A pathologist’s microscopic examination of a tumor in patients is considered the gold standard for cancer diagnosis, and has a profound impact on prognosis and treatment decisions. One important but laborious aspect of the pathologic review involves detecting cancer that has spread (metastasized) from the primary site to nearby lymph nodes. Detection of nodal metastasis is relevant for most cancers, and forms one of the foundations of the widely-used TNM cancer staging.
In breast cancer in particular, nodal metastasis influences treatment decisions regarding radiation therapy, chemotherapy, and the potential surgical removal of additional lymph nodes. As such, the accuracy and timeliness of identifying nodal metastases has a significant impact on clinical care. However, studies have shown that about 1 in 4 metastatic lymph node staging classifications would be changed upon second pathologic review, and detection sensitivity of small metastases on individual slides can be as low as 38% when reviewed under time constraints.
Last year, we described our deep learning–based approach to improve diagnostic accuracy (LYmph Node Assistant, or LYNA) to the 2016 ISBI Camelyon Challenge, which provided gigapixel-sized pathology slides of lymph nodes from breast cancer patients for researchers to develop computer algorithms to detect metastatic cancer. While LYNA achieved significantly higher cancer detection rates (Liu et al. 2017) than had been previously reported, an accurate algorithm alone is insufficient to improve pathologists’ workflow or improve outcomes for breast cancer patients. For patient safety, these algorithms must be tested in a variety of settings to understand their strengths and weaknesses. Furthermore, the actual benefits to pathologists using these algorithms had not been previously explored and must be assessed to determine whether or not an algorithm actually improves efficiency or diagnostic accuracy.
In “Artificial Intelligence Based Breast Cancer Nodal Metastasis Detection: Insights into the Black Box for Pathologists” (Liu et al. 2018), published in the Archives of Pathology and Laboratory Medicine and “Impact of Deep Learning Assistance on the Histopathologic Review of Lymph Nodes for Metastatic Breast Cancer” (Steiner, MacDonald, Liu et al. 2018) published in The American Journal of Surgical Pathology, we present a proof-of-concept pathologist assistance tool based on LYNA, and investigate these factors.
In the first paper, we applied our algorithm to de-identified pathology slides from both the Camelyon Challenge and an independent dataset provided by our co-authors at the Naval Medical Center San Diego. Because this additional dataset consisted of pathology samples from a different lab using different processes, it improved the representation of the diversity of slides and artifacts seen in routine clinical practice. LYNA proved robust to image variability and numerous histological artifacts, and achieved similar performance on both datasets without additional development.
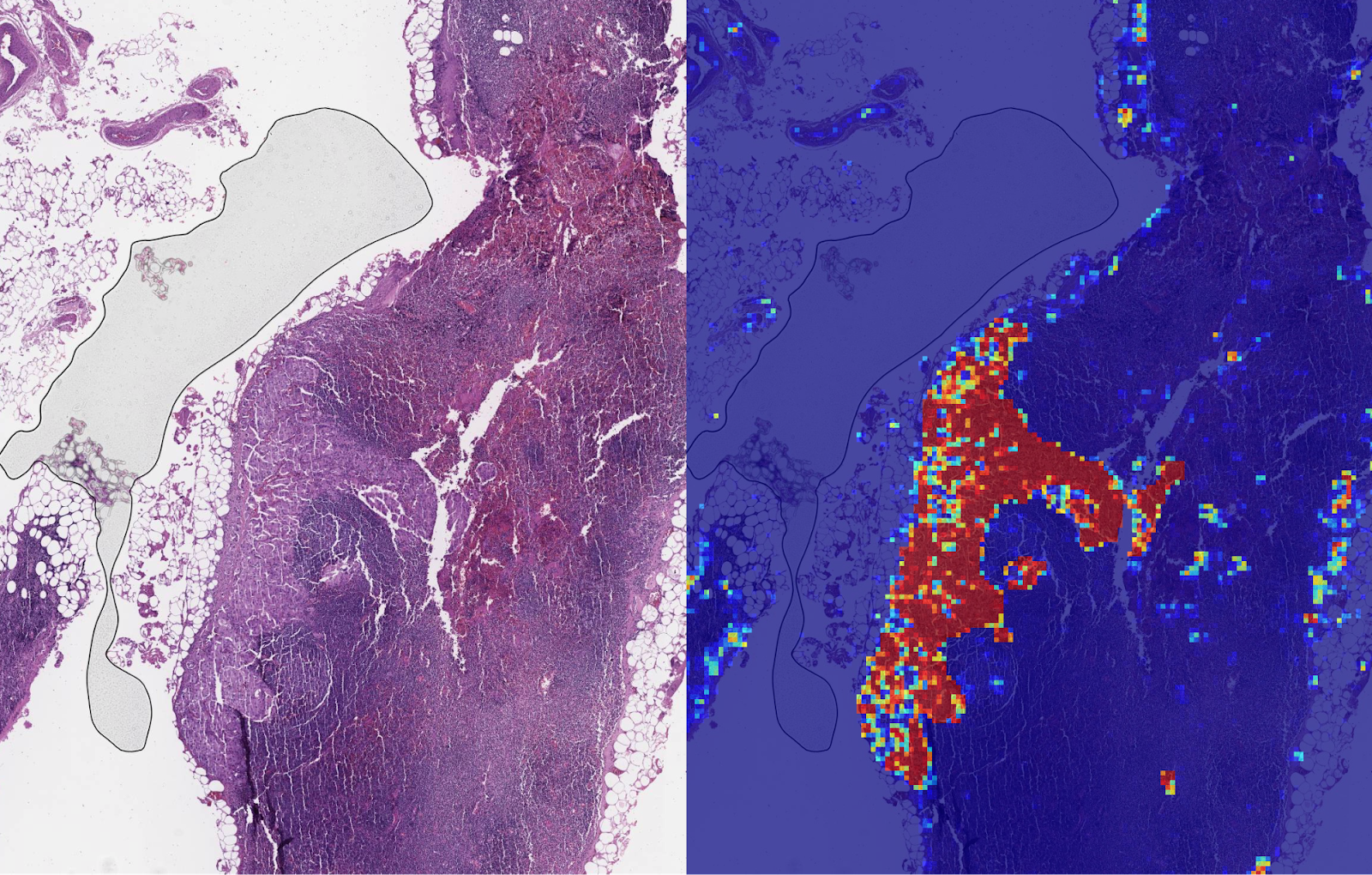 |
| Left: sample view of a slide containing lymph nodes, with multiple artifacts: the dark zone on the left is an air bubble, the white streaks are cutting artifacts, the red hue across some regions are hemorrhagic (containing blood), the tissue is necrotic (decaying), and the processing quality was poor. Right: LYNA identifies the tumor region in the center (red), and correctly classifies the surrounding artifact-laden regions as non-tumor (blue). |
In our second paper, 6 board-certified pathologists completed a simulated diagnostic task in which they reviewed lymph nodes for metastatic breast cancer both with and without the assistance of LYNA. For the often laborious task of detecting small metastases (termed micrometastases), the use of LYNA made the task subjectively “easier” (according to pathologists’ self-reported diagnostic difficulty) and halved average slide review time, requiring about one minute instead of two minutes per slide.
 |
| Left: sample views of a slide containing lymph nodes with a small metastatic breast tumor at progressively higher magnifications. Right: the same views when shown with algorithmic “assistance” (LYmph Node Assistant, LYNA) outlining the tumor in cyan. |
With these studies, we have made progress in demonstrating the robustness of our LYNA algorithm to support one component of breast cancer TNM staging, and assessing its impact in a proof-of-concept diagnostic setting. While encouraging, the bench-to-bedside journey to help doctors and patients with these types of technologies is a long one. These studies have important limitations, such as limited dataset sizes and a simulated diagnostic workflow which examined only a single lymph node slide for every patient instead of the multiple slides that are common for a complete clinical case. Further work will be needed to assess the impact of LYNA on real clinical workflows and patient outcomes. However, we remain optimistic that carefully validated deep learning technologies and well-designed clinical tools can help improve both the accuracy and availability of pathologic diagnosis around the world.




































{kind=link}
{kind=link}
{kind=link}
{kind=link}