Hi, everyone! We've just released Chrome 93 (93.0.4577.82) for Android: it'll become available on Google Play over the next few days.
This release includes stability and performance improvements. You can see a full list of the changes in the Git log. If you find a new issue, please let us know by filing a bug.Dev Channel Update for Chrome OS
The Dev channel is being updated to 95.0.4635.0 (Platform version: 14209.0.0) for most Chrome OS devices.
This build contains a number of features, bug fixes and security updates, please find release notes here.
If you find new issues, please let us know by visiting our forum or filing a bug. Interested in switching channels Find out how. You can submit feedback using ‘Report an issue...’ in the Chrome menu (3 vertical dots in the upper right corner of the browser).
Daniel Gagnon,
Google Chrome OS
Source: Google Chrome Releases
Chrome for iOS Update
Hi, everyone! We've just released Chrome 93 (93.0.4577.78) for iOS: it'll become available on App Store in the next few hours.
This release includes stability and performance improvements. You can see a full list of the changes in the Git log. If you find a new issue, please let us know by filing a bug.
Harry Souders
Source: Google Chrome Releases
Music Conditioned 3D Dance Generation with AIST++
Dancing is a universal language found in nearly all cultures, and is an outlet many people use to express themselves on contemporary media platforms today. The ability to dance by composing movement patterns that align to music beats is a fundamental aspect of human behavior. However, dancing is a form of art that requires practice. In fact, professional training is often required to equip a dancer with a rich repertoire of dance motions needed to create expressive choreography. While this process is difficult for people, it is even more challenging for a machine learning (ML) model, because the task requires the ability to generate a continuous motion with high kinematic complexity, while capturing the non-linear relationship between the movements and the accompanying music.
In “AI Choreographer: Music-Conditioned 3D Dance Generation with AIST++”, presented at ICCV 2021, we propose a full-attention cross-modal Transformer (FACT) model can mimic and understand dance motions, and can even enhance a person’s ability to choreograph dance. Together with the model, we released a large-scale, multi-modal 3D dance motion dataset, AIST++, which contains 5.2 hours of 3D dance motion in 1408 sequences, covering 10 dance genres, each including multi-view videos with known camera poses. Through extensive user studies on AIST++, we find that the FACT model outperforms recent state-of-the-art methods, both qualitatively and quantitatively.
 |  |
| We present a novel full-attention cross-modal transformer (FACT) network that can generate realistic 3D dance motion (right) conditioned on music and a new 3D dance dataset, AIST++ (left). |
We generate the proposed 3D motion dataset from the existing AIST Dance Database — a collection of videos of dance with musical accompaniment, but without any 3D information. AIST contains 10 dance genres: Old School (Break, Pop, Lock and Waack) and New School (Middle Hip-Hop, LA-style Hip-Hop, House, Krump, Street Jazz and Ballet Jazz). Although it contains multi-view videos of dancers, these cameras are not calibrated.
For our purposes, we recovered the camera calibration parameters and the 3D human motion in terms of parameters used by the widely used SMPL 3D model. The resulting database, AIST++, is a large-scale, 3D human dance motion dataset that contains a wide variety of 3D motion, paired with music. Each frame includes extensive annotations:
- 9 views of camera intrinsic and extrinsic parameters;
- 17 COCO-format human joint locations in both 2D and 3D;
- 24 SMPL pose parameters along with the global scaling and translation.
The motions are equally distributed among all 10 dance genres, covering a wide variety of music tempos in beat per minute (BPM). Each genre of dance contains 85% basic movements and 15% advanced movements (longer choreographies freely designed by the dancers).
The AIST++ dataset also contains multi-view synchronized image data, making it useful for other research directions, such as 2D/3D pose estimation. To our knowledge, AIST++ is the largest 3D human dance dataset with 1408 sequences, 30 subjects and 10 dance genres, and with both basic and advanced choreographies.
 |
| An example of a 3D dance sequence in the AIST++ dataset. Left: Three views of the dance video from the AIST database. Right: Reconstructed 3D motion visualized in 3D mesh (top) and skeletons (bottom). |
Because AIST is an instructional database, it records multiple dancers following the same choreography for different music with varying BPM, a common practice in dance. This posits a unique challenge in cross-modal sequence-to-sequence generation as the model needs to learn the one-to-many mapping between audio and motion. We carefully construct non-overlapping train and test subsets on AIST++ to ensure neither choreography nor music is shared across the subsets.
Full Attention Cross-Modal Transformer (FACT) Model
Using this data, we train the FACT model to generate 3D dance from music. The model begins by encoding seed motion and audio inputs using separate motion and audio transformers. The embeddings are then concatenated and sent to a cross-modal transformer, which learns the correspondence between both modalities and generates N future motion sequences. These sequences are then used to train the model in a self-supervised manner. All three transformers are jointly learned end-to-end. At test time, we apply this model in an autoregressive framework, where the predicted motion serves as the input to the next generation step. As a result, the FACT model is capable of generating long range dance motion frame-by-frame.
 |
| The FACT network takes in a music piece (Y) and a 2-second sequence of seed motion (X), then generates long-range future motions that correlate with the input music. |
FACT involves three key design choices that are critical for producing realistic 3D dance motion from music.
- All of the transformers use a full-attention mask, which can be more expressive than typical causal models because internal tokens have access to all inputs.
- We train the model to predict N futures beyond the current input, instead of just the next motion. This encourages the network to pay more attention to the temporal context, and helps prevent the model from motion freezing or diverging after a few generation steps.
- We fuse the two embeddings (motion and audio) early and employ a deep 12-layer cross-modal transformer module, which is essential for training a model that actually pays attention to the input music.
Results
We evaluate the performance based on three metrics:
Motion Quality: We calculate the Frechet Inception Distance (FID) between the real dance motion sequences in the AIST++ test set and 40 model generated motion sequences, each with 1200 frames (20 secs). We denote the FID based on the geometric and kinetic features as FIDg and FIDk, respectively.
Generation Diversity: Similar to prior work, to evaluate the model’s ability to generate divers dance motions, we calculate the average Euclidean distance in the feature space across 40 generated motions on the AIST++ test set, again comparing geometric feature space (Distg) and in the kinetic feature space (Distk).
 |
| Four different dance choreographies (right) generated using different music, but the same two second seed motion (left). The genres of the conditioning music are: Break, Ballet Jazz, Krump and Middle Hip-hop. The seed motion comes from hip-hop dance. |
Motion-Music Correlation: Because there is no well-designed metric to measure the correlation between input music (music beats) and generated 3D motion (kinematic beats), we propose a novel metric, called Beat Alignment Score (BeatAlign).
 |
| Kinetic velocity (blue curve) and kinematic beats (green dotted line) of the generated dance motion, as well as the music beats (orange dotted line). The kinematic beats are extracted by finding local minima from the kinetic velocity curve. |
Quantitative Evaluation
We compare the performance of FACT on each of these metrics to that of other state-of-the-art methods.
 |
| Compared to three recent state-of-the-art methods (Li et al., Dancenet, and Dance Revolution), the FACT model generates motions that are more realistic, better correlated with input music, and more diversified when conditioned on different music. *Note that the Li et al. generated motions are discontinuous, making the average kinetic feature distance abnormally high. |
We also perceptually evaluate the motion-music correlation with a user study in which each participant is asked to watch 10 videos showing one of our results and one random counterpart, and then select which dancer is more in sync with the music. The study consisted of 30 participants, ranging from professional dancers to people who rarely dance. Compared to each baseline, 81% prefered the FACT model output to that of Li et al., 71% prefered FACT to Dancenet, and 77% prefered it Dance Revolution. Interestingly, 75% of participants preferred the unpaired AIST++ dance motion to that generated by FACT, which is unsurprising since the original dance captures are highly expressive.
Qualitative Results
Compared with prior methods like DanceNet (left) and Li et. al. (middle), 3D dance generated using the FACT model (right) is more realistic and better correlated with input music.

More generated 3D dances using the FACT model.
 |  |
 |  |
Conclusion and Discussion
We present a model that can not only learn the audio-motion correspondence, but also can generate high quality 3D motion sequences conditioned on music. Because generating 3D movement from music is a nascent area of study, we hope our work will pave the way for future cross-modal audio to 3D motion generation. We are also releasing AIST++, the largest 3D human dance dataset to date. This proposed, multi-view, multi-genre, cross-modal 3D motion dataset can not only help research in the conditional 3D motion generation research but also human understanding research in general. We are releasing the code in our GitHub repository and the trained model here.
While our results show a promising direction in this problem of music conditioned 3D motion generation, there are more to be explored. First, our approach is kinematic-based and we do not reason about physical interactions between the dancer and the floor. Therefore the global translation can lead to artifacts, such as foot sliding and floating. Second, our model is currently deterministic. Exploring how to generate multiple realistic dances per music is an exciting direction.
Acknowledgements
We gratefully acknowledge the contribution of other co-authors, including Ruilong Li and David Ross. We thank Chen Sun, Austin Myers, Bryan Seybold and Abhijit Kundu for helpful discussions. We thank Emre Aksan and Jiaman Li for sharing their code. We also thank Kevin Murphy for the early attempts in this direction, as well as Peggy Chi and Pan Chen for the help on user study experiments.

Source: Google AI Blog
Drone control via gestures using MediaPipe Hands
A guest post by Neurons Lab
Please note that the information, uses, and applications expressed in the below post are solely those of our guest author, Neurons Lab, and not necessarily those of Google.
How the idea emerged
With the advancement of technology, drones have become not only smaller, but also have more compute. There are many examples of iPhone-sized quadcopters in the consumer drone market and the computing power to do live tracking while recording 4K video. However, the most important element has not changed much - the controller. It is still bulky and not intuitive for beginners to use. There is a smartphone with on-display control as an option; however, the control principle is still the same.
That is how the idea for this project emerged: a more personalised approach to control the drone using gestures. ML Engineer Nikita Kiselov (me) together with consultation from my colleagues at Neurons Lab undertook this project.
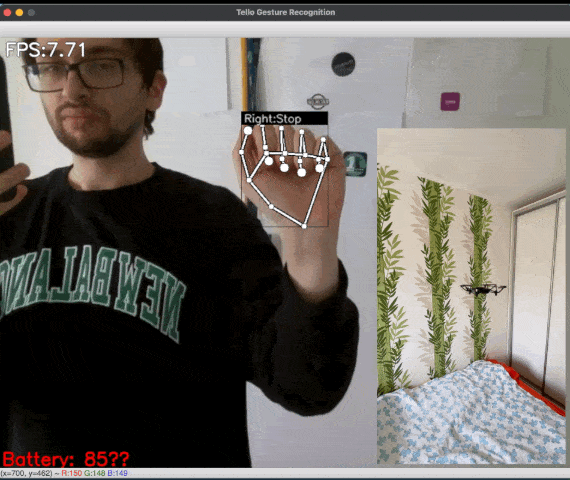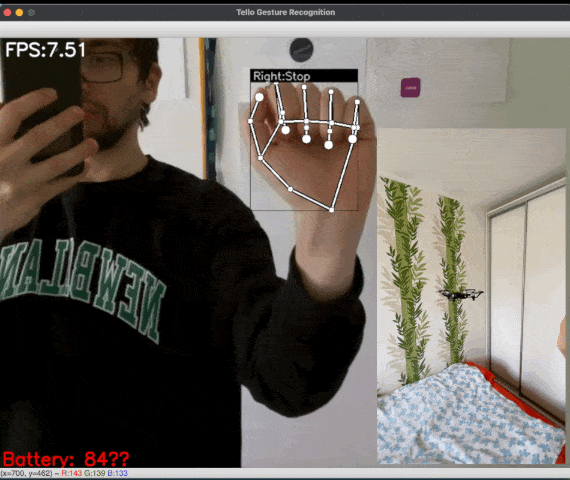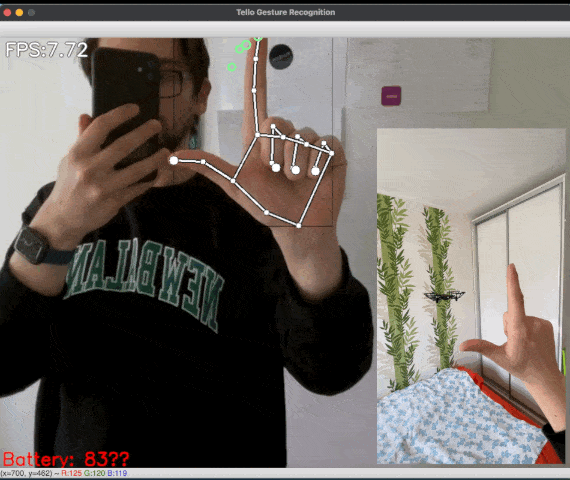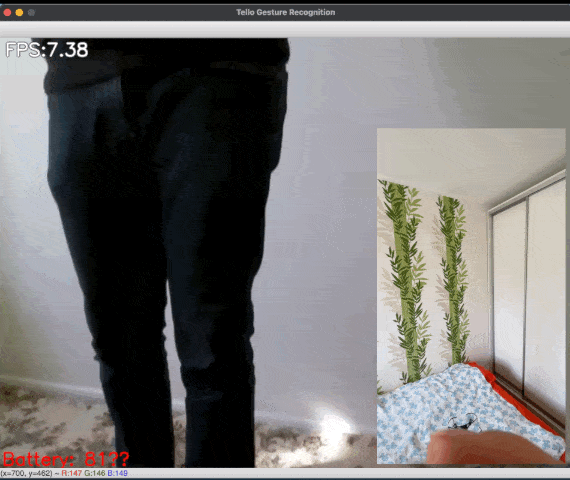
Figure 1: [GIF] Demonstration of drone flight control via gestures using MediaPipe Hands
Why use gesture recognition?
Gestures are the most natural way for people to express information in a non-verbal way. Gesture control is an entire topic in computer science that aims to interpret human gestures using algorithms. Users can simply control devices or interact without physically touching them. Nowadays, such types of control can be found from smart TV to surgery robots, and UAVs are not the exception.
Although gesture control for drones have not been widely explored lately, the approach has some advantages:
- No additional equipment needed.
- More human-friendly controls.
- All you need is a camera that is already on all drones.
With all these features, such a control method has many applications.
Flying action camera. In extreme sports, drones are a trendy video recording tool. However, they tend to have a very cumbersome control panel. The ability to use basic gestures to control the drone (while in action) without reaching for the remote control would make it easier to use the drone as a selfie camera. And the ability to customise gestures would completely cover all the necessary actions.
This type of control as an alternative would be helpful in an industrial environment like, for example, construction conditions when there may be several drone operators (gesture can be used as a stop-signal in case of losing primary source of control).
The Emergencies and Rescue Services could use this system for mini-drones indoors or in hard-to-reach places where one of the hands is busy. Together with the obstacle avoidance system, this would make the drone fully autonomous, but still manageable when needed without additional equipment.
Another area of application is FPV (first-person view) drones. Here the camera on the headset could be used instead of one on the drone to recognise gestures. Because hand movement can be impressively precise, this type of control, together with hand position in space, can simplify the FPV drone control principles for new users.
However, all these applications need a reliable and fast (really fast) recognition system. Existing gesture recognition systems can be fundamentally divided into two main categories: first - where special physical devices are used, such as smart gloves or other on-body sensors; second - visual recognition using various types of cameras. Most of those solutions need additional hardware or rely on classical computer vision techniques. Hence, that is the fast solution, but it's pretty hard to add custom gestures or even motion ones. The answer we found is MediaPipe Hands that was used for this project.
Overall project structure
To create the proof of concept for the stated idea, a Ryze Tello quadcopter was used as a UAV. This drone has an open Python SDK, which greatly simplified the development of the program. However, it also has technical limitations that do not allow it to run gesture recognition on the drone itself (yet). For this purpose a regular PC or Mac was used. The video stream from the drone and commands to the drone are transmitted via regular WiFi, so no additional equipment was needed.
To make the program structure as plain as possible and add the opportunity for easily adding gestures, the program architecture is modular, with a control module and a gesture recognition module.
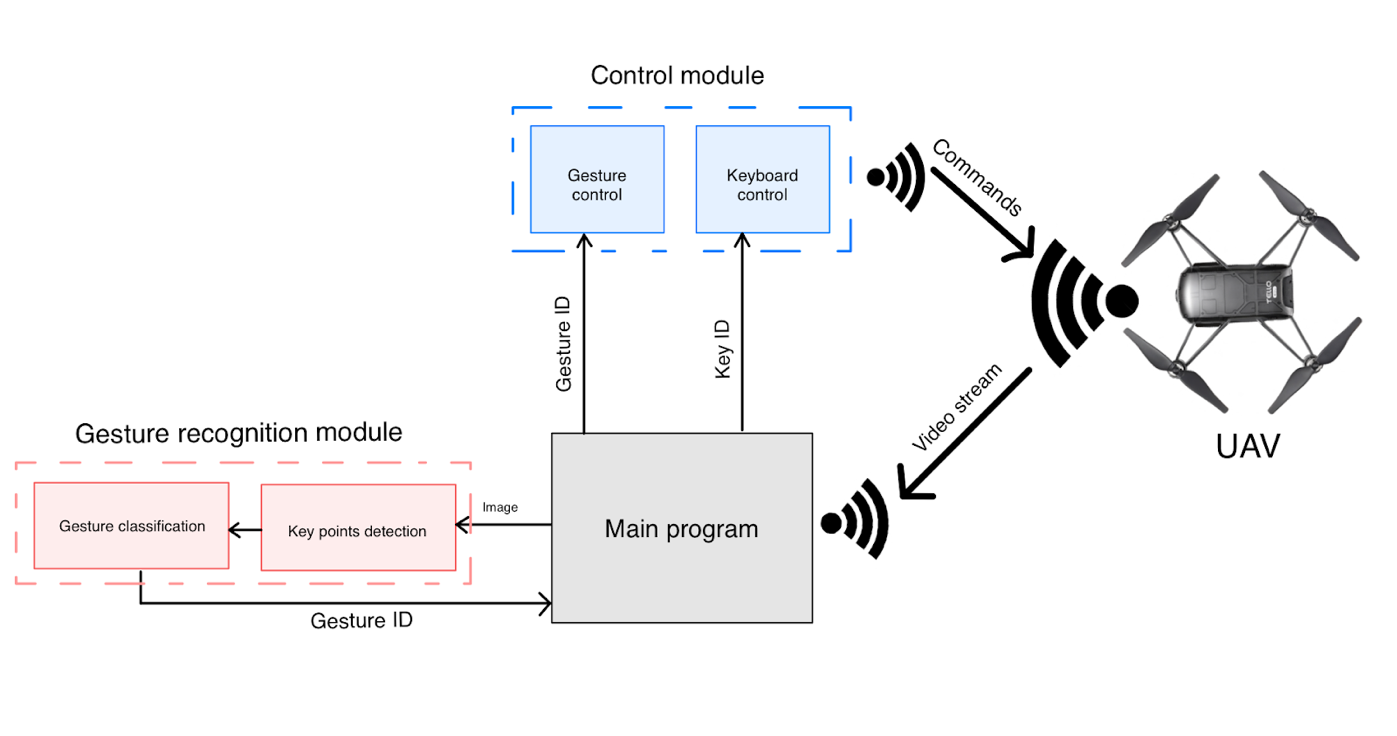
Figure 2: Scheme that shows overall project structure and how videostream data from the drone is processed
The application is divided into two main parts: gesture recognition and drone controller. Those are independent instances that can be easily modified. For example, to add new gestures or change the movement speed of the drone.
Video stream is passed to the main program, which is a simple script with module initialisation, connections, and typical for the hardware while-true cycle. Frame for the videostream is passed to the gesture recognition module. After getting the ID of the recognised gesture, it is passed to the control module, where the command is sent to the UAV. Alternatively, the user can control a drone from the keyboard in a more classical manner.
So, you can see that the gesture recognition module is divided into keypoint detection and gesture classifier. Exactly the bunch of the MediaPipe key point detector along with the custom gesture classification model distinguishes this gesture recognition system from most others.
Gesture recognition with MediaPipe
Utilizing MediaPipe Hands is a winning strategy not only in terms of speed, but also in flexibility. MediaPipe already has a simple gesture recognition calculator that can be inserted into the pipeline. However, we needed a more powerful solution with the ability to quickly change the structure and behaviour of the recognizer. To do so and classify gestures, the custom neural network was created with 4 Fully-Connected layers and 1 Softmax layer for classification.

Figure 3: Scheme that shows the structure of classification neural network
This simple structure gets a vector of 2D coordinates as an input and gives the ID of the classified gesture.
Instead of using cumbersome segmentation models with a more algorithmic recognition process, a simple neural network can easily handle such tasks. Recognising gestures by keypoints, which is a simple vector with 21 points` coordinates, takes much less data and time. What is more critical, new gestures can be easily added because model retraining tasks take much less time than the algorithmic approach.
To train the classification model, dataset with keypoints` normalised coordinates and ID of a gesture was used. The numerical characteristic of the dataset was that:
- 3 gestures with 300+ examples (basic gestures)
- 5 gestures with 40 -150 examples
All data is a vector of x, y coordinates that contain small tilt and different shapes of hand during data collection.
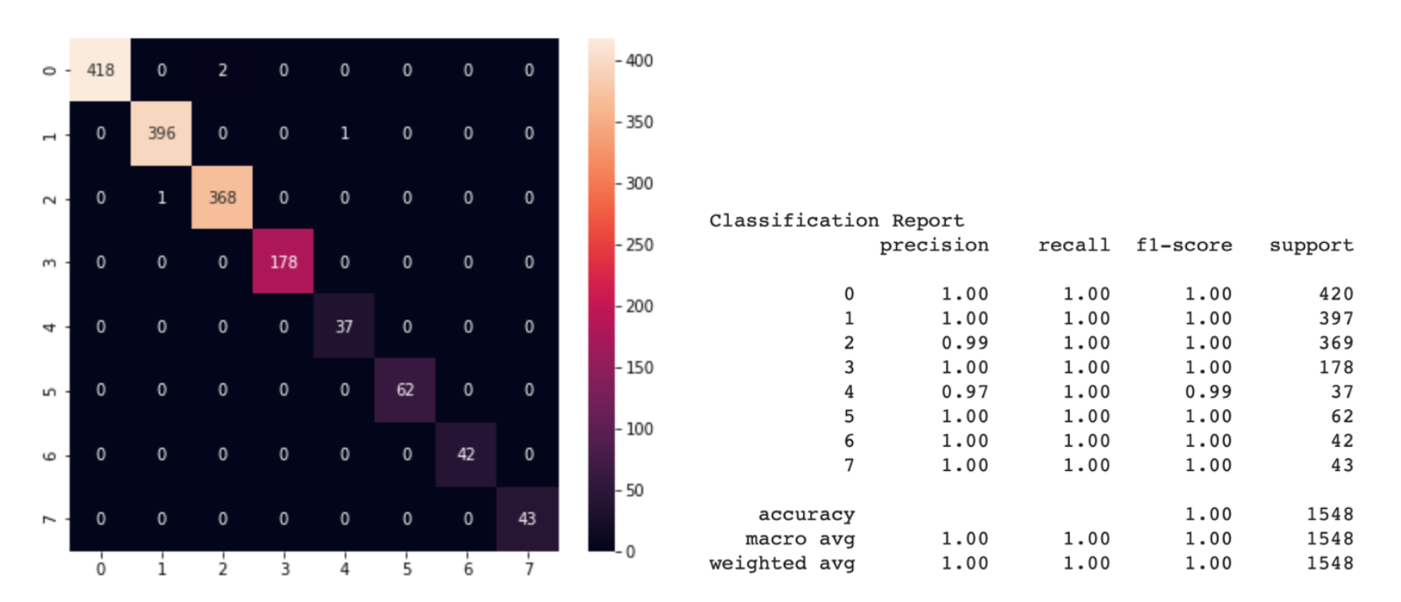
Figure 4: Confusion matrix and classification report for classification
We can see from the classification report that the precision of the model on the test dataset (this is 30% of all data) demonstrated almost error-free for most classes, precision > 97% for any class. Due to the simple structure of the model, excellent accuracy can be obtained with a small number of examples for training each class. After conducting several experiments, it turned out that we just needed the dataset with less than 100 new examples for good recognition of new gestures. What is more important, we don’t need to retrain the model for each motion in different illumination because MediaPipe takes over all the detection work.
![Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector](https://1.bp.blogspot.com/-P79noq5JrSM/YTqBpNUHNJI/AAAAAAAAKwI/Xp1WqAMKAJckPIX1CPUDfGOVn8evY_djQCLcBGAsYHQ/s0/figure%2B5.gif)
Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector
From gestures to movements
To control a drone, each gesture should represent a command for a drone. Well, the most excellent part about Tello is that it has a ready-made Python API to help us do that without explicitly controlling motors hardware. We just need to set each gesture ID to a command.
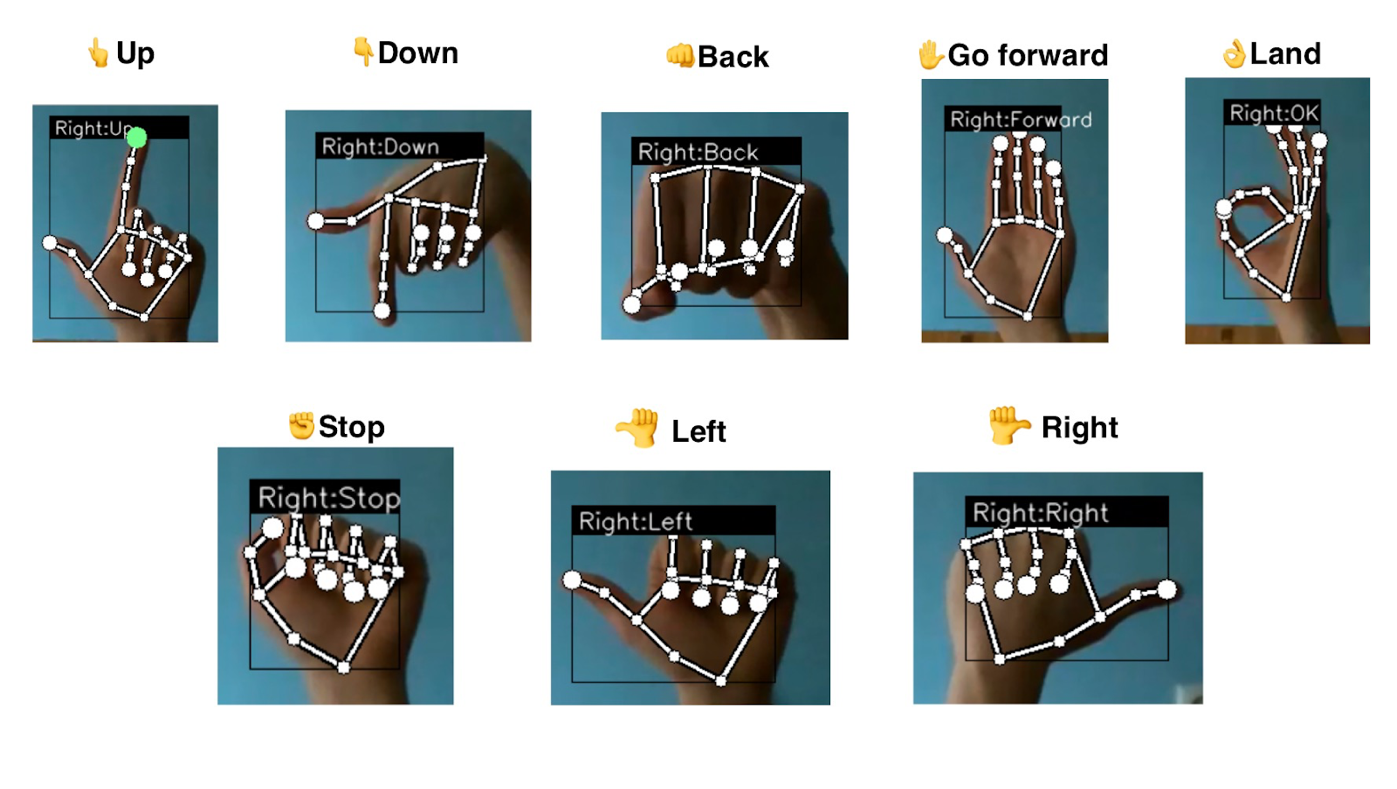
Figure 6: Command-gesture pairs representation
Each gesture sets the speed for one of the axes; that’s why the drone’s movement is smooth, without jitter. To remove unnecessary movements due to false detection, even with such a precise model, a special buffer was created, which is saving the last N gestures. This helps to remove glitches or inconsistent recognition.
The fundamental goal of this project is to demonstrate the superiority of the keypoint-based gesture recognition approach compared to classical methods. To demonstrate all the potential of this recognition model and its flexibility, there is an ability to create the dataset on the fly … on the drone`s flight! You can create your own combinations of gestures or rewrite an existing one without collecting massive datasets or manually setting a recognition algorithm. By pressing the button and ID key, the vector of detected points is instantly saved to the overall dataset. This new dataset can be used to retrain classification network to add new gestures for the detection. For now, there is a notebook that can be run on Google Colab or locally. Retraining the network-classifier takes about 1-2 minutes on a standard CPU instance. The new binary file of the model can be used instead of the old one. It is as simple as that. But for the future, there is a plan to do retraining right on the mobile device or even on the drone.
Figure 7: Notebook for model retraining in action
Summary
This project is created to make a push in the area of the gesture-controlled drones. The novelty of the approach lies in the ability to add new gestures or change old ones quickly. This is made possible thanks to MediaPipe Hands. It works incredibly fast, reliably, and ready out of the box, making gesture recognition very fast and flexible to changes. Our Neuron Lab`s team is excited about the demonstrated results and going to try other incredible solutions that MediaPipe provides.
We will also keep track of MediaPipe updates, especially about adding more flexibility in creating custom calculators for our own models and reducing barriers to entry when creating them. Since at the moment our classifier model is outside the graph, such improvements would make it possible to quickly implement a custom calculator with our model into reality.
Another highly anticipated feature is Flutter support (especially for iOS). In the original plans, the inference and visualisation were supposed to be on a smartphone with NPU\GPU utilisation, but at the moment support quality does not satisfy our requests. Flutter is a very powerful tool for rapid prototyping and concept checking. It allows us to throw and test an idea cross-platform without involving a dedicated mobile developer, so such support is highly demanded.
Nevertheless, the development of this demo project continues with available functionality, and there are already several plans for the future. Like using the MediaPipe Holistic for face recognition and subsequent authorisation. The drone will be able to authorise the operator and give permission for gesture control. It also opens the way to personalisation. Since the classifier network is straightforward, each user will be able to customise gestures for themselves (simply by using another version of the classifier model). Depending on the authorised user, one or another saved model will be applied. Also in the plans to add the usage of Z-axis. For example, tilt the palm of your hand to control the speed of movement or height more precisely. We encourage developers to innovate responsibly in this area, and to consider responsible AI practices such as testing for unfair biases and designing with safety and privacy in mind.
We highly believe that this project will motivate even small teams to do projects in the field of ML computer vision for the UAV, and MediaPipe will help to cope with the limitations and difficulties on their way (such as scalability, cross-platform support and GPU inference).
If you want to contribute, have ideas or comments about this project, please reach out to [email protected], or visit the GitHub page of the project.
This blog post is curated by Igor Kibalchich, ML Research Product Manager at Google AI.
Source: Google Developers Blog
Drone control via gestures using MediaPipe Hands
A guest post by Neurons Lab
Please note that the information, uses, and applications expressed in the below post are solely those of our guest author, Neurons Lab, and not necessarily those of Google.
How the idea emerged
With the advancement of technology, drones have become not only smaller, but also have more compute. There are many examples of iPhone-sized quadcopters in the consumer drone market and the computing power to do live tracking while recording 4K video. However, the most important element has not changed much - the controller. It is still bulky and not intuitive for beginners to use. There is a smartphone with on-display control as an option; however, the control principle is still the same.
That is how the idea for this project emerged: a more personalised approach to control the drone using gestures. ML Engineer Nikita Kiselov (me) together with consultation from my colleagues at Neurons Lab undertook this project.
Figure 1: [GIF] Demonstration of drone flight control via gestures using MediaPipe Hands
Why use gesture recognition?
Gestures are the most natural way for people to express information in a non-verbal way. Gesture control is an entire topic in computer science that aims to interpret human gestures using algorithms. Users can simply control devices or interact without physically touching them. Nowadays, such types of control can be found from smart TV to surgery robots, and UAVs are not the exception.
Although gesture control for drones have not been widely explored lately, the approach has some advantages:
- No additional equipment needed.
- More human-friendly controls.
- All you need is a camera that is already on all drones.
With all these features, such a control method has many applications.
Flying action camera. In extreme sports, drones are a trendy video recording tool. However, they tend to have a very cumbersome control panel. The ability to use basic gestures to control the drone (while in action) without reaching for the remote control would make it easier to use the drone as a selfie camera. And the ability to customise gestures would completely cover all the necessary actions.
This type of control as an alternative would be helpful in an industrial environment like, for example, construction conditions when there may be several drone operators (gesture can be used as a stop-signal in case of losing primary source of control).
The Emergencies and Rescue Services could use this system for mini-drones indoors or in hard-to-reach places where one of the hands is busy. Together with the obstacle avoidance system, this would make the drone fully autonomous, but still manageable when needed without additional equipment.
Another area of application is FPV (first-person view) drones. Here the camera on the headset could be used instead of one on the drone to recognise gestures. Because hand movement can be impressively precise, this type of control, together with hand position in space, can simplify the FPV drone control principles for new users.
However, all these applications need a reliable and fast (really fast) recognition system. Existing gesture recognition systems can be fundamentally divided into two main categories: first - where special physical devices are used, such as smart gloves or other on-body sensors; second - visual recognition using various types of cameras. Most of those solutions need additional hardware or rely on classical computer vision techniques. Hence, that is the fast solution, but it's pretty hard to add custom gestures or even motion ones. The answer we found is MediaPipe Hands that was used for this project.
Overall project structure
To create the proof of concept for the stated idea, a Ryze Tello quadcopter was used as a UAV. This drone has an open Python SDK, which greatly simplified the development of the program. However, it also has technical limitations that do not allow it to run gesture recognition on the drone itself (yet). For this purpose a regular PC or Mac was used. The video stream from the drone and commands to the drone are transmitted via regular WiFi, so no additional equipment was needed.
To make the program structure as plain as possible and add the opportunity for easily adding gestures, the program architecture is modular, with a control module and a gesture recognition module.
Figure 2: Scheme that shows overall project structure and how videostream data from the drone is processed
The application is divided into two main parts: gesture recognition and drone controller. Those are independent instances that can be easily modified. For example, to add new gestures or change the movement speed of the drone.
Video stream is passed to the main program, which is a simple script with module initialisation, connections, and typical for the hardware while-true cycle. Frame for the videostream is passed to the gesture recognition module. After getting the ID of the recognised gesture, it is passed to the control module, where the command is sent to the UAV. Alternatively, the user can control a drone from the keyboard in a more classical manner.
So, you can see that the gesture recognition module is divided into keypoint detection and gesture classifier. Exactly the bunch of the MediaPipe key point detector along with the custom gesture classification model distinguishes this gesture recognition system from most others.
Gesture recognition with MediaPipe
Utilizing MediaPipe Hands is a winning strategy not only in terms of speed, but also in flexibility. MediaPipe already has a simple gesture recognition calculator that can be inserted into the pipeline. However, we needed a more powerful solution with the ability to quickly change the structure and behaviour of the recognizer. To do so and classify gestures, the custom neural network was created with 4 Fully-Connected layers and 1 Softmax layer for classification.
Figure 3: Scheme that shows the structure of classification neural network
This simple structure gets a vector of 2D coordinates as an input and gives the ID of the classified gesture.
Instead of using cumbersome segmentation models with a more algorithmic recognition process, a simple neural network can easily handle such tasks. Recognising gestures by keypoints, which is a simple vector with 21 points` coordinates, takes much less data and time. What is more critical, new gestures can be easily added because model retraining tasks take much less time than the algorithmic approach.
To train the classification model, dataset with keypoints` normalised coordinates and ID of a gesture was used. The numerical characteristic of the dataset was that:
- 3 gestures with 300+ examples (basic gestures)
- 5 gestures with 40 -150 examples
All data is a vector of x, y coordinates that contain small tilt and different shapes of hand during data collection.
Figure 4: Confusion matrix and classification report for classification
We can see from the classification report that the precision of the model on the test dataset (this is 30% of all data) demonstrated almost error-free for most classes, precision > 97% for any class. Due to the simple structure of the model, excellent accuracy can be obtained with a small number of examples for training each class. After conducting several experiments, it turned out that we just needed the dataset with less than 100 new examples for good recognition of new gestures. What is more important, we don’t need to retrain the model for each motion in different illumination because MediaPipe takes over all the detection work.
Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector
From gestures to movements
To control a drone, each gesture should represent a command for a drone. Well, the most excellent part about Tello is that it has a ready-made Python API to help us do that without explicitly controlling motors hardware. We just need to set each gesture ID to a command.
Figure 6: Command-gesture pairs representation
Each gesture sets the speed for one of the axes; that’s why the drone’s movement is smooth, without jitter. To remove unnecessary movements due to false detection, even with such a precise model, a special buffer was created, which is saving the last N gestures. This helps to remove glitches or inconsistent recognition.
The fundamental goal of this project is to demonstrate the superiority of the keypoint-based gesture recognition approach compared to classical methods. To demonstrate all the potential of this recognition model and its flexibility, there is an ability to create the dataset on the fly … on the drone`s flight! You can create your own combinations of gestures or rewrite an existing one without collecting massive datasets or manually setting a recognition algorithm. By pressing the button and ID key, the vector of detected points is instantly saved to the overall dataset. This new dataset can be used to retrain classification network to add new gestures for the detection. For now, there is a notebook that can be run on Google Colab or locally. Retraining the network-classifier takes about 1-2 minutes on a standard CPU instance. The new binary file of the model can be used instead of the old one. It is as simple as that. But for the future, there is a plan to do retraining right on the mobile device or even on the drone.
Figure 7: Notebook for model retraining in action
Summary
This project is created to make a push in the area of the gesture-controlled drones. The novelty of the approach lies in the ability to add new gestures or change old ones quickly. This is made possible thanks to MediaPipe Hands. It works incredibly fast, reliably, and ready out of the box, making gesture recognition very fast and flexible to changes. Our Neuron Lab`s team is excited about the demonstrated results and going to try other incredible solutions that MediaPipe provides.
We will also keep track of MediaPipe updates, especially about adding more flexibility in creating custom calculators for our own models and reducing barriers to entry when creating them. Since at the moment our classifier model is outside the graph, such improvements would make it possible to quickly implement a custom calculator with our model into reality.
Another highly anticipated feature is Flutter support (especially for iOS). In the original plans, the inference and visualisation were supposed to be on a smartphone with NPU\GPU utilisation, but at the moment support quality does not satisfy our requests. Flutter is a very powerful tool for rapid prototyping and concept checking. It allows us to throw and test an idea cross-platform without involving a dedicated mobile developer, so such support is highly demanded.
Nevertheless, the development of this demo project continues with available functionality, and there are already several plans for the future. Like using the MediaPipe Holistic for face recognition and subsequent authorisation. The drone will be able to authorise the operator and give permission for gesture control. It also opens the way to personalisation. Since the classifier network is straightforward, each user will be able to customise gestures for themselves (simply by using another version of the classifier model). Depending on the authorised user, one or another saved model will be applied. Also in the plans to add the usage of Z-axis. For example, tilt the palm of your hand to control the speed of movement or height more precisely. We encourage developers to innovate responsibly in this area, and to consider responsible AI practices such as testing for unfair biases and designing with safety and privacy in mind.
We highly believe that this project will motivate even small teams to do projects in the field of ML computer vision for the UAV, and MediaPipe will help to cope with the limitations and difficulties on their way (such as scalability, cross-platform support and GPU inference).
If you want to contribute, have ideas or comments about this project, please reach out to [email protected], or visit the GitHub page of the project.
This blog post is curated by Igor Kibalchich, ML Research Product Manager at Google AI.
Source: Google Developers Blog
Vow about that: It’s wedding season on Search
We tend to think about “proposal season” as timed to the winter holidays, or big days like New Year’s Eve and Valentine’s Day. The actual proposal peak, though? September. With the exception of 2020, every year for the last five years, search interest in marriage proposals has peaked every September in the U.S. Who knows whether it’s the smell of pumpkin spice lattes or the new school year, but for whatever reason, this is when Americans these days prefer to get down on one knee.
To celebrate all the new fiancés out there, we’re taking a look at some of the trending wedding-related searches of the past year.
Give me a ring
If you’re curious what people who are thinking about taking that next step are searching for, take a look at some of these proposal-related searches over the past year in the U.S.
Top questions on marriage proposals
How to propose to a girl?
What knee do you propose on?
How soon is too soon to propose?
Should I propose before or after dinner?
How to get your boyfriend to propose?

The most-searched engagement ring styles over the past year in the U.S.
Most-searched engagement ring stones
Diamond
Moissanite
Sapphire
Emerald
Opal
Most-searched celebrity engagement rings
Ariana Grande
Gwen Stefani
Patrick Mahomes
Jennifer Lopez
Beyoncé
Pre-marital party time
Of course, before anyone walks down the aisle, there are those other celebrations that have to happen. Here are some of the most popular queries regarding the pre-party parties over the past year in the U.S.
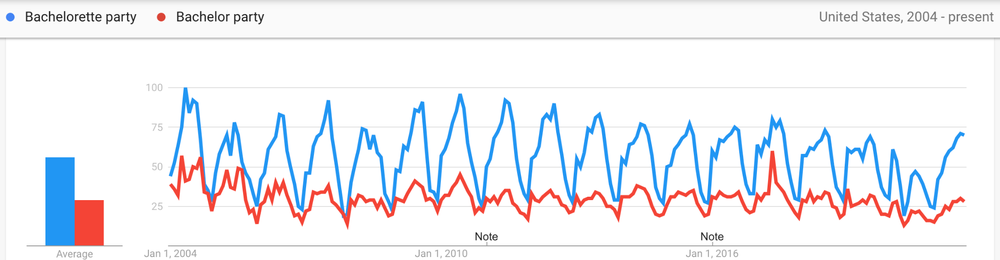
Bachelorette party (blue)is searched almost two times more than Bachelor party (red) in the U.S.
Top questions on bachelor parties
What is a bachelor party?
When do you have a bachelor party?
Where did bachelor parties originate?
What do guys wear for bachelor parties?
What do guys do for bachelor parties?
Top questions on bachelorette parties
How to plan a bachelorette party?
What is a bachelorette party?
Who plans the bachelorette party?
Who pays for the bachelorette party?
What to wear to a bachelorette party?
Dressed to impress
According to Google Trends data, the most-searched celebrity wedding in the U.S. is Kim Kardashian’s 2011 wedding to Kris Humphries. It's likely inspired a few ceremony trends since — and while we're on the subject, here are a few others: Sure, white wedding dresses are classic, but in August 2021, searches for "black wedding dress" reached a record high in the U.S. “Wedding jumpsuits” reached a new high this year in the U.S., too.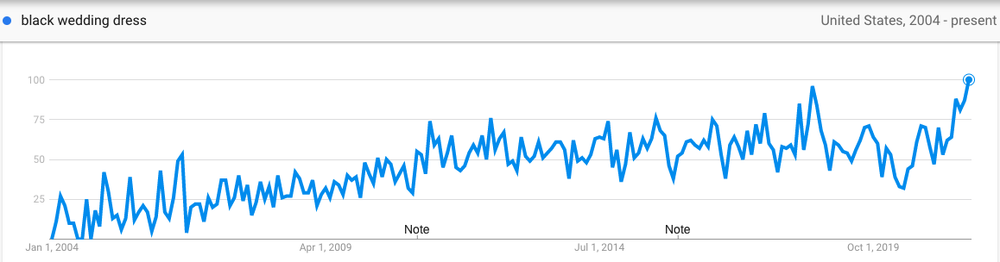
Here are a few other fun wedding Search trends we noticed over the past year in the U.S.
Most-searched types of wedding dresses
Boho wedding dress
Beach wedding dresses
Mermaid wedding dress
Simple wedding dress
Short wedding dress

The most-searched wedding suit colors over the past year in the U.S.
Most searched celebrity wedding dresses
Meghan Markle
Kate Middleton
Gwen Stefani
Ariana Grande
(Princess) Diana
Source: The Official Google Blog
New iOS Data Protection setting for Google Chat protects data sharing between Google Workspace and personal Google accounts
What’s changing
Earlier this year, we announced a new admin setting which restricts data and content sharing between Google Workspace accounts and personal Google accounts in Gmail, Drive, Docs, Sheets, and Slides on iOS. We’re now expanding this to include Google Chat. With data protection, users can only share or save content—such as files, emails, chat messages, or copied & pasted content—within Google Workspace accounts. This will protect users from sharing a Chat message with their personal Google accounts or saving data to their personal account.

Admins can turn off sharing from company to personal Chat accounts
Who’s impacted
Admins and end users
Why it’s important
Google applications on iOS support multi-user logins, allowing users to access Gmail, Google Drive, Docs, Sheets, Chat and Slides with their personal and Google Workspace accounts. Giving admins the ability to control how data is shared across user accounts helps minimize accidental data sharing. Together with the previously released copy and paste and drag and drop restrictions and protections against data sharing between Google Workspace and personal Google accounts, these measures expand data protection coverage and help increase the security of your corporate data on iOS.
Getting started
- Admins: Visit the Help Center to learn more about controlling whether users can copy work data to personal apps on iOS devices.
- End users: There is no end user setting for this feature. When enabled by your admin, you will be able to securely share enterprise Google Chat content.
Rollout pace
- Rapid Release and Scheduled Release domains: Gradual rollout (up to 15 days for feature visibility) starting on September 13, 2021
Availability
- Available to Google Workspace Enterprise Standard, Enterprise Plus, and Education Plus customers
- Not available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Frontline, and Nonprofits, as well as G Suite Basic and Business customers
Resources
- Google Help: Apply Settings For iOS Devices
- Google Workspace Updates Blog: New iOS Data Protection setting protects data sharing between Google Workspace and personal Google accounts
Roadmap
- This feature was listed as an upcoming release.
Source: Google Workspace Updates
New iOS Data Protection setting for Google Chat protects data sharing between Google Workspace and personal Google accounts
What’s changing
Earlier this year, we announced a new admin setting which restricts data and content sharing between Google Workspace accounts and personal Google accounts in Gmail, Drive, Docs, Sheets, and Slides on iOS. We’re now expanding this to include Google Chat. With data protection, users can only share or save content—such as files, emails, chat messages, or copied & pasted content—within Google Workspace accounts. This will protect users from sharing a Chat message with their personal Google accounts or saving data to their personal account.
Admins can turn off sharing from company to personal Chat accounts
Who’s impacted
Admins and end users
Why it’s important
Google applications on iOS support multi-user logins, allowing users to access Gmail, Google Drive, Docs, Sheets, Chat and Slides with their personal and Google Workspace accounts. Giving admins the ability to control how data is shared across user accounts helps minimize accidental data sharing. Together with the previously released copy and paste and drag and drop restrictions and protections against data sharing between Google Workspace and personal Google accounts, these measures expand data protection coverage and help increase the security of your corporate data on iOS.
Getting started
- Admins: Visit the Help Center to learn more about controlling whether users can copy work data to personal apps on iOS devices.
- End users: There is no end user setting for this feature. When enabled by your admin, you will be able to securely share enterprise Google Chat content.
Rollout pace
- Rapid Release and Scheduled Release domains: Gradual rollout (up to 15 days for feature visibility) starting on September 13, 2021
Availability
- Available to Google Workspace Enterprise Standard, Enterprise Plus, and Education Plus customers
- Not available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Frontline, and Nonprofits, as well as G Suite Basic and Business customers
Resources
- Google Help: Apply Settings For iOS Devices
- Google Workspace Updates Blog: New iOS Data Protection setting protects data sharing between Google Workspace and personal Google accounts
Roadmap
- This feature was listed as an upcoming release.
Source: Google Workspace Updates
Komal Singh wants kids to see themselves in her books
In 2018, Komal Singh published “Ara the Star Engineer,” a children’s book about a little girl who becomes interested in coding. Komal, an engineering program manager at Google, wanted to give girls an example of what they could be. Since then, she’s been exploring ways technology can make books more diverse for kids. “I set up my own team and I was pitching my ideas,” she says. “It was like setting up a little startup of my own. And while I was going through this process of building and pitching and scaling, I realized, whoa — we should write a book about this!”
Enter “Ara the Dream Innovator,” a new book published by PageTwo Books, illustrated by Ipek Konak and authored by Komal. The latest in the series finds Ara coming up with her own innovation, and trying to make sure it’s inclusive “FTW” (which stands for “for the world”). Of course, Komal had plenty of real-life experience to serve as inspiration.

Were you interested in tech at all when you were little?
I grew up in India in the ‘80s, and my father was an engineer. He would use everyday things to instill curiosity in us. If we were sitting under a fan he would ask, “How many rotations a minute do you think the fan is doing?” That’s what got me interested in the sciences. I really liked logic and coding, which is what eventually drew me to computer science.
Do you find yourself having similar conversations with your kids?
Yes! I have two kids, a 7-year-old daughter and a 3-year-old son, and I try to find opportunities to make them curious about science and the world around them.I’ll ask them “if you could fill your lunch box with atoms, how many would fit in there?” Or I’ll ask if they want to come up with an algorithm for getting ready for school.
What have you been working on since your first book?
Both books were inspired by my own experiences. So with the first book, it was something my daughter said — that she thought only men were engineers because that’s what she saw — that triggered it. After publishing the first book, I wanted to see how I could take storytelling to bigger heights with the help of technology, so I set up a 20 Percent Project, which is when Google invites employees to spend 20% of their working hours on passion-related assignments aligned with some of their work goals.
Our team used AI models to morph popular characters in media to look like underrepresented children, so these kids could see themselves represented in books. For instance, we found that AI models didn’t recognize photos of children with alopecia, because they hadn’t been trained on that dataset. We don’t want kids to be left behind and not see themselves reflected in children’s literature. This technology could better represent the whole spectrum of people, and hopefully one day it could be used to broaden characters in children’s movies and books.

Komal’s 20 percent team is using AI to make characters that all kids can see themselves in.
The process of taking ideas and turning them into reality inspired the second book. Not only what it’s like to build something from an idea, but also about making sure your innovations are inclusive and equitable.
What does Ara build?
She builds a “dream decoder,” which captures your dreams, because that’s when she has all her best ideas. She then founds a startup with her droid DeeDee to make sure the dream decoder works for all kinds of children around the world, like children who have disabilities or children from different ethnic backgrounds.
What does your daughter think of the new book?
She loves how Ara builds a team of her own and tries to make her team diverse — she likes that idea of having all sorts of people on a team. She’s fascinated by that.
Do we meet any new characters?
We meet some real-life women founders! A big focus is to diversify characters so young BIPOC readers can see themselves represented. And one cool thing is, and this was unintentional, one of them is Maayan Ziv, the founder of an accessibility focused tech startup — and she happens to be in the current Google for Startups class.There are also Ara’s friends, the Super Solvers, a really diverse group. It was enlightening creating our Indigenous Super Solver; we really wanted to get her right. Neither the illustrator or I are Indigenous, so I reached out to an Indigenous Googler, and she was so helpful. Looking at the first version, she was like “this looks like if a Westerner designed it.” And rightly so! That was such a check of our bias.
What’s the hardest part of writing a book?
The second book was easier because I had a path, but the expectations were much higher! But it was really my conviction that such books need to exist, that children need to have these books, that pushed me. I read somewhere that inspiration is a prerequisite to learning, and these books are not about teaching children to code or launch a startup — they’re about teaching them they can code, they can launch a company.
Do you know what’s next for Ara?
My new role in responsible AI for Media is influencing the next book: I want to explain AI to children and parents and families in a way they understand, and also the importance of tackling bias in AI so we can make sure AI systems are fair.