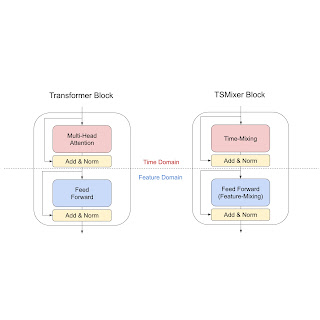
Typical deep learning models for computer vision, like convolutional neural networks (CNNs) and vision transformers (ViT), process signals assuming planar (flat) spaces. For example, digital images are represented as a grid of pixels on a plane. However, this type of data makes up only a fraction of the data we encounter in scientific applications. Variables sampled from the Earth's atmosphere, like temperature and humidity, are naturally represented on the sphere. Some kinds of cosmological data and panoramic photos are also spherical signals, and are better treated as such.
Using methods designed for planar images to process spherical signals is problematic for a couple of reasons. First, there is a sampling problem, i.e., there is no way of defining uniform grids on the sphere, which are needed for planar CNNs and ViTs, without heavy distortion.
 |
| When projecting the sphere into a plane, the patch represented by the red circle is heavily distorted near the poles. This sampling problem hurts the accuracy of conventional CNNs and ViTs on spherical inputs. |
Second, signals and local patterns on the sphere are often complicated by rotations, so models need a way to address that. We would like equivariance to 3D rotations, which ensures that learned features follow the rotations of the input. This leads to better utilization of the model parameters and allows training with less data. Equivariance to 3D rotations is also useful in most settings where inputs don’t have a preferred orientation, such as 3D shapes and molecules.
 |
| Drone racing with panoramic cameras. Here the sharp turns result in large 3D rotations of the spherical image. We would like our models to be robust to such rotations. Source: https://www.youtube.com/watch?v=_J7qXbbXY80 (licensed under CC BY) |
 |
| In the atmosphere, it is common to see similar patterns appearing at different positions and orientations. We would like our models to share parameters to recognize these patterns. |
With the above challenges in mind, in “Scaling Spherical CNNs”, presented at ICML 2023, we introduce an open-source library in JAX for deep learning on spherical surfaces. We demonstrate how applications of this library match or surpass state-of-the-art performance on weather forecasting and molecular property prediction benchmarks, tasks that are typically addressed with transformers and graph neural networks.
Background on spherical CNNs
Spherical CNNs solve both the problems of sampling and of robustness to rotation by leveraging spherical convolution and cross-correlation operations, which are typically computed via generalized Fourier transforms. For planar surfaces, however, convolution with small filters is faster, because it can be performed on regular grids without using Fourier transforms. The higher computational cost for spherical inputs has so far restricted the application of spherical CNNs to small models and datasets and low resolution datasets.
Our contributions
We have implemented the spherical convolutions from spin-weighted spherical CNNs in JAX with a focus on speed, and have enabled distributed training over a large number of TPUs using data parallelism. We also introduced a new phase collapse activation and spectral batch normalization layer, and a new residual block that improves accuracy and efficiency, which allows training more accurate models up to 100x larger than before. We apply these new models on molecular property regression and weather forecasting.
 |
| We scale spherical CNNs by up to two orders of magnitude in terms of feature sizes and model capacity, compared to the literature: Cohen’18, Esteves’18, Esteves’20, and Cobb’21. VGG-19 is included as a conventional CNN reference. Our largest model for weather forecasting has 256 x 256 x 78 inputs and outputs, and runs 96 convolutional layers during training with a lowest internal resolution of 128 x 128 x 256. |
Molecular property regression
Predicting properties of molecules has applications in drug discovery, where the goal is to quickly screen numerous molecules in search of those with desirable properties. Similar models may also be relevant in the design of drugs targeting the interaction between proteins. Current methods in computational or experimental quantum chemistry are expensive, which motivates the use of machine learning.
Molecules can be represented by a set of atoms and their positions in 3D space; rotations of the molecule change the positions but not the molecular properties. This motivates the application of spherical CNNs because of their rotation equivariance. However, molecules are not defined as signals on the sphere so the first step is to map them to a set of spherical functions. We do so by leveraging physics-based interactions between the atoms of the molecule.
 |
| Each atom is represented by a set of spherical signals accumulating physical interactions with other atoms of each type (shown in the three panels on the right). For example, the oxygen atom (O; top panel) has a channel for oxygen (indicated by the sphere labeled “O” on the left) and hydrogen (“H”, right). The accumulated Coulomb forces on the oxygen atom with respect to the two hydrogen atoms is indicated by the red shaded regions on the bottom of the sphere labeled “H”. Because the oxygen atom contributes no forces to itself, the “O” sphere is uniform. We include extra channels for the Van der Waals forces. |
Spherical CNNs are applied to each atom's features, and results are later combined to produce the property predictions. This results in state-of-the art performance in most properties as typically evaluated in the QM9 benchmark:
 |
| Error comparison against the state-of-the-art on 12 properties of QM9 (see the dataset paper for details). We show TorchMD-Net and PaiNN results, normalizing TorchMD-Net errors to 1.0 (lower is better). Our model, shown in green, outperforms the baselines in most targets. |
Weather forecasting
Accurate climate forecasts serve as invaluable tools for providing timely warnings of extreme weather events, enabling effective water resource management, and guiding informed infrastructure planning. In a world increasingly threatened by climate disasters, there is an urgency to deliver forecasts much faster and more accurately over a longer time horizon than general circulation models. Forecasting models will also be important for predicting the safety and effectiveness of efforts intended to combat climate change, such as climate interventions. The current state-of-the-art uses costly numerical models based on fluid dynamics and thermodynamics, which tend to drift after a few days.
Given these challenges, there is an urgency for machine learning researchers to address climate forecasting problems, as data-driven techniques have the potential of both reducing the computational cost and improving long range accuracy. Spherical CNNs are suitable for this task since atmospheric data is natively presented on the sphere. They can also efficiently handle repeating patterns at different positions and orientations that are common in such data.
We apply our models to several weather forecasting benchmarks and outperform or match neural weather models based on conventional CNNs (specifically, 1, 2, and 3). Below we show results in a test setting where the model takes a number of atmospheric variables as input and predicts their values six hours ahead. The model is then iteratively applied on its own predictions to produce longer forecasts. During training, the model predicts up to three days ahead, and is evaluated up to five days. Keisler proposed a graph neural network for this task, but we show that spherical CNNs can match the GNN accuracy in the same setting.
 |
| Iterative weather forecasting up to five days (120h) ahead with spherical CNNs. The animations show the specific humidity forecast at a given pressure and its error. |
 |
| Wind speed and temperature forecasts with spherical CNNs. |
Additional resources
Our JAX library for efficient spherical CNNs is now available. We have shown applications to molecular property regression and weather forecasting, and we believe the library will be helpful in other scientific applications, as well as in computer vision and 3D vision.
Weather forecasting is an active area of research at Google with the goal of building more accurate and robust models — like Graphcast, a recent ML-based mid-range forecasting model — and to build tools that enable further advancement across the research community, such as the recently released WeatherBench 2.
Acknowledgements
This work was done in collaboration with Jean-Jacques Slotine, and is based on previous collaborations with Kostas Daniilidis and Christine Allen-Blanchette. We thank Stephan Hoyer, Stephan Rasp, and Ignacio Lopez-Gomez for helping with data processing and evaluation, and Fei Sha, Vivian Yang, Anudhyan Boral, Leonardo Zepeda-Núñez, and Avram Hershko for suggestions and discussions. We are thankful to Michael Riley and Corinna Cortes for supporting and encouraging this project.


































.gif)
.gif)


