TensorFlow/Keras
Load-testing TensorFlow Serving’s REST Interface by ML GDE Sayak Paul (India) and Chansung Park (Korea) shares the lessons and findings they learned from conducting load tests for an image classification model across numerous deployment configurations.
TFUG Taipei hosted events (Python + Hugging Face-Translation+ tf.keras.losses, Python + Object detection, Python+Hugging Face-Token Classification+tf.keras.initializers) in September and helped community members learn how to use TF and Hugging face to implement machine learning model to solve problems.
Neural Machine Translation with Bahdanau’s Attention Using TensorFlow and Keras and the related video by ML GDE Aritra Roy Gosthipaty (India) explains the mathematical intuition behind neural machine translation.
Automated Deployment of TensorFlow Models with TensorFlow Serving and GitHub Actions by ML GDE Chansung Park (Korea) and Sayak Paul (India) explains how to automate TensorFlow model serving on Kubernetes with TensorFlow Serving and GitHub Action.
Deploying ? ViT on Kubernetes with TF Serving by ML GDE Sayak Paul (India) and Chansung Park (Korea) shows how to scale the deployment of a ViT model from ? Transformers using Docker and Kubernetes.
Long-term TensorFlow Guidance on tf.wiki Forum by ML GDE Xihan Li (China) provides TensorFlow guidance by answering the questions from Chinese developers on the forum.
Hindi Character Recognition on Android using TensorFlow Lite by ML GDE Nitin Tiwari (India) shares an end-to-end tutorial on training a custom computer vision model to recognize Hindi characters. In TFUG Pune event, he also gave a presentation titled Building Computer Vision Model using TensorFlow: Part 1.
Using TFlite Model Maker to Complete a Custom Audio Classification App by ML GDE Xiaoxing Wang (China) shows how to use TFLite Model Maker to build a custom audio classification model based on YAMNet and how to import and use the YAMNet-based custom models in Android projects.
SoTA semantic segmentation in TF with ? by ML GDE Sayak Paul (India) and Chansung Park (Korea). The SegFormer model was not available on TensorFlow.
Text Augmentation in Keras NLP by ML GDE Xiaoquan Kong (China) explains what text augmentation is and how the text augmentation feature in Keras NLP is designed.
The largest vision model checkpoint (public) in TF (10 Billion params) through ? transformers by ML GDE Sayak Paul (India) and Aritra Roy Gosthipaty (India). The underlying model is RegNet, known for its ability to scale.
CryptoGANs open-source repository by ML GDE Dimitre Oliveira (Brazil) shows simple model implementations following TensorFlow best practices that can be extended to more complex use-cases. It connects the usage of TensorFlow with other relevant frameworks, like HuggingFace, Gradio, and Streamlit, building an end-to-end solution.
TFX
MLOps for Vision Models from ? with TFX by ML GDE Chansung Park (Korea) and Sayak Paul (India) shows how to build a machine learning pipeline for a vision model (TensorFlow) from ? Transformers using the TF ecosystem.
First release of TFX Addons Package by ML GDE Hannes Hapke (United States). The package has been downloaded a few thousand times (source). Google and other developers maintain it through bi-weekly meetings. Google’s Open Source Peer Award has recognized the work.
TFUG São Paulo hosted TFX T1 | E4 & TFX T1 | E5. And ML GDE Vinicius Caridá (Brazil) shared how to train a model in a TFX pipeline. The fifth episode talks about Pusher: publishing your models with TFX.
Semantic Segmentation model within ML pipeline by ML GDE Chansung Park (Korea) and Sayak Paul (India) shows how to build a machine learning pipeline for semantic segmentation task with TFX and various GCP products such as Vertex Pipeline, Training, and Endpoints.
JAX/Flax
JAX Tutorial by ML GDE Phillip Lippe (Netherlands) is meant to briefly introduce JAX, including writing and training neural networks with Flax.
TFUG Malaysia hosted Introduction to JAX for Machine Learning (video) and Leong Lai Fong gave a talk. The attendees learned what JAX is and its fundamental yet unique features, which make it efficient to use when executing deep learning workloads. After that, they started training their first JAX-powered deep learning model.
TFUG Taipei hosted Python+ JAX + Image classification and helped people learn JAX and how to use it in Colab. They shared knowledge about the difference between JAX and Numpy, the advantages of JAX, and how to use it in Colab.
Introduction to JAX by ML GDE João Araújo (Brazil) shared the basics of JAX in Deep Learning Indaba 2022.
Should I change from NumPy to JAX? by ML GDE Gad Benram (Portugal) compares the performance and overview of the issues that may result from changing from NumPy to JAX.
Introduction to JAX: efficient and reproducible ML framework by ML GDE Seunghyun Lee (Korea) introduced JAX/Flax and their key features using practical examples. He explained the pure function and PRNG, which make JAX explicit and reproducible, and XLA and mapping functions which make JAX fast and easily parallelized.
Data2Vec Style pre-training in JAX by ML GDE Vasudev Gupta (India) shares a tutorial for demonstrating how to pre-train Data2Vec using the Jax/Flax version of HuggingFace Transformers.
Distributed Machine Learning with JAX by ML GDE David Cardozo (Canada) delivered what makes JAX different from TensorFlow.
Image classification with JAX & Flax by ML GDE Derrick Mwiti (Kenya) explains how to build convolutional neural networks with JAX/Flax. And he wrote several articles about JAX/Flax: What is JAX?, How to load datasets in JAX with TensorFlow, Optimizers in JAX and Flax, Flax vs. TensorFlow, etc..
Kaggle
DDPMs - Part 1 by ML GDE Aakash Nain (India) and cait-tf by ML GDE Sayak Paul (India) were announced as Kaggle ML Research Spotlight Winners.
Fresher on Random Variables, All you need to know about Gaussian distribution, and A deep dive into DDPMs by ML GDE Aakash Nain (India) explain the fundamentals of diffusion models.
In Grandmasters Journey on Kaggle + The Kaggle Book, ML GDE Luca Massaron (Italy) explained how Kaggle helps people in the data science industry and which skills you must focus on apart from the core technical skills.
Cloud AI
How Cohere is accelerating language model training with Google Cloud TPUs by ML GDE Joanna Yoo (Canada) explains what Cohere engineers have done to solve scaling challenges in large language models (LLMs).
In Using machine learning to transform finance with Google Cloud and Digits, ML GDE Hannes Hapke (United States) chats with Fillipo Mandella, Customer Engineering Manager at Google, about how Digits leverages Google Cloud’s machine learning tools to empower accountants and business owners with near-zero latency.
A tour of Vertex AI by TFUG Chennai for ML, cloud, and DevOps engineers who are working in MLOps. This session was about the introduction of Vertex AI, handling datasets and models in Vertex AI, deployment & prediction, and MLOps.
TFUG Abidjan hosted two events with GDG Cloud Abidjan for students and professional developers who want to prepare for a Google Cloud certification: Introduction session to certifications and Q&A, Certification Study Group.
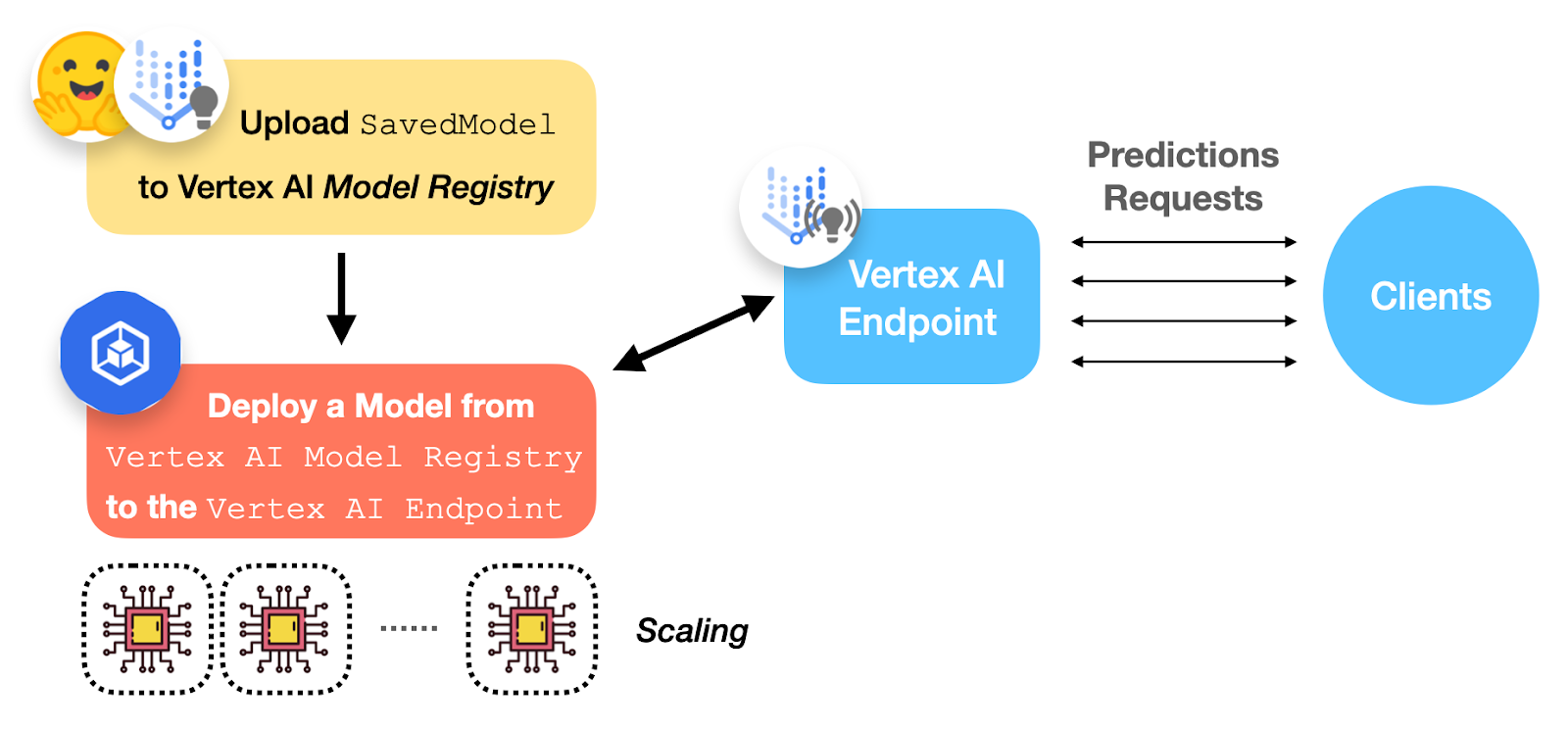
Deploying ? ViT on Vertex AI by ML GDE Sayak Paul (India) and Chansung Park (Korea) shows how to deploy a ViT B/16 model on Vertex AI. They cover some critical aspects of a deployment such as auto-scaling, authentication, endpoint consumption, and load-testing.
TFUG Singapore hosted The World of Diffusion - DALL-E 2, IMAGEN & Stable Diffusion. ML GDE Martin Andrews (Singapore) and Sam Witteveen (Singapore) gave talks named “How Diffusion Works” and “Investigating Prompt Engineering on Diffusion Models” to bring people up-to-date with what has been going on in the world of image generation.
ML GDE Martin Andrews (Singapore) have done three projects: GCP VM with Nvidia set-up and Convenience Scripts, Containers within a GCP host server, with Nvidia pass-through, Installing MineRL using Containers - with linked code.
Jupyter Services on Google Cloud by ML GDE Gad Benram (Portugal) explains the differences between Vertex AI Workbench, Colab, and Deep Learning VMs.
Train and Deploy Google Cloud's Two Towers Recommender by ML GDE Rubens de Almeida Zimbres (Brazil) explains how to implement the model and deploy it in Vertex AI.
Research & Ecosystem
The first session of #MLPaperReadingClubs (video) by ML GDE Nathaly Alarcon Torrico (Bolivia) and Women in Data Science La Paz. Nathaly led the session, and the community members participated in reading the ML paper “Zero-shot learning through cross-modal transfer.”
In #MLPaperReadingClubs (video) by TFUG Lesotho, Arnold Raphael volunteered to lead the first session “Zero-shot learning through cross-modal transfer.”
ML Paper Reading Clubs #1: Zero Shot Learning Paper (video) by TFUG Agadir introduced a model that can recognize objects in images even if no training data is available for the objects. TFUG Agadir prepared this event to make people interested in machine learning research and provide them with a broader vision of differentiating good contributions from great ones.
Opening of the Machine Learning Paper Reading Club (video) by TFUG Dhaka introduced ML Paper Reading Club and the group’s plan.
EDA on SpaceX Falcon 9 launches dataset (Kaggle) (video) by TFUG Mysuru & TFUG Chandigarh organizer Aashi Dutt (presenter) walked through exploratory data analysis on SpaceX Falcon 9 launches dataset from Kaggle.
Introduction to MRC-style dialogue summaries based on BERT by ML GDE Qinghua Duan (China) shows how to apply the MRC paradigm and BERT to solve the dialogue summarization problem.
Plant disease classification using Deep learning model by ML GDE Yannick Serge Obam Akou (Cameroon) talked on plant disease classification using deep learning model : an end to end Android app (open source project) that diagnoses plant diseases.
Nystromformer Github repository by Rishit Dagli provides TensorFlow/Keras implementation of Nystromformer, a transformer variant that uses the Nyström method to approximate standard self-attention with O(n) complexity which allows for better scalability.




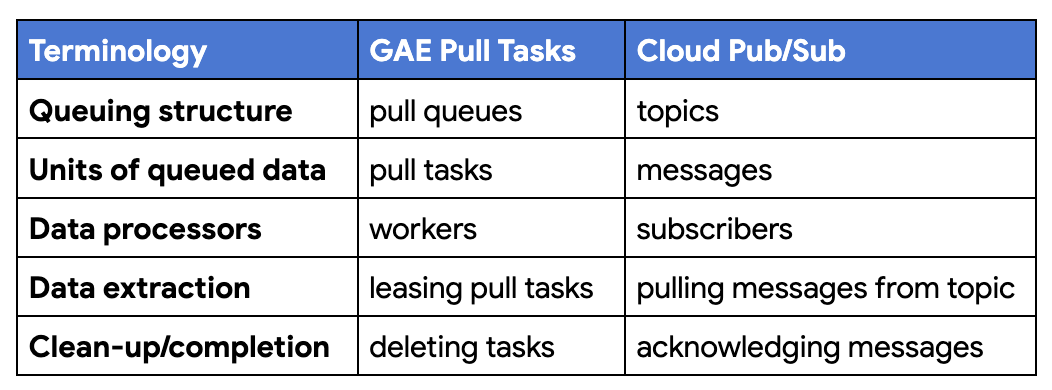




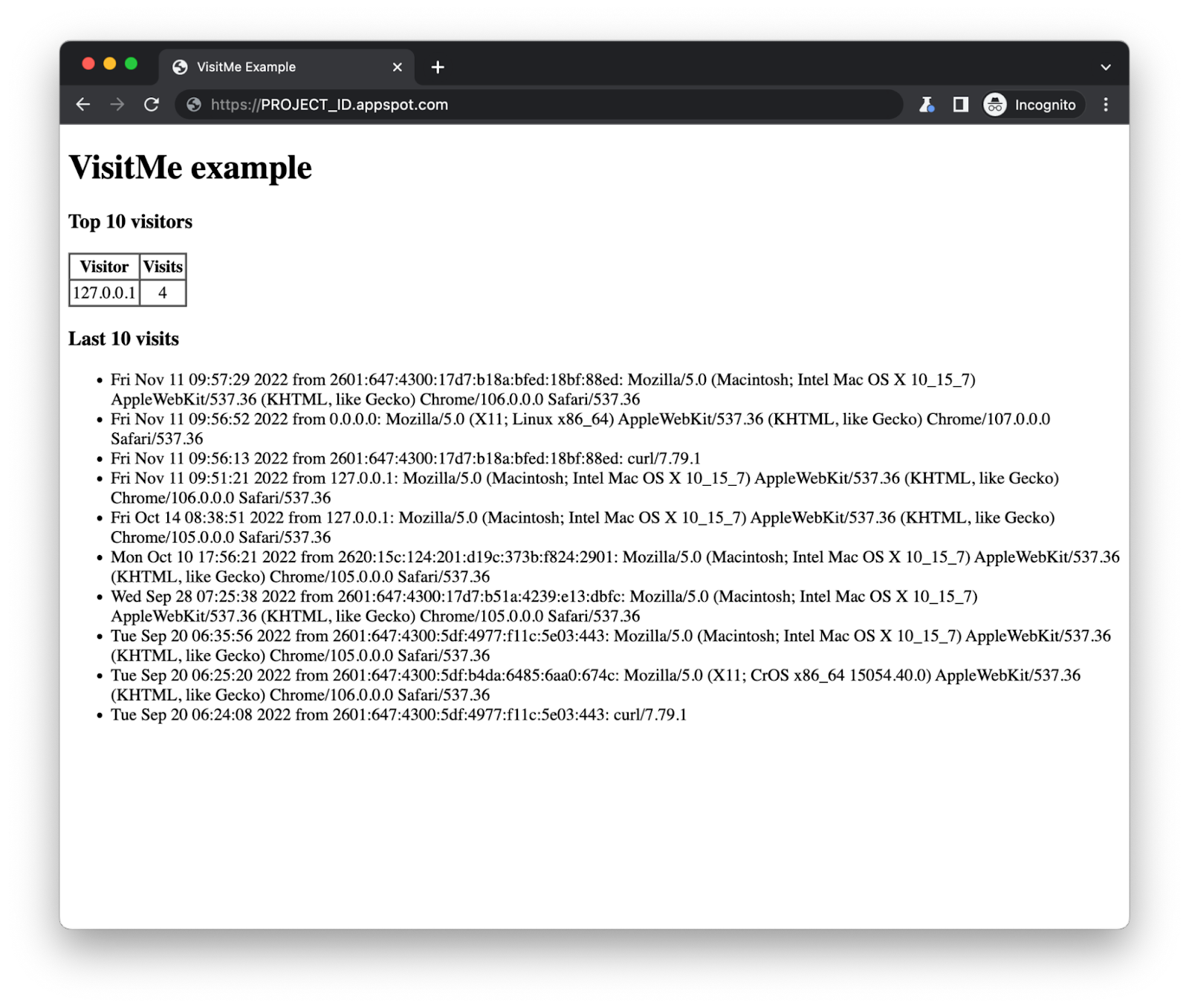

![Adding App Engine Task Queue pull task usage to sample app showing 'Before'[Module 1] on the left and 'After' [Module 18] with altered code on the right](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjRVGVYc9fl4xI9xUpOUaAwXup8p-wUf5nbKllG7OYJSVAYSPVCGw7DU8EbMoTE3kBBgVZiICFvsn_7fHP2oymA_1ASKBrAE2Qt8PzCGAAkK7_WnyvAIEMKQUrxP8FSz3tGykLrlu9nyluN5vgEPrWZrBqIAalCoRmos169g9m9NHz3cGqQyych9eEG/s1600/Screen%20Shot%202022-11-29%20at%205.19.28%20PM.png)
 Spain and UK cloud regions and offices are on track to operate at or near 90% carbon-free energy in 2025 thanks to two new clean energy projects.
Spain and UK cloud regions and offices are on track to operate at or near 90% carbon-free energy in 2025 thanks to two new clean energy projects.