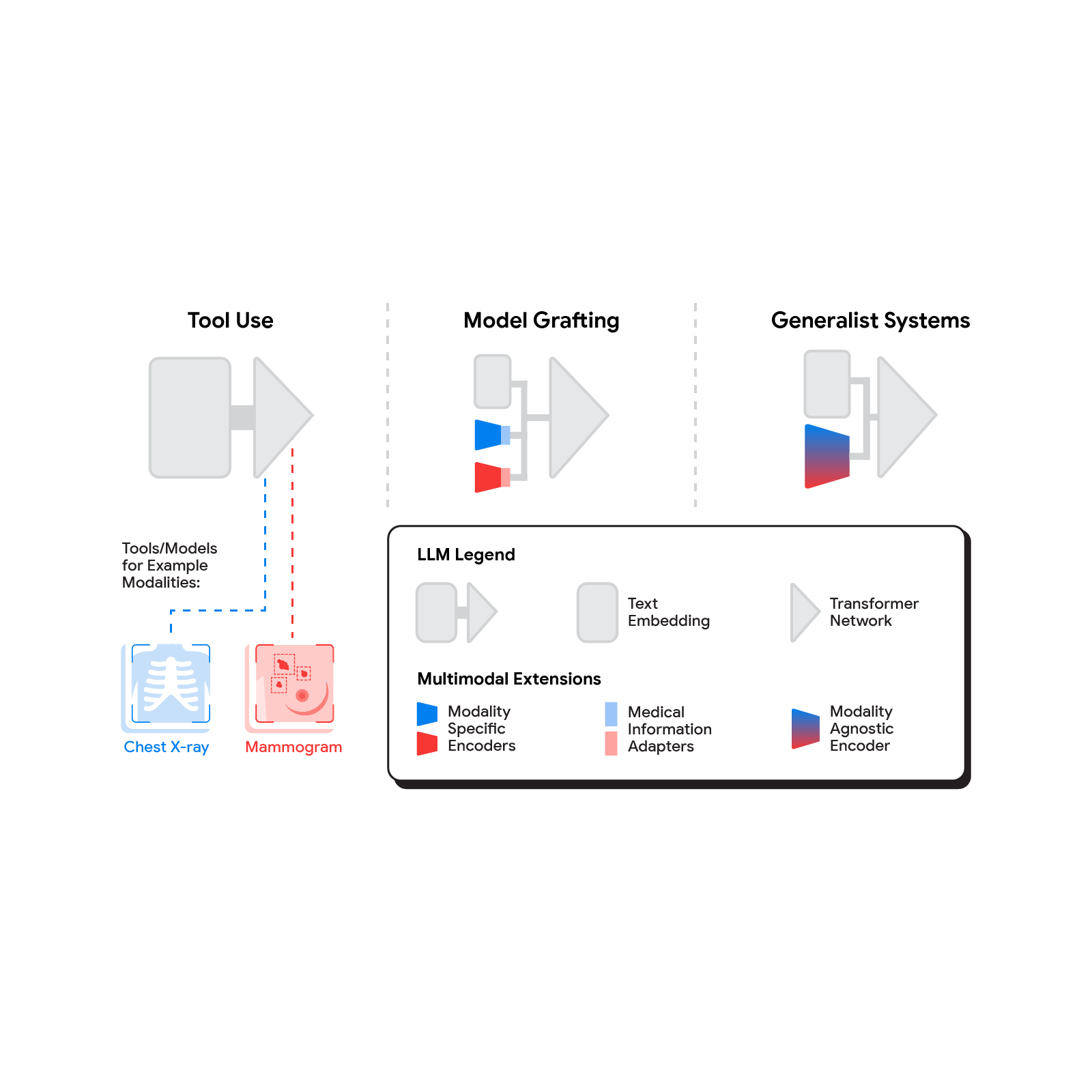
Several methods for building multimodal LLMs have been proposed in recent months [1, 2, 3], and no doubt new methods will continue to emerge for some time. For the purpose of understanding the opportunities to bring new modalities to medical AI systems, we’ll consider three broadly defined approaches: tool use, model grafting, and generalist systems.
 |
| The spectrum of approaches to building multimodal LLMs range from having the LLM use existing tools or models, to leveraging domain-specific components with an adapter, to joint modeling of a multimodal model. |
In the tool use approach, one central medical LLM outsources analysis of data in various modalities to a set of software subsystems independently optimized for those tasks: the tools. The common mnemonic example of tool use is teaching an LLM to use a calculator rather than do arithmetic on its own. In the medical space, a medical LLM faced with a chest X-ray could forward that image to a radiology AI system and integrate that response. This could be accomplished via application programming interfaces (APIs) offered by subsystems, or more fancifully, two medical AI systems with different specializations engaging in a conversation.
This approach has some important benefits. It allows maximum flexibility and independence between subsystems, enabling health systems to mix and match products between tech providers based on validated performance characteristics of subsystems. Moreover, human-readable communication channels between subsystems maximize auditability and debuggability. That said, getting the communication right between independent subsystems can be tricky, narrowing the information transfer, or exposing a risk of miscommunication and information loss.
A more integrated approach would be to take a neural network specialized for each relevant domain, and adapt it to plug directly into the LLM — grafting the visual model onto the core reasoning agent. In contrast to tool use where the specific tool(s) used are determined by the LLM, in model grafting the researchers may choose to use, refine, or develop specific models during development. In two recent papers from Google Research, we show that this is in fact feasible. Neural LLMs typically process text by first mapping words into a vector embedding space. Both papers build on the idea of mapping data from a new modality into the input word embedding space already familiar to the LLM. The first paper, “Multimodal LLMs for health grounded in individual-specific data”, shows that asthma risk prediction in the UK Biobank can be improved if we first train a neural network classifier to interpret spirograms (a modality used to assess breathing ability) and then adapt the output of that network to serve as input into the LLM.
The second paper, “ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders”, takes this same tack, but applies it to full-scale image encoder models in radiology. Starting with a foundation model for understanding chest X-rays, already shown to be a good basis for building a variety of classifiers in this modality, this paper describes training a lightweight medical information adapter that re-expresses the top layer output of the foundation model as a series of tokens in the LLM’s input embeddings space. Despite fine-tuning neither the visual encoder nor the language model, the resulting system displays capabilities it wasn’t trained for, including semantic search and visual question answering.
 |
| Our approach to grafting a model works by training a medical information adapter that maps the output of an existing or refined image encoder into an LLM-understandable form. |
Model grafting has a number of advantages. It uses relatively modest computational resources to train the adapter layers but allows the LLM to build on existing highly-optimized and validated models in each data domain. The modularization of the problem into encoder, adapter, and LLM components can also facilitate testing and debugging of individual software components when developing and deploying such a system. The corresponding disadvantages are that the communication between the specialist encoder and the LLM is no longer human readable (being a series of high dimensional vectors), and the grafting procedure requires building a new adapter for not just every domain-specific encoder, but also every revision of each of those encoders.
The most radical approach to multimodal medical AI is to build one integrated, fully generalist system natively capable of absorbing information from all sources. In our third paper in this area, “Towards Generalist Biomedical AI”, rather than having separate encoders and adapters for each data modality, we build on PaLM-E, a recently published multimodal model that is itself a combination of a single LLM (PaLM) and a single vision encoder (ViT). In this set up, text and tabular data modalities are covered by the LLM text encoder, but now all other data are treated as an image and fed to the vision encoder.
 |
| Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same model weights. |
We specialize PaLM-E to the medical domain by fine-tuning the complete set of model parameters on medical datasets described in the paper. The resulting generalist medical AI system is a multimodal version of Med-PaLM that we call Med-PaLM M. The flexible multimodal sequence-to-sequence architecture allows us to interleave various types of multimodal biomedical information in a single interaction. To the best of our knowledge, it is the first demonstration of a single unified model that can interpret multimodal biomedical data and handle a diverse range of tasks using the same set of model weights across all tasks (detailed evaluations in the paper).
This generalist-system approach to multimodality is both the most ambitious and simultaneously most elegant of the approaches we describe. In principle, this direct approach maximizes flexibility and information transfer between modalities. With no APIs to maintain compatibility across and no proliferation of adapter layers, the generalist approach has arguably the simplest design. But that same elegance is also the source of some of its disadvantages. Computational costs are often higher, and with a unitary vision encoder serving a wide range of modalities, domain specialization or system debuggability could suffer.
To make the most of AI in medicine, we’ll need to combine the strength of expert systems trained with predictive AI with the flexibility made possible through generative AI. Which approach (or combination of approaches) will be most useful in the field depends on a multitude of as-yet unassessed factors. Is the flexibility and simplicity of a generalist model more valuable than the modularity of model grafting or tool use? Which approach gives the highest quality results for a specific real-world use case? Is the preferred approach different for supporting medical research or medical education vs. augmenting medical practice? Answering these questions will require ongoing rigorous empirical research and continued direct collaboration with healthcare providers, medical institutions, government entities, and healthcare industry partners broadly. We look forward to finding the answers together.
 The updated Fitbit app, coming later this fall, has a simpler design and more motivating content
The updated Fitbit app, coming later this fall, has a simpler design and more motivating content
Learning from periodic data (signals that repeat, such as a heart beat or the daily temperature changes on Earth’s surface) is crucial for many real-world applications, from monitoring weather systems to detecting vital signs. For example, in the environmental remote sensing domain, periodic learning is often needed to enable nowcasting of environmental changes, such as precipitation patterns or land surface temperature. In the health domain, learning from video measurement has shown to extract (quasi-)periodic vital signs such as atrial fibrillation and sleep apnea episodes.
Approaches like RepNet highlight the importance of these types of tasks, and present a solution that recognizes repetitive activities within a single video. However, these are supervised approaches that require a significant amount of data to capture repetitive activities, all labeled to indicate the number of times an action was repeated. Labeling such data is often challenging and resource-intensive, requiring researchers to manually capture gold-standard temporal measurements that are synchronized with the modality of interest (e.g., video or satellite imagery).
Alternatively, self-supervised learning (SSL) methods (e.g., SimCLR and MoCo v2), which leverage a large amount of unlabeled data to learn representations that capture periodic or quasi-periodic temporal dynamics, have demonstrated success in solving classification tasks. However, they overlook the intrinsic periodicity (i.e., the ability to identify if a frame is part of a periodic process) in data and fail to learn robust representations that capture periodic or frequency attributes. This is because periodic learning exhibits characteristics that are distinct from prevailing learning tasks.
 |
| Feature similarity is different in the context of periodic representations as compared to static features (e.g., images). For example, videos that are offset by short time delays or are reversed should be similar to the original sample, whereas videos that have been upsampled or downsampled by a factor x should be different from the original sample by a factor of x. |
To address these challenges, in “SimPer: Simple Self-Supervised Learning of Periodic Targets”, published at the eleventh International Conference on Learning Representations (ICLR 2023), we introduced a self-supervised contrastive framework for learning periodic information in data. Specifically, SimPer leverages the temporal properties of periodic targets using temporal self-contrastive learning, where positive and negative samples are obtained through periodicity-invariant and periodicity-variant augmentations from the same input instance. We propose periodic feature similarity that explicitly defines how to measure similarity in the context of periodic learning. Moreover, we design a generalized contrastive loss that extends the classic InfoNCE loss to a soft regression variant that enables contrasting over continuous labels (frequency). Next, we demonstrate that SimPer effectively learns period feature representations compared to state-of-the-art SSL methods, highlighting its intriguing properties including better data efficiency, robustness to spurious correlations, and generalization to distribution shifts. Finally, we are excited to release the SimPer code repo with the research community.
SimPer introduces a temporal self-contrastive learning framework. Positive and negative samples are obtained through periodicity-invariant and periodicity-variant augmentations from the same input instance. For temporal video examples, periodicity-invariant changes are cropping, rotation or flipping, whereas periodicity-variant changes involve increasing or decreasing the speed of a video.
To explicitly define how to measure similarity in the context of periodic learning, SimPer proposes periodic feature similarity. This construction allows us to formulate training as a contrastive learning task. A model can be trained with data without any labels and then fine-tuned if necessary to map the learned features to specific frequency values.
Given an input sequence x, we know there’s an underlying associated periodic signal. We then transform x to create a series of speed or frequency altered samples, which changes the underlying periodic target, thus creating different negative views. Although the original frequency is unknown, we effectively devise pseudo- speed or frequency labels for the unlabeled input x.
Conventional similarity measures such as cosine similarity emphasize strict proximity between two feature vectors, and are sensitive to index shifted features (which represent different time stamps), reversed features, and features with changed frequencies. In contrast, periodic feature similarity should be high for samples with small temporal shifts and or reversed indexes, while capturing a continuous similarity change when the feature frequency varies. This can be achieved via a similarity metric in the frequency domain, such as the distance between two Fourier transforms.
To harness the intrinsic continuity of augmented samples in the frequency domain, SimPer designs a generalized contrastive loss that extends the classic InfoNCE loss to a soft regression variant that enables contrasting over continuous labels (frequency). This makes it suitable for regression tasks, where the goal is to recover a continuous signal, such as a heart beat.
 |
| SimPer constructs negative views of data through transformations in the frequency domain. The input sequence x has an underlying associated periodic signal. SimPer transforms x to create a series of speed or frequency altered samples, which changes the underlying periodic target, thus creating different negative views. Although the original frequency is unknown, we effectively devise pseudo speed or frequency labels for unlabeled input x (periodicity-variant augmentations τ). SimPer takes transformations that do not change the identity of the input and defines these as periodicity-invariant augmentations σ, thus creating different positive views of the sample. Then, it sends these augmented views to the encoder f, which extracts corresponding features. |
To evaluate SimPer's performance, we benchmarked it against state-of-the-art SSL schemes (e.g., SimCLR, MoCo v2, BYOL, CVRL) on a set of six diverse periodic learning datasets for common real-world tasks in human behavior analysis, environmental remote sensing, and healthcare. Specifically, below we present results on heart rate measurement and exercise repetition counting from video. The results show that SimPer outperforms the state-of-the-art SSL schemes across all six datasets, highlighting its superior performance in terms of data efficiency, robustness to spurious correlations, and generalization to unseen targets.
Here we show quantitative results on two representative datasets using SimPer pre-trained using various SSL methods and fine-tuned on the labeled data. First, we pre-train SimPer using the Univ. Bourgogne Franche-Comté Remote PhotoPlethysmoGraphy (UBFC) dataset, a human photoplethysmography and heart rate prediction dataset, and compare its performance to state-of-the-art SSL methods. We observe that SimPer outperforms SimCLR, MoCo v2, BYOL, and CVRL methods. The results on the human action counting dataset, Countix, further confirm the benefits of SimPer over others methods as it notably outperforms the supervised baseline. For the feature evaluation results and performance on other datasets, please refer to the paper.
 |
| Results of SimCLR, MoCo v2, BYOL, CVRL and SimPer on the Univ. Bourgogne Franche-Comté Remote PhotoPlethysmoGraphy (UBFC) and Countix datasets. Heart rate and repetition count performance is reported as mean absolute error (MAE). |
We present SimPer, a self-supervised contrastive framework for learning periodic information in data. We demonstrate that by combining a temporal self-contrastive learning framework, periodicity-invariant and periodicity-variant augmentations, and continuous periodic feature similarity, SimPer provides an intuitive and flexible approach for learning strong feature representations for periodic signals. Moreover, SimPer can be applied to various fields, ranging from environmental remote sensing to healthcare.
We would like to thank Yuzhe Yang, Xin Liu, Ming-Zher Poh, Jiang Wu, Silviu Borac, and Dina Katabi for their contributions to this work.
 Knowledge is key to maintaining good health— so we take seriously our responsibility to make health information more accessible for individuals, caregivers, and communit…
Knowledge is key to maintaining good health— so we take seriously our responsibility to make health information more accessible for individuals, caregivers, and communit…
 Today marks the 75th birthday of the NHS. In 1948, the founders could not have envisioned the advances that have been made or the scale of the service, now treating 1.6 …
Today marks the 75th birthday of the NHS. In 1948, the founders could not have envisioned the advances that have been made or the scale of the service, now treating 1.6 …
 Lens makes it easy to search what you see and explore the world around you — including the new ability to search for skin conditions.
Lens makes it easy to search what you see and explore the world around you — including the new ability to search for skin conditions.