Posted by Jamila Smith-Loud, Human Rights & Social Impact Research Lead, Google Research, Responsible AI and Human-Centered Technology Team 
Globalized technology has the potential to create large-scale societal impact, and having a grounded research approach rooted in existing international human and civil rights standards is a critical component to assuring responsible and ethical AI development and deployment. The Impact Lab team, part of Google’s Responsible AI Team, employs a range of interdisciplinary methodologies to ensure critical and rich analysis of the potential implications of technology development. The team’s mission is to examine socioeconomic and human rights impacts of AI, publish foundational research, and incubate novel mitigations enabling machine learning (ML) practitioners to advance global equity. We study and develop scalable, rigorous, and evidence-based solutions using data analysis, human rights, and participatory frameworks.
The uniqueness of the Impact Lab’s goals is its multidisciplinary approach and the diversity of experience, including both applied and academic research. Our aim is to expand the epistemic lens of Responsible AI to center the voices of historically marginalized communities and to overcome the practice of ungrounded analysis of impacts by offering a research-based approach to understand how differing perspectives and experiences should impact the development of technology.
What we do
In response to the accelerating complexity of ML and the increased coupling between large-scale ML and people, our team critically examines traditional assumptions of how technology impacts society to deepen our understanding of this interplay. We collaborate with academic scholars in the areas of social science and philosophy of technology and publish foundational research focusing on how ML can be helpful and useful. We also offer research support to some of our organization’s most challenging efforts, including the 1,000 Languages Initiative and ongoing work in the testing and evaluation of language and generative models. Our work gives weight to Google's AI Principles.
To that end, we:
- Conduct foundational and exploratory research towards the goal of creating scalable socio-technical solutions
- Create datasets and research-based frameworks to evaluate ML systems
- Define, identify, and assess negative societal impacts of AI
- Create responsible solutions to data collection used to build large models
- Develop novel methodologies and approaches that support responsible deployment of ML models and systems to ensure safety, fairness, robustness, and user accountability
- Translate external community and expert feedback into empirical insights to better understand user needs and impacts
- Seek equitable collaboration and strive for mutually beneficial partnerships
We strive not only to reimagine existing frameworks for assessing the adverse impact of AI to answer ambitious research questions, but also to promote the importance of this work.
Current research efforts
Understanding social problems
Our motivation for providing rigorous analytical tools and approaches is to ensure that social-technical impact and fairness is well understood in relation to cultural and historical nuances. This is quite important, as it helps develop the incentive and ability to better understand communities who experience the greatest burden and demonstrates the value of rigorous and focused analysis. Our goals are to proactively partner with external thought leaders in this problem space, reframe our existing mental models when assessing potential harms and impacts, and avoid relying on unfounded assumptions and stereotypes in ML technologies. We collaborate with researchers at Stanford, University of California Berkeley, University of Edinburgh, Mozilla Foundation, University of Michigan, Naval Postgraduate School, Data & Society, EPFL, Australian National University, and McGill University.
 |
| We examine systemic social issues and generate useful artifacts for responsible AI development. |
Centering underrepresented voices
We also developed the Equitable AI Research Roundtable (EARR), a novel community-based research coalition created to establish ongoing partnerships with external nonprofit and research organization leaders who are equity experts in the fields of education, law, social justice, AI ethics, and economic development. These partnerships offer the opportunity to engage with multi-disciplinary experts on complex research questions related to how we center and understand equity using lessons from other domains. Our partners include PolicyLink; The Education Trust - West; Notley; Partnership on AI; Othering and Belonging Institute at UC Berkeley; The Michelson Institute for Intellectual Property, HBCU IP Futures Collaborative at Emory University; Center for Information Technology Research in the Interest of Society (CITRIS) at the Banatao Institute; and the Charles A. Dana Center at the University of Texas, Austin. The goals of the EARR program are to: (1) center knowledge about the experiences of historically marginalized or underrepresented groups, (2) qualitatively understand and identify potential approaches for studying social harms and their analogies within the context of technology, and (3) expand the lens of expertise and relevant knowledge as it relates to our work on responsible and safe approaches to AI development.
Through semi-structured workshops and discussions, EARR has provided critical perspectives and feedback on how to conceptualize equity and vulnerability as they relate to AI technology. We have partnered with EARR contributors on a range of topics from generative AI, algorithmic decision making, transparency, and explainability, with outputs ranging from adversarial queries to frameworks and case studies. Certainly the process of translating research insights across disciplines into technical solutions is not always easy but this research has been a rewarding partnership. We present our initial evaluation of this engagement in this paper.
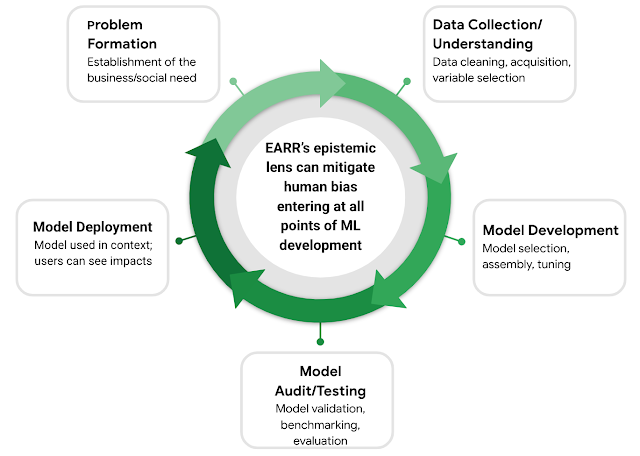 |
| EARR: Components of the ML development life cycle in which multidisciplinary knowledge is key for mitigating human biases. |
Grounding in civil and human rights values
In partnership with our Civil and Human Rights Program, our research and analysis process is grounded in internationally recognized human rights frameworks and standards including the Universal Declaration of Human Rights and the UN Guiding Principles on Business and Human Rights. Utilizing civil and human rights frameworks as a starting point allows for a context-specific approach to research that takes into account how a technology will be deployed and its community impacts. Most importantly, a rights-based approach to research enables us to prioritize conceptual and applied methods that emphasize the importance of understanding the most vulnerable users and the most salient harms to better inform day-to-day decision making, product design and long-term strategies.
Ongoing work
Social context to aid in dataset development and evaluation
We seek to employ an approach to dataset curation, model development and evaluation that is rooted in equity and that avoids expeditious but potentially risky approaches, such as utilizing incomplete data or not considering the historical and social cultural factors related to a dataset. Responsible data collection and analysis requires an additional level of careful consideration of the context in which the data are created. For example, one may see differences in outcomes across demographic variables that will be used to build models and should question the structural and system-level factors at play as some variables could ultimately be a reflection of historical, social and political factors. By using proxy data, such as race or ethnicity, gender, or zip code, we are systematically merging together the lived experiences of an entire group of diverse people and using it to train models that can recreate and maintain harmful and inaccurate character profiles of entire populations. Critical data analysis also requires a careful understanding that correlations or relationships between variables do not imply causation; the association we witness is often caused by additional multiple variables.
Relationship between social context and model outcomes
Building on this expanded and nuanced social understanding of data and dataset construction, we also approach the problem of anticipating or ameliorating the impact of ML models once they have been deployed for use in the real world. There are myriad ways in which the use of ML in various contexts — from education to health care — has exacerbated existing inequity because the developers and decision-making users of these systems lacked the relevant social understanding, historical context, and did not involve relevant stakeholders. This is a research challenge for the field of ML in general and one that is central to our team.
Globally responsible AI centering community experts
Our team also recognizes the saliency of understanding the socio-technical context globally. In line with Google’s mission to “organize the world’s information and make it universally accessible and useful”, our team is engaging in research partnerships globally. For example, we are collaborating with The Natural Language Processing team and the Human Centered team in the Makerere Artificial Intelligence Lab in Uganda to research cultural and language nuances as they relate to language model development.
Conclusion
We continue to address the impacts of ML models deployed in the real world by conducting further socio-technical research and engaging external experts who are also part of the communities that are historically and globally disenfranchised. The Impact Lab is excited to offer an approach that contributes to the development of solutions for applied problems through the utilization of social-science, evaluation, and human rights epistemologies.
Acknowledgements
We would like to thank each member of the Impact Lab team — Jamila Smith-Loud, Andrew Smart, Jalon Hall, Darlene Neal, Amber Ebinama, and Qazi Mamunur Rashid — for all the hard work they do to ensure that ML is more responsible to its users and society across communities and around the world.
 These simple steps will help you keep using Google Maps offline when you don’t have an internet connection.
These simple steps will help you keep using Google Maps offline when you don’t have an internet connection.





 The Daily Mail and General Trust and Independent Community News Network bring their journalism to Google News Showcase
The Daily Mail and General Trust and Independent Community News Network bring their journalism to Google News Showcase