The ability to perceive the shape and motion of hands can be a vital component in improving the user experience across a variety of technological domains and platforms. For example, it can form the basis for sign language understanding and hand gesture control, and can also enable the overlay of digital content and information on top of the physical world in augmented reality. While coming naturally to people, robust real-time hand perception is a decidedly challenging computer vision task, as hands often occlude themselves or each other (e.g. finger/palm occlusions and hand shakes) and lack high contrast patterns.
Today we are announcing the release of a new approach to hand perception, which we previewed CVPR 2019 in June, implemented in MediaPipe—an open source cross platform framework for building pipelines to process perceptual data of different modalities, such as video and audio. This approach provides high-fidelity hand and finger tracking by employing machine learning (ML) to infer 21 3D keypoints of a hand from just a single frame. Whereas current state-of-the-art approaches rely primarily on powerful desktop environments for inference, our method achieves real-time performance on a mobile phone, and even scales to multiple hands. We hope that providing this hand perception functionality to the wider research and development community will result in an emergence of creative use cases, stimulating new applications and new research avenues.
 |
| 3D hand perception in real-time on a mobile phone via MediaPipe. Our solution uses machine learning to compute 21 3D keypoints of a hand from a video frame. Depth is indicated in grayscale. |
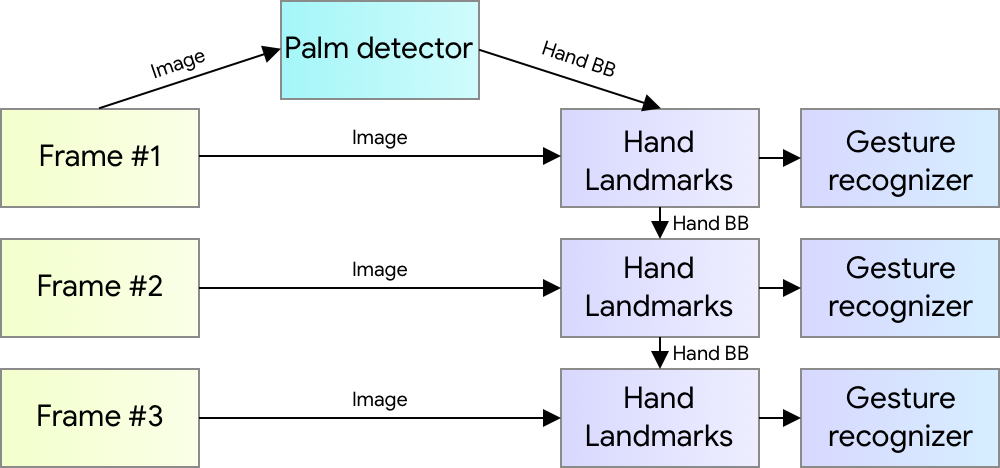
Our hand tracking solution utilizes an ML pipeline consisting of several models working together:
- A palm detector model (called BlazePalm) that operates on the full image and returns an oriented hand bounding box.
- A hand landmark model that operates on the cropped image region defined by the palm detector and returns high fidelity 3D hand keypoints.
- A gesture recognizer that classifies the previously computed keypoint configuration into a discrete set of gestures.
 |
| Hand perception pipeline overview. |
To detect initial hand locations, we employ a single-shot detector model called BlazePalm, optimized for mobile real-time uses in a manner similar to BlazeFace, which is also available in MediaPipe. Detecting hands is a decidedly complex task: our model has to work across a variety of hand sizes with a large scale span (~20x) relative to the image frame and be able to detect occluded and self-occluded hands. Whereas faces have high contrast patterns, e.g., in the eye and mouth region, the lack of such features in hands makes it comparatively difficult to detect them reliably from their visual features alone. Instead, providing additional context, like arm, body, or person features, aids accurate hand localization.
Our solution addresses the above challenges using different strategies. First, we train a palm detector instead of a hand detector, since estimating bounding boxes of rigid objects like palms and fists is significantly simpler than detecting hands with articulated fingers. In addition, as palms are smaller objects, the non-maximum suppression algorithm works well even for two-hand self-occlusion cases, like handshakes. Moreover, palms can be modelled using square bounding boxes (anchors in ML terminology) ignoring other aspect ratios, and therefore reducing the number of anchors by a factor of 3-5. Second, an encoder-decoder feature extractor is used for bigger scene context awareness even for small objects (similar to the RetinaNet approach). Lastly, we minimize the focal loss during training to support a large amount of anchors resulting from the high scale variance.
With the above techniques, we achieve an average precision of 95.7% in palm detection. Using a regular cross entropy loss and no decoder gives a baseline of just 86.22%.
Hand Landmark Model
After the palm detection over the whole image our subsequent hand landmark model performs precise keypoint localization of 21 3D hand-knuckle coordinates inside the detected hand regions via regression, that is direct coordinate prediction. The model learns a consistent internal hand pose representation and is robust even to partially visible hands and self-occlusions.
To obtain ground truth data, we have manually annotated ~30K real-world images with 21 3D coordinates, as shown below (we take Z-value from image depth map, if it exists per corresponding coordinate). To better cover the possible hand poses and provide additional supervision on the nature of hand geometry, we also render a high-quality synthetic hand model over various backgrounds and map it to the corresponding 3D coordinates.
 |
| Top: Aligned hand crops passed to the tracking network with ground truth annotation. Bottom: Rendered synthetic hand images with ground truth annotation |
 |
| Mixed training schema for hand tracking network. Cropped real-world photos and rendered synthetic images are used as input to predict 21 3D keypoints. |
| Mean regression error | |
|---|---|
| Dataset | normalized by palm size |
| Only real-world | 16.1 % |
| Only rendered synthetic | 25.7 % |
| Mixed real-world + synthetic | 13.4 % |
Gesture Recognition
On top of the predicted hand skeleton, we apply a simple algorithm to derive the gestures. First, the state of each finger, e.g. bent or straight, is determined by the accumulated angles of joints. Then we map the set of finger states to a set of pre-defined gestures. This straightforward yet effective technique allows us to estimate basic static gestures with reasonable quality. The existing pipeline supports counting gestures from multiple cultures, e.g. American, European, and Chinese, and various hand signs including “Thumb up”, closed fist, “OK”, “Rock”, and “Spiderman”.
 |  |
Implementation via MediaPipe
With MediaPipe, this perception pipeline can be built as a directed graph of modular components, called Calculators. Mediapipe comes with an extendable set of Calculators to solve tasks like model inference, media processing algorithms, and data transformations across a wide variety of devices and platforms. Individual calculators like cropping, rendering and neural network computations can be performed exclusively on the GPU. For example, we employ TFLite GPU inference on most modern phones.
Our MediaPipe graph for hand tracking is shown below. The graph consists of two subgraphs—one for hand detection and one for hand keypoints (i.e., landmark) computation. One key optimization MediaPipe provides is that the palm detector is only run as necessary (fairly infrequently), saving significant computation time. We achieve this by inferring the hand location in the subsequent video frames from the computed hand key points in the current frame, eliminating the need to run the palm detector over each frame. For robustness, the hand tracker model outputs an additional scalar capturing the confidence that a hand is present and reasonably aligned in the input crop. Only when the confidence falls below a certain threshold is the hand detection model reapplied to the whole frame.
 |
| The hand landmark model’s output (REJECT_HAND_FLAG) controls when the hand detection model is triggered. This behavior is achieved by MediaPipe’s powerful synchronization building blocks, resulting in high performance and optimal throughput of the ML pipeline. |
Future Directions
We plan to extend this technology with more robust and stable tracking, enlarge the amount of gestures we can reliably detect, and support dynamic gestures unfolding in time. We believe that publishing this technology can give an impulse to new creative ideas and applications by the members of the research and developer community at large. We are excited to see what you can build with it!

Special thanks to all our team members who worked on the tech with us: Andrey Vakunov, Andrei Tkachenka, Yury Kartynnik, Artsiom Ablavatski, Ivan Grishchenko, Kanstantsin Sokal, Mogan Shieh, Ming Guang Yong, Anastasia Tkach, Jonathan Taylor, Sean Fanello, Sofien Bouaziz, Juhyun Lee, Chris McClanahan, Jiuqiang Tang, Esha Uboweja, Hadon Nash, Camillo Lugaresi, Michael Hays, Chuo-Ling Chang, Matsvei Zhdanovich and Matthias Grundmann.
