Developing machine learning (ML) models for audio understanding has seen tremendous progress over the past several years. Leveraging the ability to learn parameters from data, the field has progressively shifted from composite, handcrafted systems to today’s deep neural classifiers that are used to recognize speech, understand music, or classify animal vocalizations such as bird calls. However, unlike computer vision models, which can learn from raw pixels, deep neural networks for audio classification are rarely trained from raw audio waveforms. Instead, they rely on pre-processed data in the form of mel filterbanks — handcrafted mel-scaled spectrograms that have been designed to replicate some aspects of the human auditory response.
Although modeling mel filterbanks for ML tasks has been historically successful, it is limited by the inherent biases of fixed features: even though using a fixed mel-scale and a logarithmic compression works well in general, we have no guarantee that they provide the best representations for the task at hand. In particular, even though matching human perception provides good inductive biases for some application domains, e.g., speech recognition or music understanding, these biases may be detrimental to domains for which imitating the human ear is not important, such as recognizing whale calls. So, in order to achieve optimal performance, the mel filterbanks should be tailored to the task of interest, a tedious process that requires an iterative effort informed by expert domain knowledge. As a consequence, standard mel filterbanks are used for most audio classification tasks in practice, even though they are suboptimal. In addition, while researchers have proposed ML systems to address these problems, such as Time-Domain Filterbanks, SincNet and Wavegram, they have yet to match the performance of traditional mel filterbanks.
In “LEAF, A Fully Learnable Frontend for Audio Classification”, accepted at ICLR 2021, we present an alternative method for crafting learnable spectrograms for audio understanding tasks. LEarnable Audio Frontend (LEAF) is a neural network that can be initialized to approximate mel filterbanks, and then be trained jointly with any audio classifier to adapt to the task at hand, while only adding a handful of parameters to the full model. We show that over a wide range of audio signals and classification tasks, including speech, music and bird songs, LEAF spectrograms improve classification performance over fixed mel filterbanks and over previously proposed learnable systems. We have implemented the code in TensorFlow 2 and released it to the community through our GitHub repository.
Mel Filterbanks: Mimicking Human Perception of Sound
The first step in the traditional approach to creating a mel filterbank is to capture the sound’s time-variability by windowing, i.e., cutting the signal into short segments with fixed duration. Then, one performs filtering, by passing the windowed segments through a bank of fixed frequency filters, that replicate the human logarithmic sensitivity to pitch. Because we are more sensitive to variations in low frequencies than high frequencies, mel filterbanks give more importance to the low-frequency range of sounds. Finally, the audio signal is compressed to mimic the ear’s logarithmic sensitivity to loudness — a sound needs to double its power for a person to perceive an increase of 3 decibels.
LEAF loosely follows this traditional approach to mel filterbank generation, but replaces each of the fixed operations (i.e., the filtering layer, windowing layer, and compression function) by a learned counterpart. The output of LEAF is a time-frequency representation (a spectrogram) similar to mel filterbanks, but fully learnable. So, for example, while a mel filterbank uses a fixed scale for pitch, LEAF learns the scale that is best suited to the task of interest. Any model that can be trained using mel filterbanks as input features, can also be trained on LEAF spectrograms.
 |
| Diagram of computation of mel filterbanks compared to LEAF spectrograms. |
While LEAF can be initialized randomly, it can also be initialized in a way that approximates mel filterbanks, which have been shown to be a better starting point. Then, LEAF can be trained with any classifier to adapt to the task of interest.
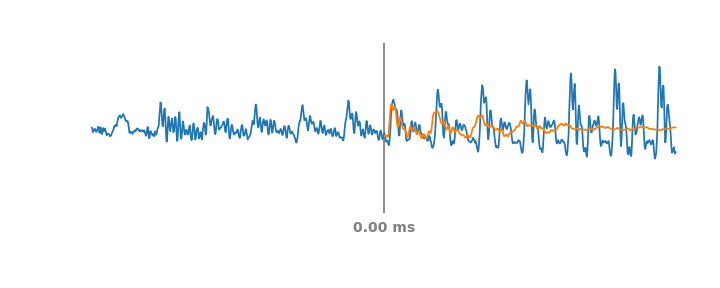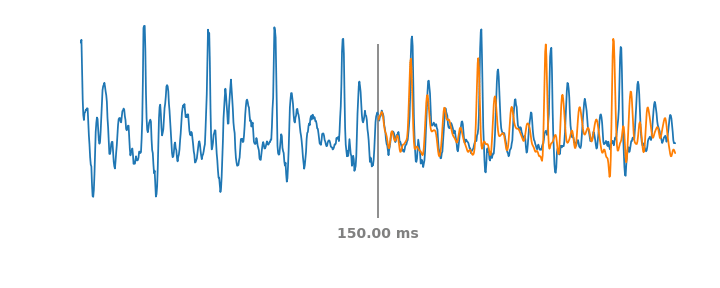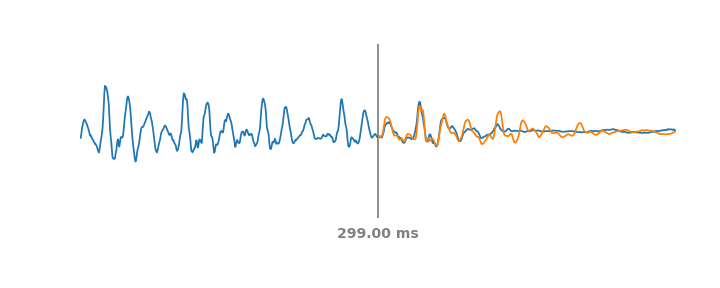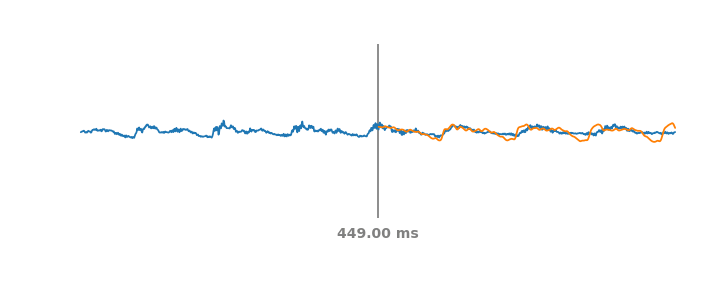
 |
| Left: Mel filterbanks for a person saying “wow”. Right: LEAF’s output for the same example, after training on a dataset of speech commands. |
A Parameter-Efficient Alternative to Fixed Features
A potential downside of replacing fixed features that involve no learnable parameter with a trainable system is that it can significantly increase the number of parameters to optimize. To avoid this issue, LEAF uses Gabor convolution layers that have only two parameters per filter, instead of the ~400 parameters typical of a standard convolution layer. This way, even when paired with a small classifier, such as EfficientNetB0, the LEAF model only accounts for 0.01% of the total parameters.
 |
| Top: Unconstrained convolutional filters after training for audio event classification. Bottom: LEAF filters at convergence after training for the same task. |
Performance
We apply LEAF to diverse audio classification tasks, including recognizing speech commands, speaker identification, acoustic scene recognition, identifying musical instruments, and finding birdsongs. On average, LEAF outperforms both mel filterbanks and previous learnable frontends, such as Time-Domain Filterbanks, SincNet and Wavegram. In particular, LEAF achieves a 76.9% average accuracy across the different tasks, compared to 73.9% for mel filterbanks. Moreover we show that LEAF can be trained in a multi-task setting, such that a single LEAF parametrization can work well across all these tasks. Finally, when combined with a large audio classifier, LEAF reaches state-of-the-art performance on the challenging AudioSet benchmark, with a 2.74 d-prime score.
 |
| D-prime score (the higher the better) of LEAF, mel filterbanks and previously proposed learnable spectrograms on the evaluation set of AudioSet. |
Conclusion
The scope of audio understanding tasks keeps growing, from diagnosing dementia from speech to detecting humpback whale calls from underwater microphones. Adapting mel filterbanks to every new task can require a significant amount of hand-tuning and experimentation. In this context, LEAF provides a drop-in replacement for these fixed features, that can be trained to adapt to the task of interest, with minimal task-specific adjustments. Thus, we believe that LEAF can accelerate development of models for new audio understanding tasks.
Acknowledgements
We thank our co-authors, Olivier Teboul, Félix de Chaumont-Quitry and Marco Tagliasacchi. We also thank Dick Lyon, Vincent Lostanlen, Matt Harvey, and Alex Park for helpful discussions, and Julie Thomas for helping to design figures for this post.





















 Posted by Catherina Xu (Product Manager)
Posted by Catherina Xu (Product Manager)