Spatial audio adds to your sense of presence when you’re in VR or AR, making it feel and sound, like you’re surrounded by a virtual or augmented world. And regardless of the display hardware you’re using, spatial audio makes it possible to hear sounds coming from all around you.
Resonance Audio, our spatial audio SDK
launched last year, enables developers to create more realistic VR and AR experiences on mobile and desktop. We’ve seen a number of exciting experiences emerge across a variety of platforms using our SDK. Recent examples include apps like
Pixar’s Coco VR for Gear VR, Disney’s
Star Wars™: Jedi Challenges AR app for Android and iOS, and
Runaway’s Flutter VR for Daydream, which all used Resonance Audio technology.
To accelerate adoption of immersive audio technology and strengthen the developer community around it, we’re opening Resonance Audio to a community-driven development model. By creating an open source spatial audio project optimized for mobile and desktop computing, any platform or software development tool provider can easily integrate with Resonance Audio. More cross-platform and tooling support means more distribution opportunities for content creators, without the worry of investing in costly porting projects.
What’s Included in the Open Source Project
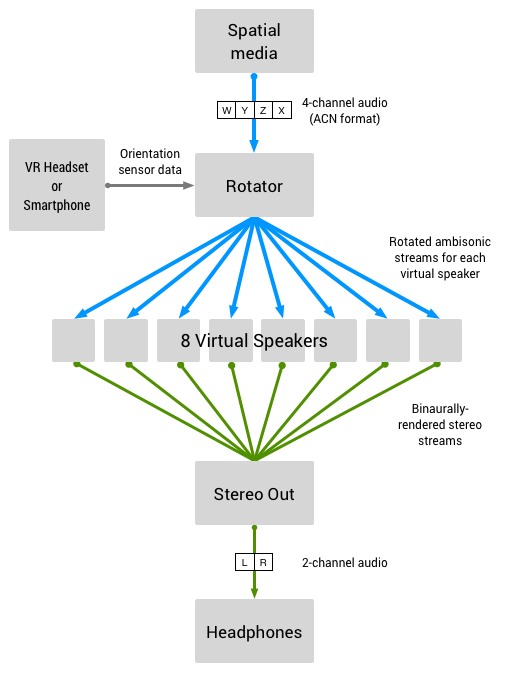
As part of our open source project, we’re providing a reference implementation of YouTube’s Ambisonic-based spatial audio decoder, compatible with the same Ambisonics format (Ambix ACN/SN3D) used by others in the industry. Using our reference implementation, developers can easily render Ambisonic content in their VR media and other applications, while benefiting from Ambisonics open source, royalty-free model. The project also includes encoding, sound field manipulation and decoding techniques, as well as head related transfer functions (HRTFs) that we’ve used to achieve rich spatial audio that scales across a wide spectrum of device types and platforms. Lastly, we’re making our entire library of highly optimized DSP classes and functions, open to all. This includes resamplers, convolvers, filters, delay lines and other DSP capabilities. Additionally, developers can now use Resonance Audio’s brand new Spectral Reverb, an efficient, high quality, constant complexity reverb effect, in their own projects.
We’ve open sourced Resonance Audio as a standalone library and associated engine plugins, VST plugin, tutorials, and examples with the Apache 2.0 license. This means Resonance Audio is yours, so you’re free to use Resonance Audio in your projects, no matter where you work. And if you see something you’d like to improve, submit a GitHub pull request to be reviewed by the Resonance Audio project committers. While the engine plugins for Unity, Unreal, FMOD, and Wwise will remain open source, going forward they will be maintained by project committers from our partners, Unity, Epic, Firelight Technologies, and Audiokinetic, respectively.
If you’re interested in learning more about Resonance Audio, check out the documentation on our
developer site. If you want to get more involved, visit
our GitHub to access the source code, build the project, download the latest release, or even start contributing. We’re looking forward to building the future of immersive audio with all of you.
By Eric Mauskopf, Google AR/VR Team