For more than 17 years, Google's Open Source Programs Office (OSPO) has brought the best of open source to Google and the best of Google to open source. We sponsor, create, and invest in projects and programs that
enable everyone to join and contribute to the global open source ecosystem. Because that's who open source is for—
everyone.In 2021, Google
supported open source innovation, security, collaboration, and sustainability through our programs and services with $15 million of funding. This includes $7 million in direct funding to open source communities through Google’s OSPO. We also stepped up our investments in the governing organizations of open source ecosystems. We became
the first Visionary Sponsor of the Python Software Foundation, supporting a number of key initiatives including funding for the first
CPython Developer in Residence. We sustained our
Platinum Membership of the OpenJS Foundation to continue supporting the essential work of the foundation that fosters many critical projects in the Javascript ecosystem.
In late 2021, we
announced the release of Knative 1.0 and
submitted Knative to become a Cloud Native Computing Foundation incubation project to enable the next phase of community-driven innovation. (Knative’s application
was accepted in March 2022 and followed by our
submission of Istio to the CNCF). We also
collaborated with Antmicro to develop and release the Rowhammer Tester platform, which provides security professionals a flexible platform for experimenting with new types of attacks to find better mitigation techniques.
We sustain and expand the open source ecosystem through programs at scale
In addition to our new investments, we continued to maintain our long-term programs elevating open source contributors, both new and existing.
- The Google Open Source Live virtual events program, initiated in 2020, hosted 11 events, expanding to cover more projects and technology areas.
- Google Summer of Code, in its 17th year, matched 1,205 students from 67 countries with more than 2,100 mentors from 75 countries in 199 open source organizations to successfully complete this year’s program. At the end of this round, we announced our plans to broaden the scope of the program in 2022, expanding the eligibility of who could participate, offering more options around project contribution, and increased flexibility in the timing of the program.
- Season of Docs, in its third year, had 30 open source organizations finish their projects with 93% of organizations and 96% of the technical writers reporting a positive experience with the program.
- Through our Open Source Peer Bonus Program, we were able to award peer bonuses to 175 contributors working in 35 countries on 86 unique projects, including contributors to the CHAOSS, CocoaPods, git and Open Civic Data projects.
In 2021, Google's open source programs directly supported more than 120 events to safely bring together more than 88,000 attendees from open source communities. We proudly sponsored
All Things Open 2021, which had nearly 5,000 registered participants from 86 countries. We were also a Cornerstone Sponsor for
FOSDEM 2021's two-day virtual gathering.
Our contributing population continues to scale with the growth of Alphabet
In 2021, roughly 10% of Alphabet's full-time workforce (FTEs) actively contributed code or code-adjacent work to open source projects. This percentage has remained roughly consistent over the last five years, indicating that our open source contribution has continued to scale with the growth of Alphabet. Note that in 2021, FTEs represented over 95% of our open source contributors, while the remainder includes vendors, independent contractors, temporary staff, and interns that have contributed to open source projects during their tenure at Alphabet.
After
2020’s atypical growth—which was largely due to novel programs such as our
open source internships and
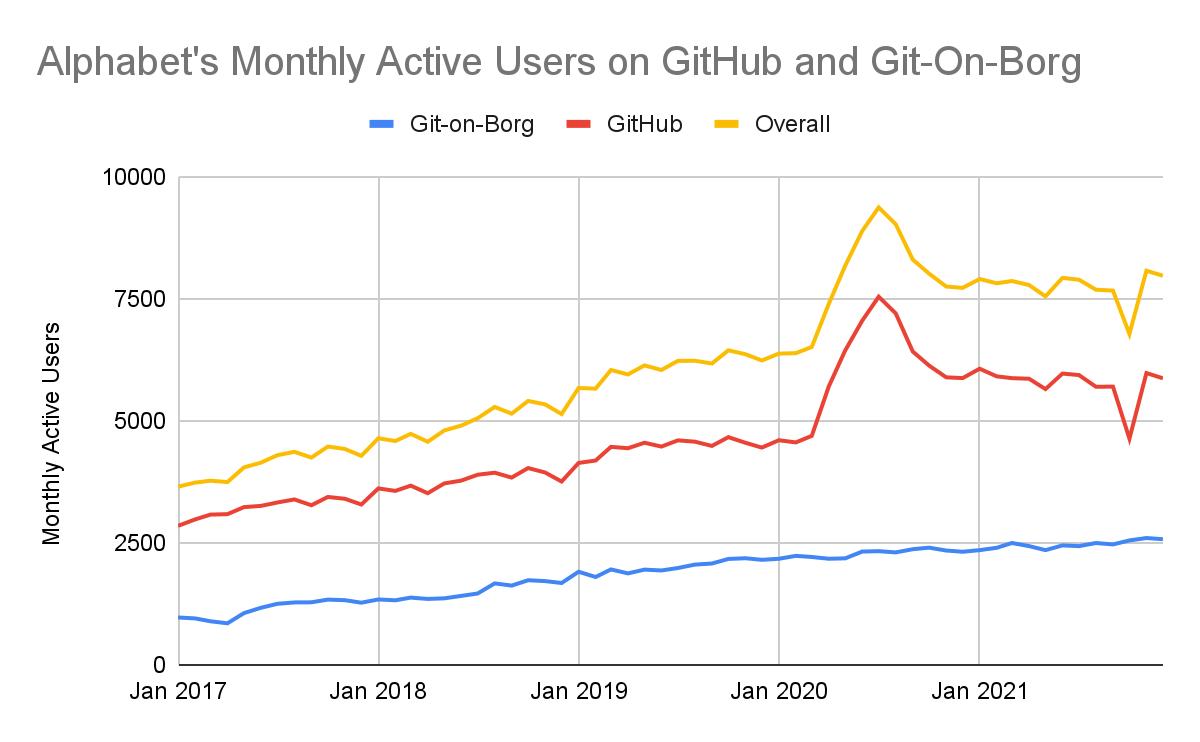
COVID-19 response work—in 2021, our activity numbers returned to pre-pandemic baselines. Over the last five years, the trajectory of monthly active usage has increased on both GitHub and Git-on-Borg by more than 15% on average each year.
Note that the dip in GitHub data reported in October of 2021 corresponds to an
outage on
GHarchive resulting in 4+ days of lost data (see figure below). Despite this outage, contribution levels remained fairly consistent month over month: more than 45% of our active contributing population for the year logged an activity on GitHub or Git-on-Borg in an average month.
 |
| For more details about the source data and analysis cited in this report, see “About this data.” below. |
The number of Alphabet open source projects remains steady
In 2021, we estimated that more than 2,000 open source projects that originated from Alphabet teams and employees were still active (not archived). To make this estimate, we chose a broad and variable definition of an open source project, including developer tools, utilities, languages, frameworks, libraries, demos, sample code, models, raw data, designs, and more. This estimate also includes personal projects that went through
Alphabet's releasing process but not projects that have been moved to or originated under external organizations or foundations.
Project counts should not be confused with repositories; projects can include many repositories. Within Alphabet, we maintain more than 9,500 public repositories on Github and 1,700 public repositories on Git-on-Borg. While these efforts originated at Google and Alphabet, these repositories are open for anyone to use, contribute to, fork or build on through open source licenses. In 2021, more than 500,000 unique GitHub accounts not affiliated with Alphabet employees contributed to Alphabet projects.
The majority of repositories we work on are outside of Alphabet organizations
Open source contributors at Alphabet work on a variety of projects and repositories—not just our own code. In 2021, contributors at Alphabet engaged with more than 70,000 repositories on GitHub (
WatchEvents or “stars” were removed from this count to represent active engagement), pushing commits and/or opening pull requests on over 49,000 repositories. Consistent with our 2019 and 2020 reports, more than 75% of repositories with pull requests opened by Alphabet contributors on GitHub were outside of Google-managed organizations.
We continue to invest in open source quality, security, and long term viability
Alphabet continues to rely on the health and availability of open source projects. Through internal efforts and collaboration with industry-led efforts such as
OpenSSF, Alphabet is committed to sharing relevant practices and tooling with the goal of improving overall code quality and bolstering the security posture of users and developers of open source software. We hope that by sharing our
internal frameworks and best practices, we can spark industry-wide discussion and progress on the security and sustainability of the open source ecosystem.
In 2021, we launched
Open Source Insights, a tool designed to list and visualize a project’s dependencies and their properties, helping developers review the packages that make up their software supply chains. The potential of this tool was put to the test after the disclosure of Log4j
vulnerabilities in December 2021. The
Open Source insights team reported that more than 35,000 Java packages, amounting to over 8% of the
Maven Central repository, were impacted by this vulnerability. As part of their investigation, they compiled a
list of 500 affected packages with some of the highest transitive usage to guide users and maintainers who were supporting patching and remediation activities.
In 2021, we also
announced our sponsorship of the
Secure Open Source (SOS) Rewards pilot program run by the Linux Foundation. This program financially rewards developers for enhancing the security of critical open source projects that we all depend on.
These efforts build on our existing open source security work, such as
OSS Fuzz, which was used by over 500 critical open source projects in 2021 and has helped find more than
7,000 vulnerabilities to date.
Our open source work will continue to grow and evolve to support the changing needs of our communities. Thank you to our colleagues and community members that continue to dedicate their personal and professional time supporting the open source ecosystem. Follow our work at
opensource.google.
By Sophia Vargas – Research Analyst and Amanda Casari, Open Source Researcher – Google Open Source Programs Office
About this data:
This report features metrics provided by many teams and programs across Alphabet. In regards to the data centered on code and code adjacent activities, we wanted to share more details about the derivation of those metrics:
- Data source: These data represent activities on repositories hosted on GitHub and our internal production Git service git-on-borg. These sources represent a subset of open source activity currently tracked by our OSPO.
- GitHub: We continue to use GitHub Archive as the primary source for GitHub data, which is available as a public dataset on BigQuery. Alphabet activity within GitHub is identified by self-registered accounts, which we estimate underreports actual activity.
- git-on-borg: This is our primary platform for internal projects and some of our larger, long running public projects like Android and Chromium. While we continue to develop on this platform, most of our open source activity has moved to GitHub to increase exposure and encourage community growth.
- Distinct event types: Note that git-on-borg and GitHub APIs produce distinct sets of events—as such we will report activity metrics per platform. Where GitHub Event logs capture a wide range of activity from code creation and review to issue creation and comments, the Gerrit Event stream (used by git-on-borg) only captures code changes and reviews.
- Driven by humans: We have created many automated bots and systems that can propose changes on various hosting platforms. We have intentionally filtered these data to focus on human-initiated activities. For our estimation of bots, we married our own records with a public list maintained by the devstats project
- Business and personal: Activity on GitHub reflects a mixture of Alphabet projects, third party projects, experimental efforts, and personal projects. Our metrics report on all of the above unless otherwise specified.
- Alphabet contributors: Please note that unless additional detail is specified, activity counts attributed to Alphabet open source contributors will include our full-time employees as well as our extended Alphabet community (temps, vendors, contractors, and interns).
- GitHub Accounts: For counts of Github accounts not affiliated with Alphabet, we cannot assume that 1 account translates to 1 person - as multiple accounts could be tied to one individual or bot accounts.
- Active counts: Where possible, we will show ‘active users’ defined by logged activity within a specified timeframe (i.e. in month, year, etc) and ‘active repositories’ and ‘active projects’ as those that have not been archived.
- Activity types: This year we explore GitHub activity types in more detail. Note that in some cases we have removed “Watch Events” or articulated this as passive engagement. Additionally, GitHub added an event type “PullRequestReviewEvent” that started logging activity in August 2020, but we chose to remove this from our charts and aggregate counts as it invalidates year over year comparisons.