There are many tasks within speech processing that are easier to solve by having large amounts of data. For example automatic speech recognition (ASR) translates spoken audio into text. In contrast, "non-semantic" tasks focus on the aspects of human speech other than its meaning, encompassing "paralinguistic" tasks, like speech emotion recognition, as well as other kinds of tasks, such as speaker identification, language identification, and certain kinds of voice-based medical diagnoses. In training systems to accomplish these tasks, one common approach is to utilize the largest datasets possible to help ensure good results. However, machine learning techniques that directly rely on massive datasets are often less successful when trained on small datasets.
One way to bridge the performance gap between large and small datasets is to train a representation model on a large dataset, then transfer it to a setting with less data. Representations can improve performance in two ways: they can make it possible to train small models by transforming high-dimensional data (like images and audio) to a lower dimension, and the representation model can also be used as pre-training. In addition, if the representation model is small enough to be run or trained on-device, it can improve performance in a privacy-preserving way by giving users the benefits of a personalized model where the raw data never leaves their device. While representation learning is commonly used in the text domain (e.g. BERT and ALBERT) and in the images domain (e.g. Inception layers and SimCLR), such approaches are underutilized in the speech domain.
 |
| Bottom:A large speech dataset is used to train a model, which is then rolled out to other environments. Top Left: On-device personalization — personalized, on-device models combine security and privacy. Top Middle: Small model on embeddings — general-use representations transform high-dimensional, few-example datasets to a lower dimension without sacrificing accuracy; smaller models train faster and are regularized. Top Right: Full model fine-tuning — large datasets can use the embedding model as pre-training to improve performance |
In "Towards Learning a Universal Non-Semantic Representation of Speech", we make three contributions to representation learning for speech-related applications. First, we present a NOn-Semantic Speech (NOSS) benchmark for comparing speech representations, which includes diverse datasets and benchmark tasks, such as speech emotion recognition, language identification, and speaker identification. These datasets are available in the "audio" section of TensorFlow Datasets. Second, we create and open-source TRIpLet Loss network (TRILL), a new model that is small enough to be executed and fine-tuned on-device, while still outperforming other representations. Third, we perform a large-scale study comparing different representations, and open-source the code used to compute the performance on new representations.
A New Benchmark for Speech Embeddings
For a benchmark to usefully guide model development, it must contain tasks that ought to have similar solutions and exclude those that are significantly different. Previous work either dealt with the variety of possible speech-based tasks independently, or lumped semantic and non-semantic tasks together. Our work improves performance on non-semantic speech tasks, in part, by focusing on neural network architectures that perform well specifically on this subset of speech tasks.
The tasks were selected for the NOSS benchmark on the basis of their 1) diversity — they need to cover a range of use-cases; 2) complexity — they should be challenging; and 3) availability, with particular emphasis on those tasks that are open-source. We combined six datasets of different sizes and tasks.
 |
| Datasets for downstream benchmark tasks. *VoxCeleb results in our study were computed using a subset of the dataset that was filtered according to internal policy. |
To help enable researchers to compare speech embeddings, we’ve added the six datasets in our benchmark to TensorFlow Datasets (in the "audio" section) and open sourced the evaluation framework.
TRILL: A New State of the Art in Non-semantic Speech Classification
Learning an embedding from one dataset and applying it to other tasks is not as common in speech as in other modalities. However, transfer learning, the more general technique of using data from one task to help another (not necessarily with embeddings), has some compelling applications, such as personalizing speech recognizers and voice imitation text-to-speech from few samples. There have been many previously proposed representations of speech, but most of these have been trained on a smaller and less diverse data, have been tested primarily on speech recognition, or both.
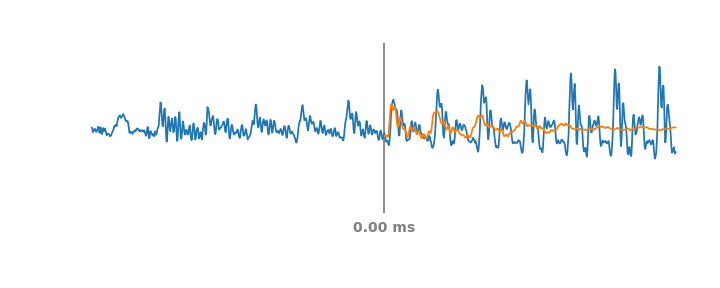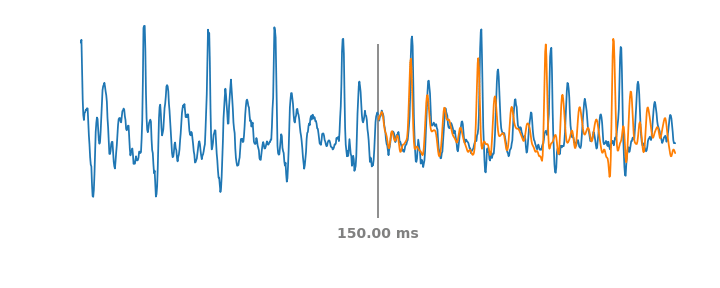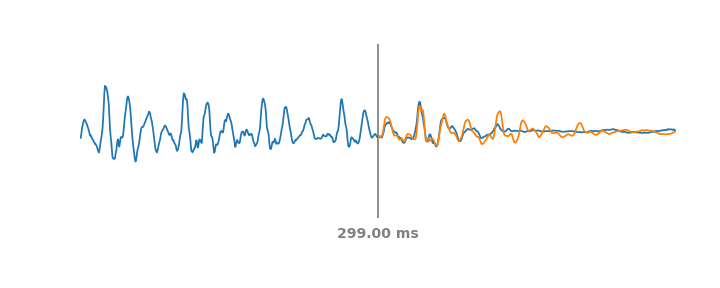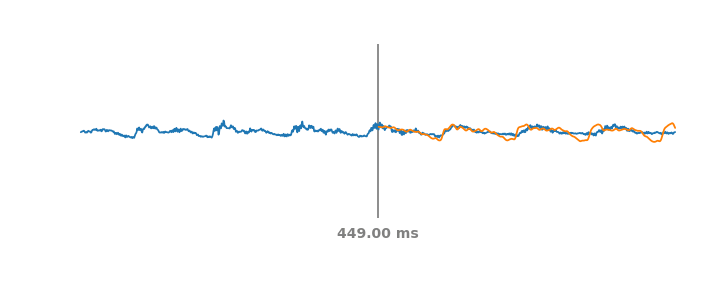
To create a data-derived representation of speech that was useful across environments and tasks, we started with AudioSet, a large and diverse dataset that includes about 2500 hours of speech. We then trained an embedding model on a simple, self-supervised criteria derived from previous work on metric learning — embeddings from the same audio should be closer in embedding space than embeddings from different audio. Like BERT and the other text embeddings, the self-supervised loss function doesn't require labels and only relies on the structure of the data itself. This form of self-supervision is the most appropriate for non-semantic speech, since non-semantic phenomena are more stable in time than ASR and other sub-second speech characteristics. This simple, self-supervised criteria captures a large number of acoustic properties that are leveraged in downstream tasks.
 |
| TRILL loss: Embeddings from the same audio are closer in embedding space than embeddings from different audio. |
Benchmark Results
We compared the performance of TRILL against other deep learning representations that are not focused on speech recognition and were trained on similarly diverse datasets. In addition, we compared TRILL to the popular OpenSMILE feature extractor, which uses pre-deep learning techniques (e.g., a fourier transform coefficients, "pitch tracking" using a time-series of pitch measurements, etc.), and randomly initialized networks, which have been shown to be strong baselines. To aggregate the performance across tasks that have different performance characteristics, we first train a small number of simple models, for a given task and embedding. The best result is chosen. Then, to understand the effect that a particular embedding has across all tasks, we calculate a linear regression on the observed accuracies, with both the model and task as the explanatory variables. The effect a model has on the accuracy is the coefficient associated with the model in the regression. For a given task, when changing from one model to another, the resulting change in accuracy is expected to be the difference in y-values in the figure below.
 |
| Effect of model on accuracy. |
Another benefit of a generally-useful model is that it can be used to initialize a model on a new task. When the sample size of a new task is small, fine-tuning an existing model may lead to better results than training the model from scratch. We achieved a new state-of-the-art result on three out of six benchmark tasks using this technique, despite doing no dataset-specific hyperparameter tuning.
To compare our new representation, we also tested it on the mask sub-challenge of the Interspeech 2020 Computational Paralinguistics Challenge (ComParE). In this challenge, models must predict whether a speaker is wearing a mask, which would affect their speech. The mask effects are sometimes subtle, and audio clips are only one second long. A linear model on TRILL outperformed the best baseline model, which was a fusion of many models on different kinds of features including traditional spectral and deep-learned features.
Summary
The code to evaluate NOSS is available on GitHub, the datasets are on TensorFlow Datasets, and the TRILL models are available on AI Hub.
The NOn-Semantic Speech benchmark helps researchers create speech embeddings that are useful in a wide range of contexts, including for personalization and small-dataset problems. We provide the TRILL model to the research community as a baseline embedding to surpass.
Acknowledgements
The core team behind this work includes Joel Shor, Aren Jansen, Ronnie Maor, Oran Lang, Omry Tuval, Felix de Chaumont Quitry, Marco Tagliasacchi, Ira Shavitt, Dotan Emanuel, and Yinnon Haviv. We'd also like to thank Avinatan Hassidim and Yossi Matias for technical guidance.