Machine learning-based language models trained to predict the next word in a sentence have become increasingly capable, common, and useful, leading to groundbreaking improvements in applications like question-answering, translation, and more. But as language models continue to advance, new and unexpected risks can be exposed, requiring the research community to proactively work to develop new ways to mitigate potential problems.
One such risk is the potential for models to leak details from the data on which they’re trained. While this may be a concern for all large language models, additional issues may arise if a model trained on private data were to be made publicly available. Because these datasets can be large (hundreds of gigabytes) and pull from a range of sources, they can sometimes contain sensitive data, including personally identifiable information (PII) — names, phone numbers, addresses, etc., even if trained on public data. This raises the possibility that a model trained using such data could reflect some of these private details in its output. It is therefore important to identify and minimize the risks of such leaks, and to develop strategies to address the issue for future models.
 |
| If one prompts the GPT-2 language model with the prefix “East Stroudsburg Stroudsburg...”, it will autocomplete a long block of text that contains the full name, phone number, email address, and physical address of a particular person whose information was included in GPT-2’s training data. |
In “Extracting Training Data from Large Language Models”, a collaboration with OpenAI, Apple, Stanford, Berkeley, and Northeastern University, we demonstrate that, given only the ability to query a pre-trained language model, it is possible to extract specific pieces of training data that the model has memorized. As such, training data extraction attacks are realistic threats on state-of-the-art large language models. This research represents an early, critical step intended to inform researchers about this class of vulnerabilities, so that they may take steps to mitigate these weaknesses.
Ethics of Language Model Attacks
A training data extraction attack has the greatest potential for harm when applied to a model that is available to the public, but for which the dataset used in training is not. However, since conducting this research on such a dataset could have harmful consequences, we instead mount a proof of concept training data extraction attack on GPT-2, a large, publicly available language model developed by OpenAI, that was trained using only public data. While this work focuses on GPT-2 specifically, the results apply to understanding what privacy threats are possible on large language models generally.
As with other privacy- and security-related research, it is important to consider the ethics of such attacks before actually performing them. To minimize the potential risk of this work, the training data extraction attack in this work was developed using publicly available data. Furthermore, the GPT-2 model itself was made public by OpenAI in 2019, and the training data used to train GPT-2 was collected from the public internet, and is available for download by anyone who follows the data collection process documented in the GPT-2 paper.
Additionally, in accordance with responsible computer security disclosure norms, we followed up with individuals whose PII was extracted, and secured their permission before including references to this data in publication. Further, in all publications of this work, we have redacted any personally identifying information that may identify individuals. We have also worked closely with OpenAI in the analysis of GPT-2.
The Training Data Extraction Attack
By design, language models make it very easy to generate a large amount of output data. By seeding the model with random short phrases, the model can generate millions of continuations, i.e., probable phrases that complete the sentence. Most of the time, these continuations will be benign strings of sensible text. For example, when asked to predict the continuation of the string “Mary had a little…”, a language model will have high confidence that the next token is the word “lamb”. However, if one particular training document happened to repeat the string “Mary had a little wombat” many times, the model might predict that phrase instead.
The goal of a training data extraction attack is then to sift through the millions of output sequences from the language model and predict which text is memorized. To accomplish this, our approach leverages the fact that models tend to be more confident on results captured directly from their training data. These membership inference attacks enable us to predict if a result was used in the training data by checking the confidence of the model on a particular sequence.
The main technical contribution of this work is the development of a method for inferring membership with high accuracy along with techniques for sampling from models in a way that encourages the output of memorized content. We tested a number of different sampling strategies, the most successful of which generates text conditioned on a wide variety of input phrases. We then compare the output of two different language models. When one model has high confidence in a sequence, but the other (equally accurate) model has low confidence in a sequence, it's likely that the first model has memorized the data.
Results
Out of 1800 candidate sequences from the GPT-2 language model, we extracted over 600 that were memorized from the public training data, with the total number limited by the need for manual verification. The memorized examples cover a wide range of content, including news headlines, log messages, JavaScript code, PII, and more. Many of these examples are memorized even though they appear infrequently in the training dataset. For example, for many samples of PII we extract are found in only a single document in the dataset. However, in most of these cases, the originating document contains multiple instances of the PII, and as a result, the model still learns it as high likelihood text.
Finally, we also find that the larger the language model, the more easily it memorizes training data. For example, in one experiment we find that the 1.5 billion parameter GPT-2 XL model memorizes 10 times more information than the 124 million parameter GPT-2 Small model. Given that the research community has already trained models 10 to 100 times larger, this means that as time goes by, more work will be required to monitor and mitigate this problem in increasingly large language models.
Lessons
While we demonstrate these attacks on GPT-2 specifically, they show potential flaws in all large generative language models. The fact that these attacks are possible has important consequences for the future of machine learning research using these types of models.
Fortunately, there are several ways to mitigate this issue. The most straightforward solution is to ensure that models do not train on any potentially problematic data. But this can be difficult to do in practice.
The use of differential privacy, which allows training on a dataset without revealing any details of individual training examples, is one of the most principled techniques to train machine learning models with privacy. In TensorFlow, this can be achieved with the use of the tensorflow/privacy module (or similar for PyTorch or JAX) that is a drop-in replacement for existing optimizers. Even this can have limitations and won’t prevent memorization of content that is repeated often enough. If this is not possible, we recommend at least measuring how much memorization occurs so appropriate action can be taken.
Language models continue to demonstrate great utility and flexibility—yet, like all innovations, they can also pose risks. Developing them responsibly means proactively identifying those risks and developing ways to mitigate them. We hope that this effort to highlight current weaknesses in large language modeling will raise awareness of this challenge in the broader machine learning community and motivate researchers to continue to develop effective techniques to train models with reduced memorization.
Acknowledgements
This work was performed jointly with Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel.

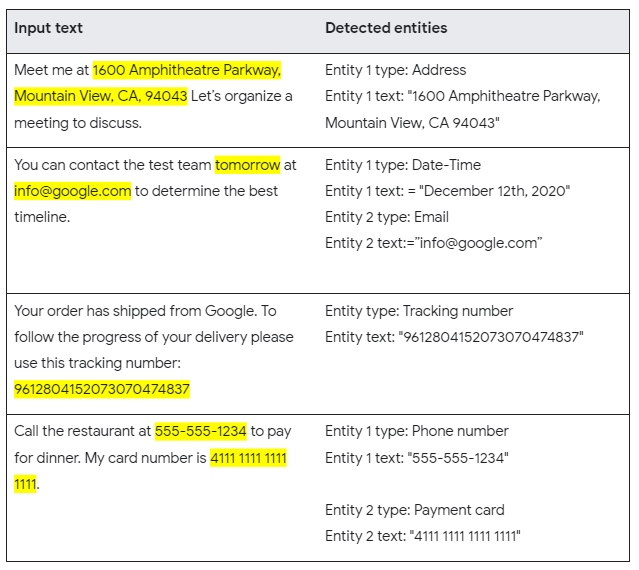
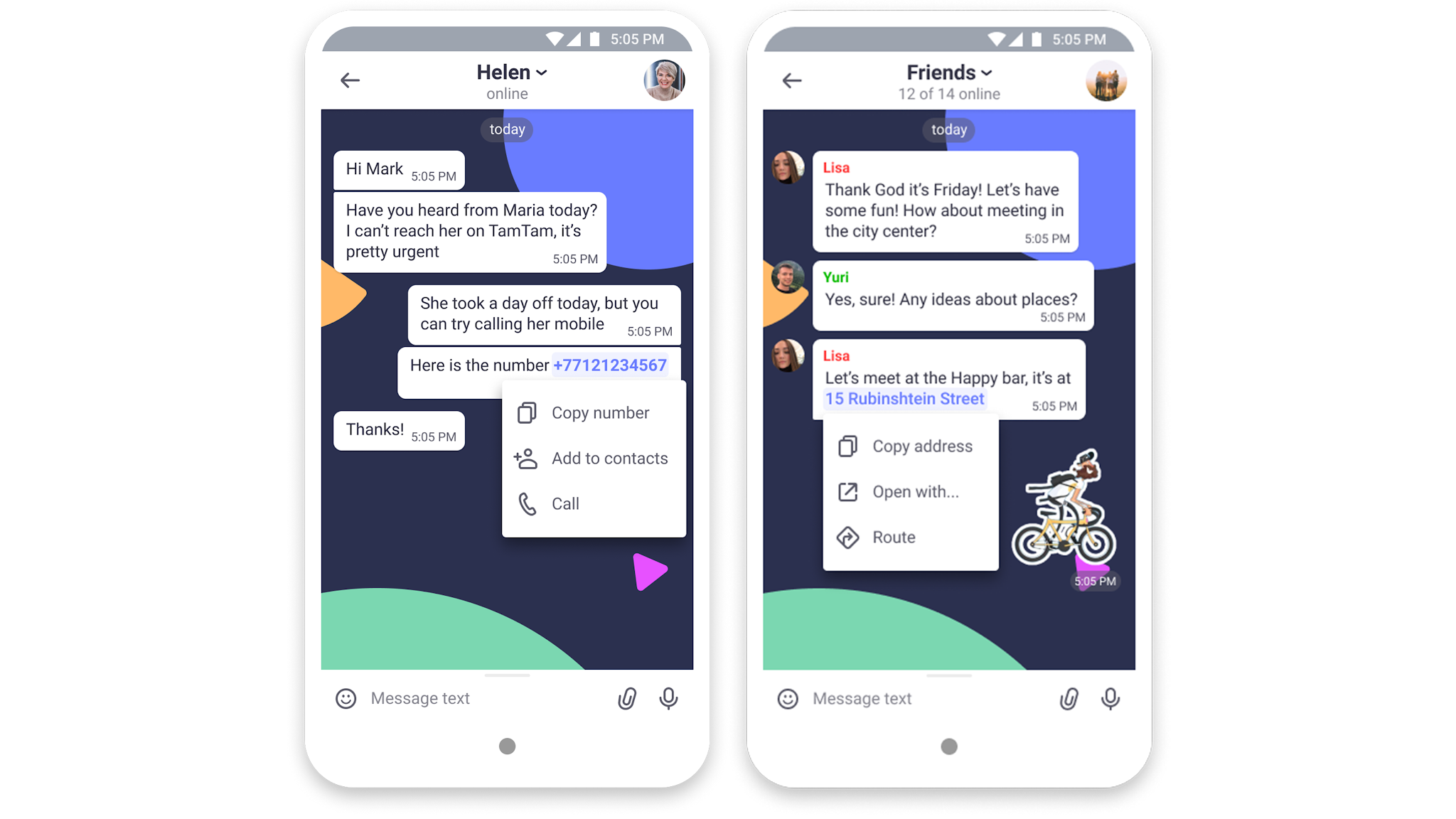
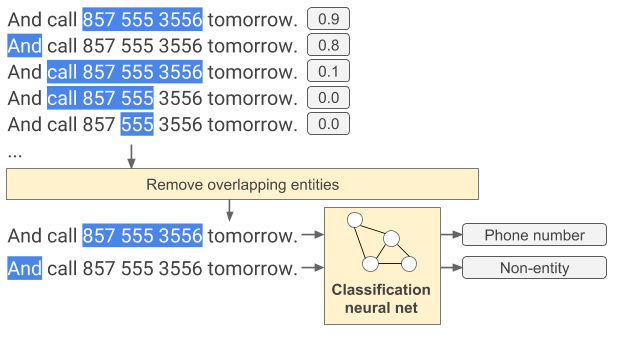
 Posted by Kenny Sulaimon, Product Manager, ML Kit, Tory Voight, Product Manager, ML Kit, Daniel Furlong, Lei Yu, Software Engineers, ML Kit, Dong Chen, Technical Lead, MLKit
Posted by Kenny Sulaimon, Product Manager, ML Kit, Tory Voight, Product Manager, ML Kit, Daniel Furlong, Lei Yu, Software Engineers, ML Kit, Dong Chen, Technical Lead, MLKit