Posted by Michael Schoenberg, uDepth Software Lead and Adarsh Kowdle, uDepth Hardware/Systems Lead, Google Research The ability to determine 3D information about the scene, called
depth sensing, is a valuable tool for developers and users alike. Depth sensing is a very active area of computer vision research with recent innovations ranging from applications like
portrait mode and
AR to fundamental sensing innovations such as
transparent object detection. Typical RGB-based stereo depth sensing techniques can be computationally expensive, suffer in regions with low texture, and fail completely in extreme low light conditions.
Because the
Face Unlock feature on Pixel 4 must work at high speed and in darkness, it called for a different approach. To this end, the front of the Pixel 4 contains a real-time infrared (IR) active stereo depth sensor, called uDepth. A key computer vision capability on the Pixel 4, this technology helps the authentication system identify the user while also protecting against spoof attacks. It also supports a number of novel capabilities, such as after-the-fact photo retouching, depth-based segmentation of a scene, background blur, portrait effects and 3D photos.
Recently, we provided access to uDepth as an API on
Camera2, using the
Pixel Neural Core, two IR cameras, and an IR pattern projector to provide time-synchronized depth frames (in
DEPTH16) at 30Hz. The Google Camera App uses this API to bring
improved depth capabilities to selfies taken on the Pixel 4. In this post, we explain broadly how uDepth works, elaborate on the underlying algorithms, and discuss applications with example results for the Pixel 4.
Overview of Stereo Depth SensingAll stereo camera systems reconstruct depth using
parallax. To observe this effect, look at an object, close one eye, then switch which eye is closed. The apparent position of the object will shift, with closer objects appearing to move more. uDepth is part of the family of
dense local stereo matching techniques, which estimate parallax computationally for each pixel. These techniques evaluate a region surrounding each pixel in the image formed by one camera, and try to find a similar region in the corresponding image from the second camera. When calibrated properly, the reconstructions generated are
metric, meaning that they express real physical distances.
 |
| Pixel 4 front sensor setup, an example of an active stereo system. |
To deal with textureless regions and cope with low-light conditions, we make use of an “active stereo” setup, which projects an IR pattern into the scene that is detected by stereo IR cameras. This approach makes low-texture regions easier to identify, improving results and reducing the computational requirements of the system.
What Makes uDepth Distinct?Stereo sensing systems can be extremely computationally intensive, and it’s critical that a sensor running at 30Hz is low power while remaining high quality. uDepth leverages a number of key insights to accomplish this.
One such insight is that given a pair of regions that are similar to each other, most corresponding subsets of those regions are also similar. For example, given two 8x8 patches of pixels that are similar, it is very likely that the top-left 4x4 sub-region of each member of the pair is also similar. This informs the uDepth pipeline’s initialization procedure, which builds a pyramid of depth proposals by comparison of non-overlapping tiles in each image and selecting those most similar. This process starts with 1x1 tiles, and accumulates support hierarchically until an initial low-resolution depth map is generated.
After initialization, we apply a novel technique for
neural depth refinement to support the regular grid pattern illuminator on the Pixel 4. Typical active stereo systems project a pseudo-random grid pattern to help disambiguate matches in the scene, but uDepth is capable of supporting repeating grid patterns as well. Repeating structure in such patterns produces regions that look similar across stereo pairs, which can lead to incorrect matches. We mitigate this issue using a lightweight (75k parameter) convolutional architecture, using IR brightness and neighbor information to adjust incorrect matches — in less than 1.5ms per frame.
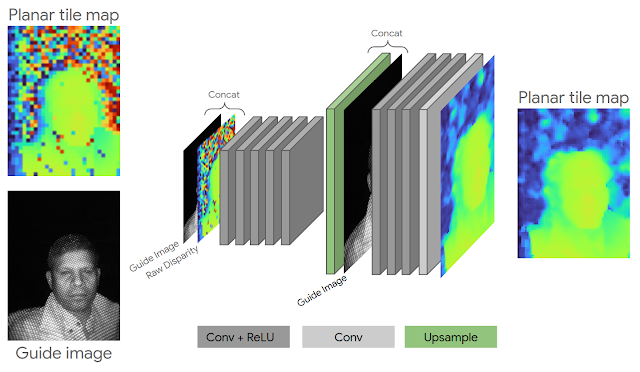 |
| Neural depth refinement architecture. |
Following neural depth refinement, good depth estimates are iteratively propagated from neighboring tiles. This and following pipeline steps leverage another insight key to the success of uDepth — natural scenes are typically locally planar with only small nonplanar deviations. This permits us to find planar tiles that cover the scene, and only later refine individual depths for each pixel in a tile, greatly reducing computational load.
Finally, the best match from among neighboring plane hypotheses is selected, with subpixel refinement and invalidation if no good match could be found.
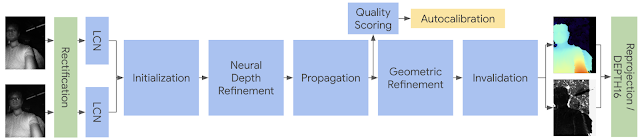 |
| Simplified depth architecture. Green components run on the GPU, yellow on the CPU, and blue on the Pixel Neural Core. |
When a phone experiences a severe drop, it can result in the factory calibration of the stereo cameras diverging from the
actual position of the cameras. To ensure high-quality results during real-world use, the uDepth system is self-calibrating. A scoring routine evaluates every depth image for signs of miscalibration, and builds up confidence in the state of the device. If miscalibration is detected, calibration parameters are regenerated from the current scene. This follows a pipeline consisting of feature detection and correspondence, subpixel refinement (taking advantage of the dot profile), and bundle adjustment.
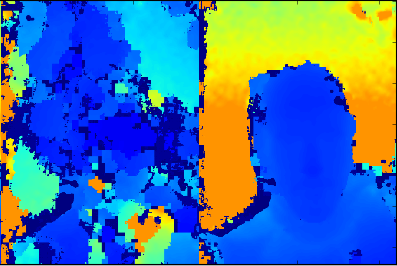 |
| Left: Stereo depth with inaccurate calibration. Right: After autocalibration. |
For more details, please refer to
Slanted O(1) Stereo, upon which uDepth is based.
Depth for Computational PhotographyThe raw data from the uDepth sensor is designed to be accurate and metric, which is a fundamental requirement for Face Unlock. Computational photography applications such as
portrait mode and 3D photos have very different needs. In these use cases, it is not critical to achieve video frame rates, but the depth should be smooth, edge-aligned and complete in the whole field-of-view of the color camera.
 |
| Left to right: raw depth sensing result, predicted depth, 3D photo. Notice the smooth rotation of the wall, demonstrating a continuous depth gradient rather than a single focal plane. |
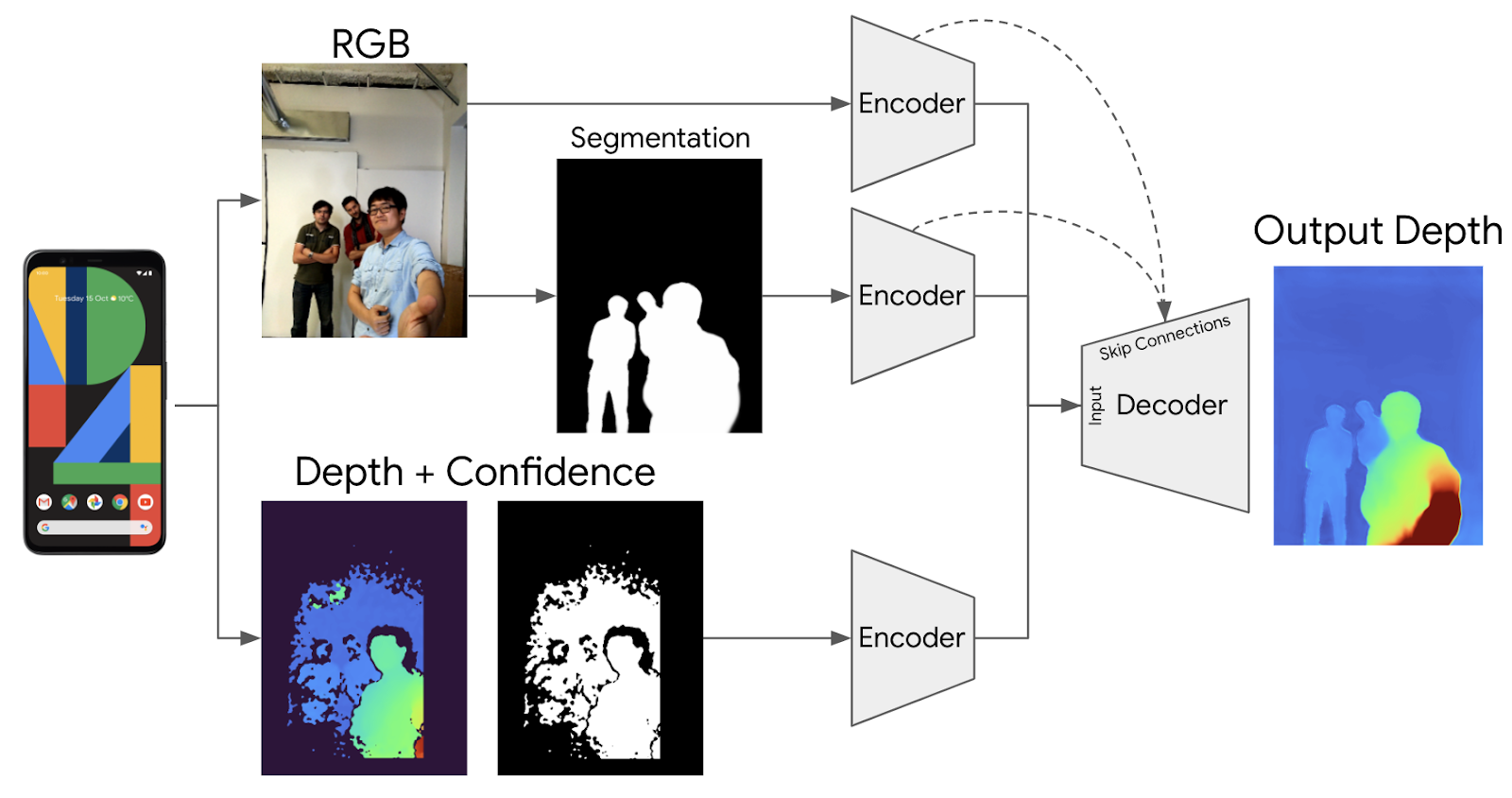
To achieve this we trained an end-to-end deep learning architecture that enhances the raw uDepth data, inferring a complete, dense 3D depth map. We use a combination of RGB images, people segmentation, and raw depth, with a
dropout scheme forcing use of information for each of the inputs.
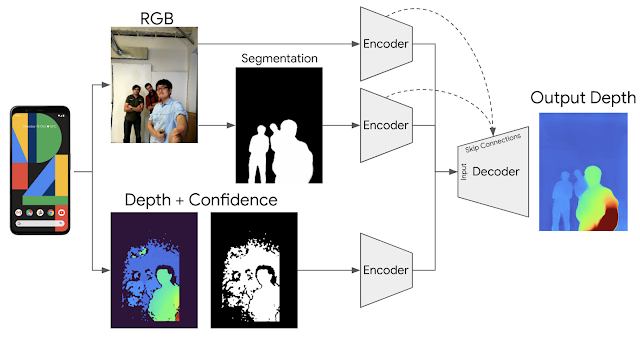 |
| Architecture for computational photography depth enhancement. |
To acquire ground truth, we leveraged
a volumetric capture system that can produce near-photorealistic models of people using a geodesic sphere outfitted with 331 custom color LED lights, an array of high-resolution cameras, and a set of custom high-resolution depth sensors. We added Pixel 4 phones to the setup and synchronized them with the rest of the hardware (lights and cameras). The generated training data consists of a combination of real images as well as synthetic renderings from the Pixel 4 camera viewpoint.
 |
| Data acquisition overview. |
Putting It All TogetherWith all of these components in place, uDepth produces both a depth stream at 30Hz (exposed via Camera2), and smooth, post-processed depth maps for photography (exposed via Google Camera App when you take a depth-enabled selfie). The smooth, dense, per-pixel depth that our system produces is available on every Pixel 4 selfie with Social Media Depth features enabled, and can be used for post-capture effects such as
bokeh and 3D photos for social media.
 |
 |
| Example applications. Notice the multiple focal planes in the 3D photo on the right. |
Finally, we are happy to provide a demo application for you to play with that visualizes a real-time point cloud from uDepth — download it
here (this app is for demonstration and research purposes only and not intended for commercial use; Google will not provide any support or updates). This demo app visualizes 3D point clouds from your Pixel 4 device. Because the depth maps are time-synchronized and in the same coordinate system as the RGB images, a textured view of the 3D scene can be shown, as in the example visualization below:
 |
| Example single-frame, RGB point cloud from uDepth on the Pixel 4. |
AcknowledgementsThis work would not have been possible without the contributions of many, many people, including but not limited to Peter Barnum, Cheng Wang, Matthias Kramm, Jack Arendt, Scott Chung, Vaibhav Gupta, Clayton Kimber, Jeremy Swerdlow, Vladimir Tankovich, Christian Haene, Yinda Zhang, Sergio Orts Escolano, Sean Ryan Fanello, Anton Mikhailov, Philippe Bouchilloux, Mirko Schmidt, Ruofei Du, Karen Zhu, Charlie Wang, Jonathan Taylor, Katrina Passarella, Eric Meisner, Vitalii Dziuba, Ed Chang, Phil Davidson, Rohit Pandey, Pavel Podlipensky, David Kim, Jay Busch, Cynthia Socorro Herrera, Matt Whalen, Peter Lincoln, Geoff Harvey, Christoph Rhemann, Zhijie Deng, Daniel Finchelstein, Jing Pu, Chih-Chung Chang, Eddy Hsu, Tian-yi Lin, Sam Chang, Isaac Christensen, Donghui Han, Speth Chang, Zhijun He, Gabriel Nava, Jana Ehmann, Yichang Shih, Chia-Kai Liang, Isaac Reynolds, Dillon Sharlet, Steven Johnson, Zalman Stern, Jiawen Chen, Ricardo Martin Brualla, Supreeth Achar, Mike Mehlman, Brandon Barbello, Chris Breithaupt, Michael Rosenfield, Gopal Parupudi, Steve Goldberg, Tim Knight, Raj Singh, Shahram Izadi, as well as many other colleagues across Devices and Services, Google Research, Android and X.