An overview of how we're expanding code assistance features to all Colab users.
An overview of how we're expanding code assistance features to all Colab users.
Democratizing access to AI-enabled coding with Colab
An overview of how we're expanding code assistance features to all Colab users.
An overview of how we're expanding code assistance features to all Colab users.
Posted by Dave Burke, VP of Engineering

Last week we unveiled our most capable foundation model, Gemini. Gemini is multimodal – it can accept both text and image inputs. We introduced a way for Android developers to leverage our smallest model Gemini Nano, on-device. This is available on select devices through AICore, a system service that handles model management, runtimes, safety features and more, simplifying the work for developers. And today, we're introducing new ways for Android developers to access the Gemini Pro model – which runs off-device, in Google's data centers.
Gemini Pro is accessible via the Gemini API, and it’s our best model for scaling across a wide range of text and image reasoning tasks. To simplify integrating Gemini Pro, you can use the Google AI SDK, a client SDK for Android. This SDK enables direct integration from Android apps and removes the need for developers to build and manage their own backend infrastructure, reducing development costs and improving velocity.
Google AI Studio provides a streamlined way for developers to integrate the Gemini Pro model, craft prompts, create API keys, and effortlessly transform ideas into AI apps. Once you have developed your prompt in Google AI Studio, you can simply click on the “Get code” action to generate a Kotlin code snippet, and start integrating Gemini today using the Google AI SDK for Android.

We are also making it easier for developers to use the Gemini API directly in the latest preview version of Android Studio. We’re introducing a new project template for developers to get started with the Google AI SDK for Android right away. You’ll benefit from Android Studio’s enhanced code completion and lint checkers, helping with API keys and security.

To leverage the new template in Android Studio, start a new project through File > New > New Project and pick the Gemini API starter template. This template provides a pre-configured project with the necessary code to use the Gemini API. After choosing a project name and location, you will be prompted to generate an API key in Google AI Studio, and asked to enter it in Android Studio. Android Studio will automatically set up the project for you with the Gemini API connection, simplifying your workflow.
Alternatively, you can import the generative AI code sample and set it up in Android Studio through File > New > Import Sample, and searching for "Generative AI Sample".
Get started building AI-powered features and Android apps using Gemini Pro.

Last week, we announced Gemini, our largest and most capable AI model and the next step in our journey to make AI more helpful for everyone. It comes in three sizes: Ultra, Pro and Nano. We've already started rolling out Gemini in our products: Gemini Nano is in Android, starting with Pixel 8 Pro, and a specifically tuned version of Gemini Pro is in Bard.
Today, we’re making Gemini Pro available for developers and enterprises to build for your own use cases, and we’ll be further fine-tuning it in the weeks and months ahead as we listen and learn from your feedback.
The first version of Gemini Pro is now accessible via the Gemini API and here’s more about it:
- Gemini Pro outperforms other similarly-sized models on research benchmarks.
- Today’s version comes with a 32K context window for text, and future versions will have a larger context window.
- It’s free to use right now, within limits, and it will be competitively priced.
- It comes with a range of features: function calling, embeddings, semantic retrieval and custom knowledge grounding, and chat functionality.
- It supports 38 languages across 180+ countries and territories worldwide.
- In today’s release, Gemini Pro accepts text as input and generates text as output. We’ve also made a dedicated Gemini Pro Vision multimodal endpoint available today that accepts text and imagery as input, with text output.
- SDKs are available for Gemini Pro to help you build apps that run anywhere. Python, Android (Kotlin), Node.js, Swift and JavaScript are all supported.
 |
| Gemini Pro has SDKs that help you build apps that run anywhere. |
Google AI Studio is a free, web-based developer tool that enables you to quickly develop prompts and then get an API key to use in your app development. You can sign into Google AI Studio with your Google account and take advantage of the free quota, which allows 60 requests per minute — 20x more than other free offerings. When you’re ready, you can simply click on “Get code” to transfer your work to your IDE of choice, or use one of the quickstart templates available in Android Studio, Colab or Project IDX. To help us improve product quality, when you use the free quota, your API and Google AI Studio input and output may be accessible to trained reviewers. This data is de-identified from your Google account and API key.
 |
| Google AI Studio is a free, web-based developer tool that enables you to quickly develop prompts and then get an API key to use in your app development. |
When it's time for a fully-managed AI platform, you can easily transition from Google AI Studio to Vertex AI, which allows for customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.
With Vertex AI, you will have access to the same Gemini models, and will be able to:
- Tune and distill Gemini with your own company’s data, and augment it with grounding to include up-to-minute information and extensions to take real-world actions.
- Build Gemini-powered search and conversational agents in a low code / no code environment, including support for retrieval-augmented generation (RAG), blended search, embeddings, conversation playbooks and more.
- Deploy with confidence. We never train our models on inputs or outputs from Google Cloud customers. Your data and IP are always your data and IP.
To read more about our new Vertex AI capabilities, visit the Google Cloud blog.
Right now, developers have free access to Gemini Pro and Gemini Pro Vision through Google AI Studio, with up to 60 requests per minute, making it suitable for most app development needs. Vertex AI developers can try the same models, with the same rate limits, at no cost until general availability early next year, after which there will be a charge per 1,000 characters or per image across Google AI Studio and Vertex AI.
 |
| Big impact, small price: Because of our investments in TPUs, Gemini Pro can be served more efficiently. |
We’re excited that Gemini is now available to developers and enterprises. As we continue to fine-tune it, your feedback will help us improve. You can learn more and start building with Gemini on ai.google.dev, or use Vertex AI’s robust capabilities on your own data with enterprise-grade controls.
Early next year, we’ll launch Gemini Ultra, our largest and most capable model for highly complex tasks, after further fine-tuning, safety testing and gathering valuable feedback from partners. We’ll also bring Gemini to more of our developer platforms like Chrome and Firebase.
We’re excited to see what you build with Gemini.
 Launching Gemini Pro API and four more AI tools: Imagen 2, MedLM, and Duet AI for Developers and Duet AI in Security Operations.
Launching Gemini Pro API and four more AI tools: Imagen 2, MedLM, and Duet AI for Developers and Duet AI in Security Operations.
 Gemini Pro is now available for developers and enterprises to build AI applications.
Gemini Pro is now available for developers and enterprises to build AI applications.
 Now available in the U.S., NotebookLM has new features to help you easily read, take notes and organize your writing projects.
Now available in the U.S., NotebookLM has new features to help you easily read, take notes and organize your writing projects.

Artificial intelligence (AI) stands at the forefront of transformative technologies, reshaping industries and redefining the way we live and work. Yet, a closer look at the AI startup ecosystem reveals a stark gender disparity. Women, despite their profound capabilities and innovative prowess, often find themselves navigating a maze of obstacles in their entrepreneurial journey. Despite investment in AI software is booming globally, the venture capital funding problem for women is even more marked. Women-founded startups accounted for only 2.1% of VC deals involving AI startups1. This is a reality that demands attention and action. Globally in 2023, all-women founding teams raised just 3% of all dollars invested in the year, with mixed gender founding teams taking 15%, leaving 82% of dollars to flow to founding teams that are all men2.
Google's accelerator programs have actively taken a leading role in championing diversity and empowering women and minority founders - having supported 1100+ startups across the globe since 2016, 36% of which are women-led startups. As such, we are pleased to announce the launch of the Google for Startups Accelerator: Women Founders program (Europe & Israel), a 12 week program for Seed to Series A AI startups based in Europe and Israel.
The Google for Startups Accelerator: Women Founders program (Europe & Israel) provides a comprehensive mix of mentorship, technical support, and workshops, establishing a robust foundation for participants. Beyond Google's expert guidance, the accelerator cultivates a collaborative network among women founders, propelling innovation within the tech startup space. By empowering women founders, the Google for Startups Accelerator: Women Founders program (Europe & Israel) proactively contributes to creating a more inclusive and equitable tech community.
Applications for the Google for Startups Accelerator: Women Founders Europe & Israel program are open until January 19th, 2024. You can learn more and apply here.
In a similar vein, in North America, two other Google for Startups Accelerator programs for underrepresented founders have opened applications for the fifth Women Founders and Black Founders programs. These 10 week equity- free programs are best suited for Seed to Series A, high potential revenue generative women-led and black-led startups with growing teams (5+ employees). Applications for both programs close on February 1st, 2024.
To further explore these opportunities and why you should apply - listen to what past participants of the North American Women Founder and Black Founder programs have to say here.
 Explore our collection to find out more about Gemini, the most capable and general model we’ve ever built.
Explore our collection to find out more about Gemini, the most capable and general model we’ve ever built.

Foundation Models learn from a diverse range of data sources to produce AI systems capable of adapting to a wide range of tasks, instead of being trained for a single narrow use case. Today, we announced Gemini, our most capable model yet. Gemini was designed for flexibility, so it can run on everything from data centers to mobile devices. It's been optimized for three different sizes: Ultra, Pro and Nano.
Gemini Nano, our most efficient model built for on-device tasks, runs directly on mobile silicon, opening support for a range of important use cases. Running on-device enables features where the data should not leave the device, such as suggesting replies to messages in an end-to-end encrypted messaging app. It also enables consistent experiences with deterministic latency, so features are always available even when there’s no network.
Gemini Nano is distilled down from the larger Gemini models and specifically optimized to run on mobile silicon accelerators. Gemini Nano enables powerful capabilities such as high quality text summarization, contextual smart replies, and advanced proofreading and grammar correction. For example, the enhanced language understanding of Gemini Nano enables the Pixel 8 Pro to concisely summarize content in the Recorder app, even when the phone’s network connection is offline.

Gemini Nano is starting to power Smart Reply in Gboard on Pixel 8 Pro, ready to be enabled in settings as a developer preview. Available now to try with WhatsApp and coming to more apps next year, the on-device AI model saves you time by suggesting high-quality responses with conversational awareness1.

Android AICore is a new system service in Android 14 that provides easy access to Gemini Nano. AICore handles model management, runtimes, safety features and more, simplifying the work for you to incorporate AI into your apps.
AICore is private by design, following the example of Android’s Private Compute Core with isolation from the network via open-source APIs, providing transparency and auditability. As part of our efforts to build and deploy AI responsibly, we also built dedicated safety features to make it safer and more inclusive for everyone.

AICore enables Low Rank Adaptation (LoRA) fine tuning with Gemini Nano. This powerful concept enables app developers to create small LoRA adapters based on their own training data. The LoRA adapter is loaded by AICore, resulting in a powerful large language model fine tuned for the app’s own use-cases.
AICore takes advantage of new ML hardware like the latest Google Tensor TPU and NPUs in flagship Qualcomm Technologies, Samsung S.LSI and MediaTek silicon. AICore and Gemini Nano are rolling out to Pixel 8 Pro, with more devices and silicon partners to be announced in the coming months.
We're excited to bring together state-of-the-art AI research with easy-to-use tools and APIs for Android developers to build with Gemini on-device. If you are interested in building apps using Gemini Nano and AICore, please sign up for our Early Access Program.
Let’s try an experiment. We’ll show this picture to our multimodal model Gemini and ask it to describe what it sees:
Ok, let’s try this one:
How about this one?
But wait … what if we asked Gemini to reason about all of these images together?
Nice. What else could we try? Let's see if Gemini can notice this pattern:
Neat, it spotted the pattern! But does Gemini really know how this game works? Let’s try asking:
Good advice, Gemini! Okay, for this last one, let’s put your multimodal reasoning capabilities to the test. Here’s your prompt:
This is a secret message. What does it say?

Can you figure it out? We have gotten Gemini to solve it, but we won’t spoil it by putting the answer in this post. 🙂
Everything we did just now is an example of “multimodal prompting.” We’re basically giving Gemini combinations of different modalities — image and text in this case — and having Gemini respond by predicting what might come next. Gemini’s ability to seamlessly combine these modes together enables new possibilities for what you can do.
In this post, we’ll explore some of the prompting approaches we used in our Hands on with Gemini demo video. We’ll soon be rolling out Gemini for people to try in Google AI Studio, our free, web-based developer tool where you’ll be able to try your own multimodal prompts with Gemini. We’re hoping this guide of starter prompts and ideas helps inspire you to start exploring your own ideas.
Logic and puzzles are fun way to test Gemini. Let’s try one that requires both left-to-right spatial reasoning and knowledge about our solar system:
Nice! Here’s another, inspired by pinewood derby challenges:
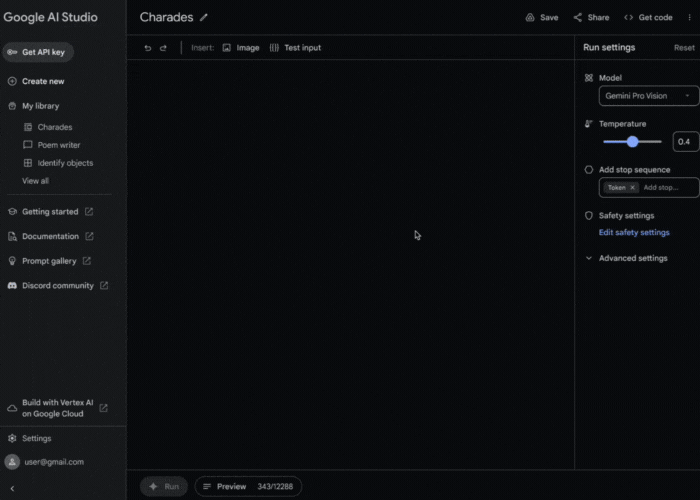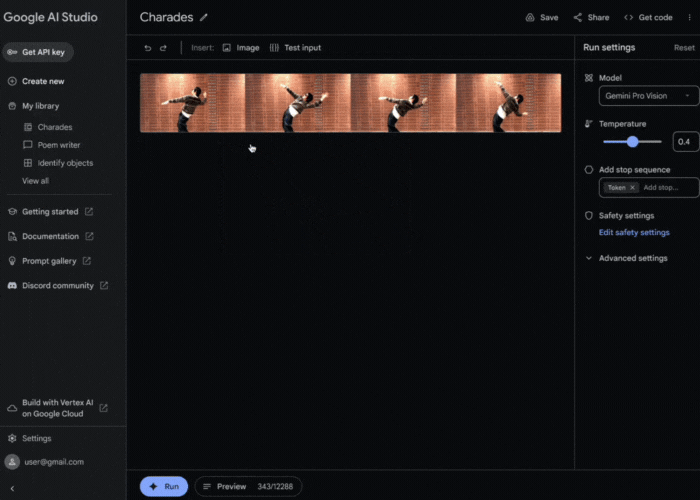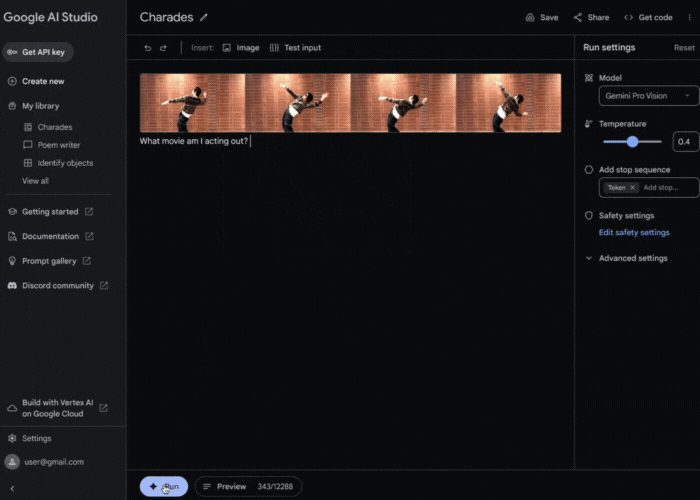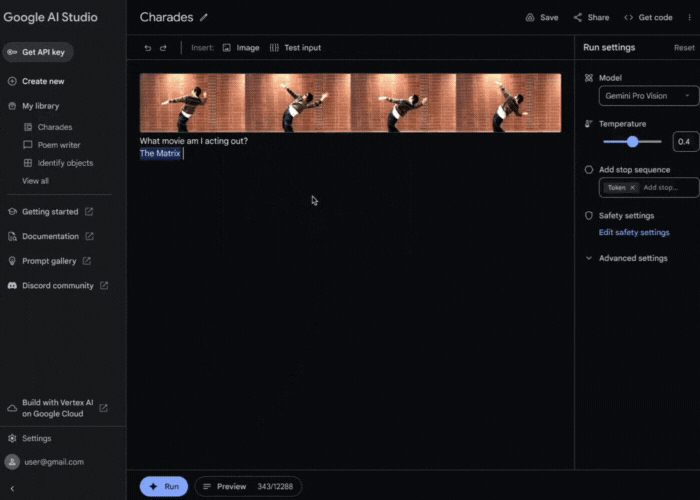
Next, what if we showed Gemini a sequence of images? Let’s see we can show a few still frames from a game of charades and have Gemini guess the movie:
Exploring image sequences really lets you dig into how Gemini reasons over time. Let’s try a classic magic trick.
Sure, that’s a logical answer given what it’s seen. But let’s pull a sleight of hand as we reveal this next image to Gemini...
Gemini notices it’s gone. But can it summarize what may have happened?
Gemini is leveraging the entire context of this conversation – both text and image – to summarize its answer. Finally, let’s ask:
Gemini makes a really solid guess! But we won’t reveal our secret 🙂.
Let’s try a trick that requires memory and logic: the classic ball and cup shuffling game. For this one, we’ll break it down into steps for Gemini. First, let’s establish the basics with these instructions:
Next, we’ll need to tell Gemini where we’re placing the ball:
Notice how we came up with a simple format for remembering where the ball is with “empty, empty, ball.” Next, let’s show Gemini two example turns:
In these two example turns, we’re both showing it what a swap looks like, and how to update the ball position. Now, let’s see if Gemini can generalize to a swap it hasn't seen:
Here's Gemini's response:
Gemini got it! It looked at these images and correctly inferred that cups 1 and 3 are being swapped. And it reasoned correctly about how to update the ball position. Let’s ask:
Not only did Gemini get the answer correctly, it accurately summarized the game history. Of course, it won’t always get this challenge right. Sometimes the fake out move (where you swap two empty cups) seems to trip it up, but sometimes it gets that too. But simple prompts like this make it really fun to rapidly test Gemini. You can change the variables in your prompt, including the order of swaps, and see how it does.
If you want to use Gemini in your own apps, you’ll want it to be able to connect to other tools. Let’s try a simple idea where Gemini needs to combine multimodality with tool use: drawing a picture to search for music.
Nice! Gemini both reasons about what it sees and then generates a search query you can parse to do a search. It’s like Gemini is acting like a translator for you – but instead of translating between languages, it’s translating modalities – from drawing to music in this case. With multimodal prompting, you can use Gemini to invent your own entirely new translations between different inputs and outputs.
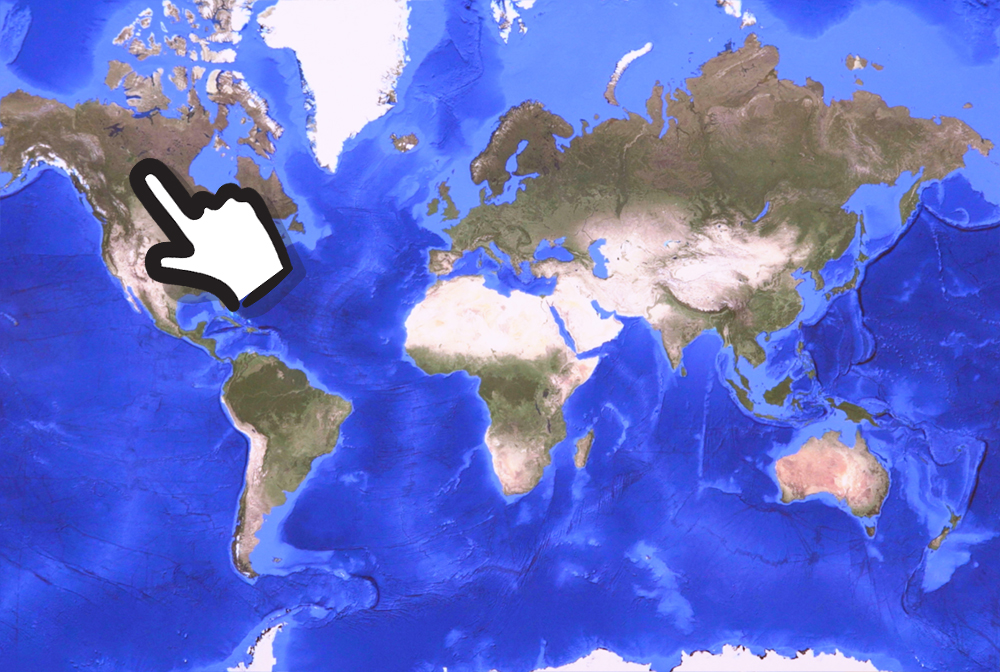
What if we tried using Gemini to quickly prototype a multimodal game? Here’s an idea: a geography guessing game where you have to point at a map to make your guess. Let’s start by prompting Gemini with the core idea:
Next, let’s give Gemini an example turn of gameplay, showing it how we want it to handle both incorrect and correct answers:
Let’s give it a go and prompt Gemini to generate a clue:
Ok, that’s a good clue. Let’s test out whether pointing will work. Just for fun, let’s try pointing at the wrong place first:
Great! Gemini looked at my image and figured out I’m pointing at Brazil, and correctly reasoned that’s wrong. Now let’s point at the right place on the map:
Nice! We’ve basically taught Gemini our game logic just by giving it an example. You'll also notice that it generalized from the illustrated hand in the examples.
Of course, to bring your game idea to life, you’ll eventually have to write some executable code. Let’s see if Gemini can make a simple countdown timer for a game, but with a few fun twists:
With just this single instruction, Gemini gives us a working timer that does what we asked for:

My favorite part is scrolling through Gemini’s source code to find the array of motivational emojis it picked for me:
const emojis = ['🚀', '⚡️', '🎉', '🎊', '🥳', '🤩', '✨'];
Throughout this post, we’ve been giving Gemini an input, and having Gemini make predictions for what might come next. That's basically what prompting is. And our inputs have been multimodal – image and text, combined.
But so far we've only shown Gemini responding in text. Maybe you’re wondering, can Gemini also respond with a combination of image and text? It can! This is a capability of Gemini called “interleaved text and image generation.” While this feature won’t be ready in the first version of Gemini for people to try, we hope to roll it out soon. Here’s a sneak peek of what’s possible.
Let’s see if we could use Gemini to provide everyday creative inspiration. And let’s try it in a domain that requires a bit of multimodal reasoning ... knitting! 🧶. Similar to our map game above, let's provide one example turn of interaction:
We’re essentially teaching Gemini about how we want each interaction to go: “I’ll take a photo of two balls of yarn, and I expect you (Gemini) to both come up with an idea for something I could make, and generate an image of it.”
Now, let’s show it a new pair of yarn colors it hasn't yet seen, and see if it can generalize:
Nice! Gemini correctly reasoned about the new colors (“I see blue and pink yarn”) and generated these ideas and the images in a single, interleaved output of text and image.
What Gemini did here is fundamentally different from today’s text-to-image models. It's not just passing an instruction to a separate text-to-image model. It sees the image of my actual yarn on my wooden table, truly doing multimodal reasoning about my text and image together.
We hope you found this a helpful starter guide to get a sense of what’s possible with Gemini. We’re very excited to roll it out to more people soon so you can explore your own ideas through prompting. Stay tuned!

 Posted by Jeanine Banks – VP/GM, Developer X and Developer Relations, and Burak Gokturk – VP/GM, Cloud AI and Industry Solutions
Posted by Jeanine Banks – VP/GM, Developer X and Developer Relations, and Burak Gokturk – VP/GM, Cloud AI and Industry Solutions
 Posted by Karina Govindji Senior Director – LEAD - Global Workforce Diversity, and Noa Havazelet – Head of Google's accelerator programs across Europe and Israel
Posted by Karina Govindji Senior Director – LEAD - Global Workforce Diversity, and Noa Havazelet – Head of Google's accelerator programs across Europe and Israel
 Posted by Dave Burke, VP of Engineering
Posted by Dave Burke, VP of Engineering
 Posted by
Posted by