Research by NZ Tech shows that there is low representation of Māori and Pacific people across corporate Aotearoa, with these figures even lower in the technology sector. This presents two challenges. First, diversity in organisations is critical to broader business success. And second, we’ve seen that teams that offer different perspectives, experiences and insights develop technological solutions that support all communities.
Over the past decade, TupuToa has been nurturing and developing Māori and Pacific leaders to ensure corporate Aotearoa is representative of these communities. With over 1000 alumni placed in roles across Aotearoa and beyond, there’s also a need to support this cohort of professionals with the skills required to achieve their tech-career aspirations.
Now, through grant support provided by Google.org, Google’s philanthropic arm, TupuToa will commence a programme aimed at increasing representation of Māori and Pacific professionals in technology across Aotearoa to improve technological outcomes for all.
TupuToa Chief Executive Anne Fitisemanu said, ”The ripple effect of this programme will be massive. Not only will we be able to support our alumni but this work will impact their whanau and communities who are at risk of exclusion from this industry, and eventually improve the growth of Aotearoa’s technology related skill sets that are already needed across a broad range of industries. I’m so pleased that we’re aligned with Google.org on this shared mission to develop and empower our people through tech.”
The programme will support the TupuToa community of Māori and Pacific professionals in two ways. By seeking to understand the needs of alumni in the workforce and then by providing better support and pathways for Māori and Pacific early talent to develop their careers successfully in technology, with scope to expand to experienced career changers in the future.
With a shared commitment to ensuring indigenous communities take their place and thrive in the world of technology, we hope this programme will in time deliver better technological outcomes for all of New Zealand.
Post content Posted by Annie Lewin, Senior Director for Global Advocacy at Google.org.
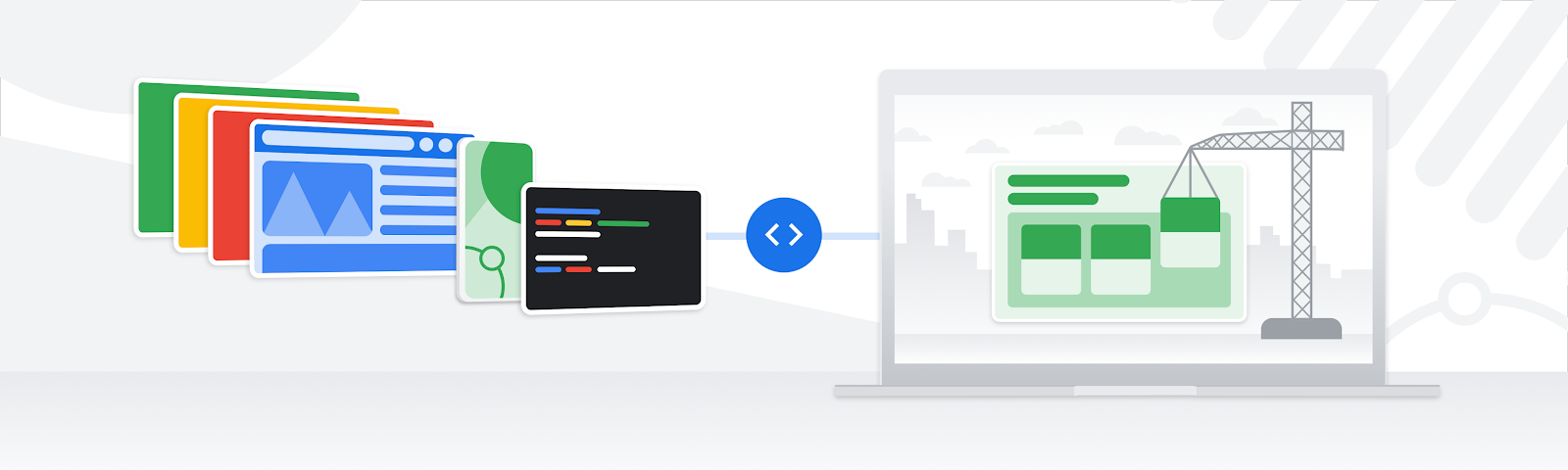
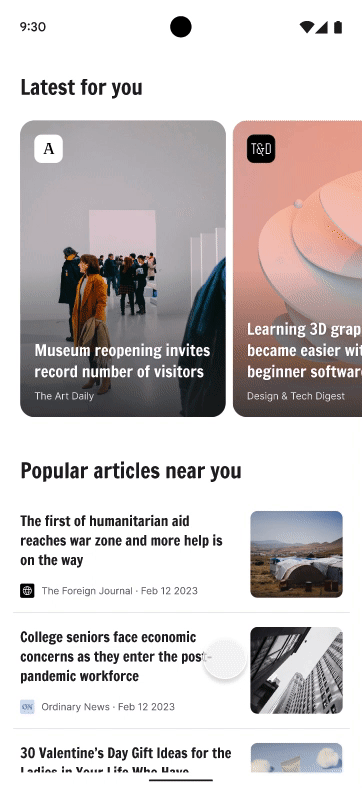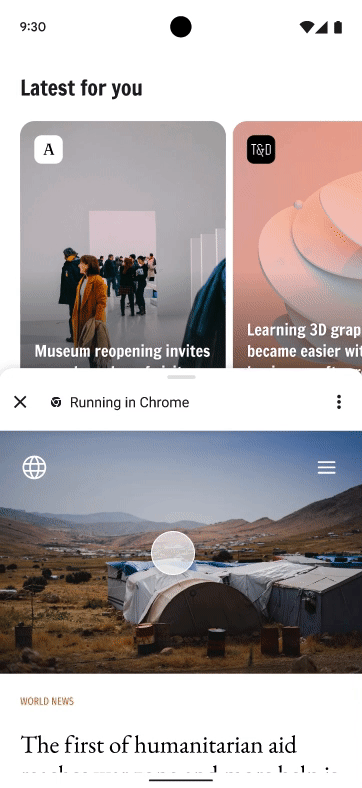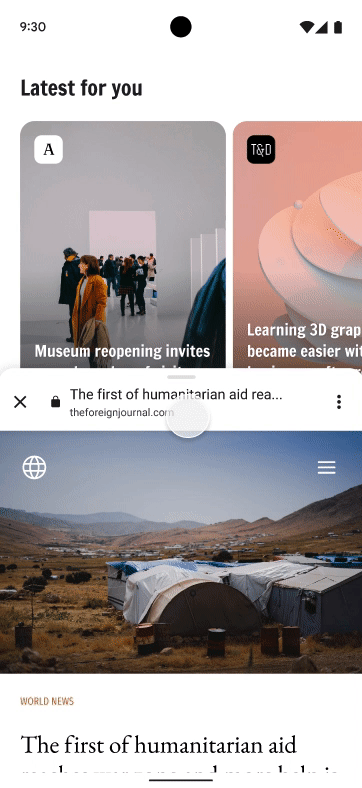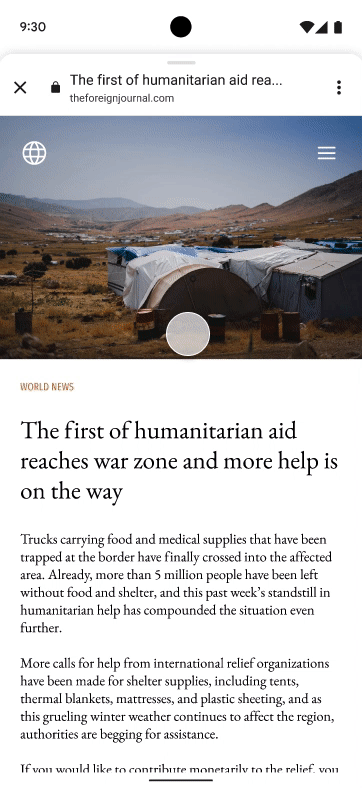
Posted by Victor Gallet, Product ManagerWhen adding a web experience to your Android app, simply launching a browser from your app forces users to leave your app, with the risk of abandonment for that session. WebViews allow you to build your own in-app browser, but can be a complex process with higher maintenance overhead. To help developers provide a better in-app web experience, Chrome launched Custom Tabs, which are now supported by most major browsers on Android.
Today, we’re announcing two new features that bring the best of Chrome to Android developers and users.
Multitasking between your app and the web
Developers can customize tab height with Partial Custom Tabs
To keep users engaged with your app, Chrome now gives you more control over tab height with Partial Custom Tabs. You can customize the tab in pixels for a partial overlay, allowing users to simultaneously interact with your native app and the web. Partial Custom Tabs are currently supported by a handful of browsers, including Chrome, and we look forward to additional browser support soon. If your users’ browser does not support Partial Custom Tabs, users will simply see the supported full-screen Custom Tab.
Giving users the best of Chrome
With Chrome Custom Tabs, you’ll give users a fast, safe, and seamless way to experience the web. Your users will know that when they open the web from your app, it will be “running in Chrome” so they can use their most loved Chrome features like saved passwords and autofill.
Developers can customize tab height with Partial Custom Tabs
Posted by Kendra Byrne, Senior Product Manager, and Jie Tan, Staff Research Scientist, Robotics at Google
(This is Part 6 in our series of posts covering different topical areas of research at Google. You can find other posts in the series here.)
Within our lifetimes, we will see robotic technologies that can help with everyday activities, enhancing human productivity and quality of life. Before robotics can be broadly useful in helping with practical day-to-day tasks in people-centered spaces — spaces designed for people, not machines — they need to be able to safely & competently provide assistance to people.
In 2022, we focused on challenges that come with enabling robots to be more helpful to people: 1) allowing robots and humans to communicate more efficiently and naturally; 2) enabling robots to understand and apply common sense knowledge in real-world situations; and 3) scaling the number of low-level skills robots need to effectively perform tasks in unstructured environments.
An undercurrent this past year has been the exploration of how large, generalist models, like PaLM, can work alongside other approaches to surface capabilities allowing robots to learn from a breadth of human knowledge and allowing people to engage with robots more naturally. As we do this, we’re transforming robot learning into a scalable data problem so that we can scale learning of generalized low-level skills, like manipulation. In this blog post, we’ll review key learnings and themes from our explorations in 2022.
Bringing the capabilities of LLMs to robotics
An incredible feature of large language models (LLMs) is their ability to encode descriptions and context into a format that’s understandable by both people and machines. When applied to robotics, LLMs let people task robots more easily — just by asking — with natural language. When combined with vision models and robotics learning approaches, LLMs give robots a way to understand the context of a person’s request and make decisions about what actions should be taken to complete it.
One of the underlying concepts is using LLMs to prompt other pretrained models for information that can build context about what is happening in a scene and make predictions about multimodal tasks. This is similar to the socratic method in teaching, where a teacher asks students questions to lead them through a rational thought process. In “Socratic Models”, we showed that this approach can achieve state-of-the-art performance in zero-shot image captioning and video-to-text retrieval tasks. It also enables new capabilities, like answering free-form questions about and predicting future activity from video, multimodal assistive dialogue, and as we’ll discuss next, robot perception and planning.
In “Towards Helpful Robots: Grounding Language in Robotic Affordances”, we partnered with Everyday Robots to ground the PaLM language model in a robotics affordance model to plan long horizon tasks. In previous machine-learned approaches, robots were limited to short, hard-coded commands, like “Pick up the sponge,” because they struggled with reasoning about the steps needed to complete a task — which is even harder when the task is given as an abstract goal like, “Can you help clean up this spill?”
With PaLM-SayCan, the robot acts as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task.
For this approach to work, one needs to have both an LLM that can predict the sequence of steps to complete long horizon tasks and an affordance model representing the skills a robot can actually do in a given situation. In “Extracting Skill-Centric State Abstractions from Value Functions”, we showed that the value function in reinforcement learning (RL) models can be used to build the affordance model — an abstract representation of the actions a robot can perform under different states. This lets us connect long-horizons of real-world tasks, like “tidy the living room”, to the short-horizon skills needed to complete the task, like correctly picking, placing, and arranging items.
Having both an LLM and an affordance model doesn’t mean that the robot will actually be able to complete the task successfully. However, with Inner Monologue, we closed the loop on LLM-based task planning with other sources of information, like human feedback or scene understanding, to detect when the robot fails to complete the task correctly. Using a robot from Everyday Robots, we show that LLMs can effectively replan if the current or previous plan steps failed, allowing the robot to recover from failures and complete complex tasks like "Put a coke in the top drawer," as shown in the video below.
With PaLM-SayCan, the robot acts as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task.
An emergent capability from closing the loop on LLM-based task planning that we saw with Inner Monologue is that the robot can react to changes in the high-level goal mid-task. For example, a person might tell the robot to change its behavior as it is happening, by offering quick corrections or redirecting the robot to another task. This behavior is especially useful to let people interactively control and customize robot tasks when robots are working near people.
While natural language makes it easier for people to specify and modify robot tasks, one of the challenges is being able to react in real time to the full vocabulary people can use to describe tasks that a robot is capable of doing. In “Talking to Robots in Real Time”, we demonstrated a large-scale imitation learning framework for producing real-time, open-vocabulary, language-conditionable robots. With one policy we were able to address over 87,000 unique instructions, with an estimated average success rate of 93.5%. As part of this project, we released Language-Table, the largest available language-annotated robot dataset, which we hope will drive further research focused on real-time language-controllable robots.
Examples of long horizon goals reached under real time human language guidance.
We’re also excited about the potential for LLMs to write code that can control robot actions. Code-writing approaches, like in “Robots That Write Their Own Code”, show promise in increasing the complexity of tasks robots can complete by autonomously generating new code that re-composes API calls, synthesizes new functions, and expresses feedback loops to assemble new behaviors at runtime.
Code as Policies uses code-writing language models to map natural language instructions to robot code to complete tasks. Generated code can call existing perception action APIs, third party libraries, or write new functions at runtime.
Turning robot learning into a scalable data problem
Large language and multimodal models help robots understand the context in which they’re operating, like what’s happening in a scene and what the robot is expected to do. But robots also need low-level physical skills to complete tasks in the physical world, like picking up and precisely placing objects.
While we often take these physical skills for granted, executing them hundreds of times every day without even thinking, they present significant challenges to robots. For example, to pick up an object, the robot needs to perceive and understand the environment, reason about the spatial relation and contact dynamics between its gripper and the object, actuate the high degrees-of-freedom arm precisely, and exert the right amount of force to stably grasp the object without breaking it. The difficulty of learning these low-level skills is known as Moravec's paradox: reasoning requires very little computation, but sensorimotor and perception skills require enormous computational resources.
Inspired by the recent success of LLMs, which shows that the generalization and performance of large Transformer-based models scale with the amount of data, we are taking a data-driven approach, turning the problem of learning low-level physical skills into a scalable data problem. With Robotics Transformer-1 (RT-1), we trained a robot manipulation policy on a large-scale, real-world robotics dataset of 130k episodes that cover 700+ tasks using a fleet of 13 robots from Everyday Robots and showed the same trend for robotics — increasing the scale and diversity of data improves the model ability to generalize to new tasks, environments, and objects.
Example PaLM-SayCan-RT1 executions of long-horizon tasks in real kitchens.
Behind both language models and many of our robotics learning approaches, like RT-1, are Transformers, which allow models to make sense of Internet-scale data. Unlike LLMs, robotics is challenged by multimodal representations of constantly changing environments and limited compute. In 2020, we introduced Performers as an approach to make Transformers more computationally efficient, which has implications for many applications beyond robotics. In Performer-MPC, we applied this to introduce a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). We show a >40% improvement on the robot reaching its goal and a >65% improvement on social metrics when navigating around humans in comparison to a standard MPC policy. Performer-MPC provides 8 ms latency for the 8.3M parameter model, making on-robot deployment of Transformers practical.
Navigation robot maneuvering through highly constrained spaces using: Regular MPC, Explicit Policy, and Performer-MPC.
In the last year, our team has shown that data-driven approaches are generally applicable on different robotic platforms in diverse environments to learn a wide range of tasks, including mobile manipulation, navigation, locomotion and table tennis. This shows us a clear path forward for learning low-level robot skills: scalable data collection. Unlike video and text data that is abundant on the Internet, robotic data is extremely scarce and hard to acquire. Finding approaches to collect and efficiently use rich datasets representative of real-world interactions is the key for our data-driven approaches.
Simulation is a fast, safe, and easily parallelizable option, but it is difficult to replicate the full environment, especially physics and human-robot interactions, in simulation. In i-Sim2Real, we showed an approach to address the sim-to-real gap and learn to play table tennis with a human opponent by bootstrapping from a simple model of human behavior and alternating between training in simulation and deploying in the real world. In each iteration, both the human behavior model and the policy are refined.
Learning to play table tennis with a human opponent.
While simulation helps, collecting data in the real world is essential for fine-tuning simulation policies or adapting existing policies in new environments. While learning, robots are prone to failure, which can cause damage to itself and surroundings — especially in the early stages of learning where they are exploring how to interact with the world. We need to collect training data safely, even while the robot is learning, and enable the robot to autonomously recover from failure. In “Learning Locomotion Skills Safely in the Real World”, we introduced a safe RL framework that switches between a “learner policy” optimized to perform the desired task and a “safe recovery policy” that prevents the robot from unsafe states. In “Legged Robots that Keep on Learning”, we trained a reset policy so the robot can recover from failures, like learning to stand up by itself after falling.
Automatic reset policies enable the robot to continue learning in a lifelong fashion without human supervision.
While robot data is scarce, videos of people performing different tasks are abundant. Of course, robots aren’t built like people — so the idea of robotic learning from people raises the problem of transferring learning across different embodiments. In “Robot See, Robot Do”, we developed Cross-Embodiment Inverse Reinforcement Learning to learn new tasks by watching people. Instead of trying to replicate the task exactly as a person would, we learn the high-level task objective, and summarize that knowledge in the form of a reward function. This type of demonstration learning could allow robots to learn skills by watching videos readily available on the internet.
We’re also progressing towards making our learning algorithms more data efficient so that we’re not relying only on scaling data collection. We improved the efficiency of RL approaches by incorporating prior information, including predictive information, adversarial motion priors, and guide policies. Further improvements are gained by utilizing a novel structured dynamical systems architecture and combining RL with trajectory optimization, supported by novel solvers. These types of prior information helped alleviate the exploration challenges, served as good regularizers, and significantly reduced the amount of data required. Furthermore, our team has invested heavily in more data-efficient imitation learning. We showed that a simple imitation learning approach, BC-Z, can enable zero-shot generalization to new tasks that were not seen during training. We also introduced an iterative imitation learning algorithm, GoalsEye, which combined Learning from Play and Goal-Conditioned Behavior Cloning for high-speed and high-precision table tennis games. On the theoretical front, we investigated dynamical-systems stability for characterizing the sample complexity of imitation learning, and the role of capturing failure-and-recovery within demonstration data to better condition offline learning from smaller datasets.
Closing
Advances in large models across the field of AI have spurred a leap in capabilities for robot learning. This past year, we’ve seen the sense of context and sequencing of events captured in LLMs help solve long-horizon planning for robotics and make robots easier for people to interact with and task. We’ve also seen a scalable path to learning robust and generalizable robot behaviors by applying a transformer model architecture to robot learning. We continue to open source data sets, like “Scanned Objects: A Dataset of 3D-Scanned Common Household Items”, and models, like RT-1, in the spirit of participating in the broader research community. We’re excited about building on these research themes in the coming year to enable helpful robots.
Acknowledgements
We would like to thank everyone who supported our research. This includes the entire Robotics at Google team, and collaborators from Everyday Robots and Google Research. We also want to thank our external collaborators, including UC Berkeley, Stanford, Gatech, University of Washington, MIT, CMU and U Penn.
5 Gig offers symmetrical upload and download speeds with a Wi-Fi 6 router (or you can easily use your own), up to two mesh extenders and professional installation, all for $125 a month. Installation also includes an upgraded 10 Gig Fiber Jack, which means your home will be prepared for even more internet when the time comes.
As our homes get “smarter” and every device is set up to stream, having access to higher speed, higher bandwidth internet becomes even more important. 5 Gig is designed to handle the demands of heavy internet users — for example, creative professionals, people working in the cloud or with large data, households with large shared internet demands. 5 Gig will make it easier to upload and download simultaneously, no matter the file size, and will make streaming a dream even with multiple devices.
5 Gig is a product you can fall in love with fast, and we’re just getting started. 5 Gig will roll out in other cities later this year (and 8 Gig is on the horizon too), so stay tuned!
Posted by Nick Saporito, Head of Multi-gig and Commercial Product
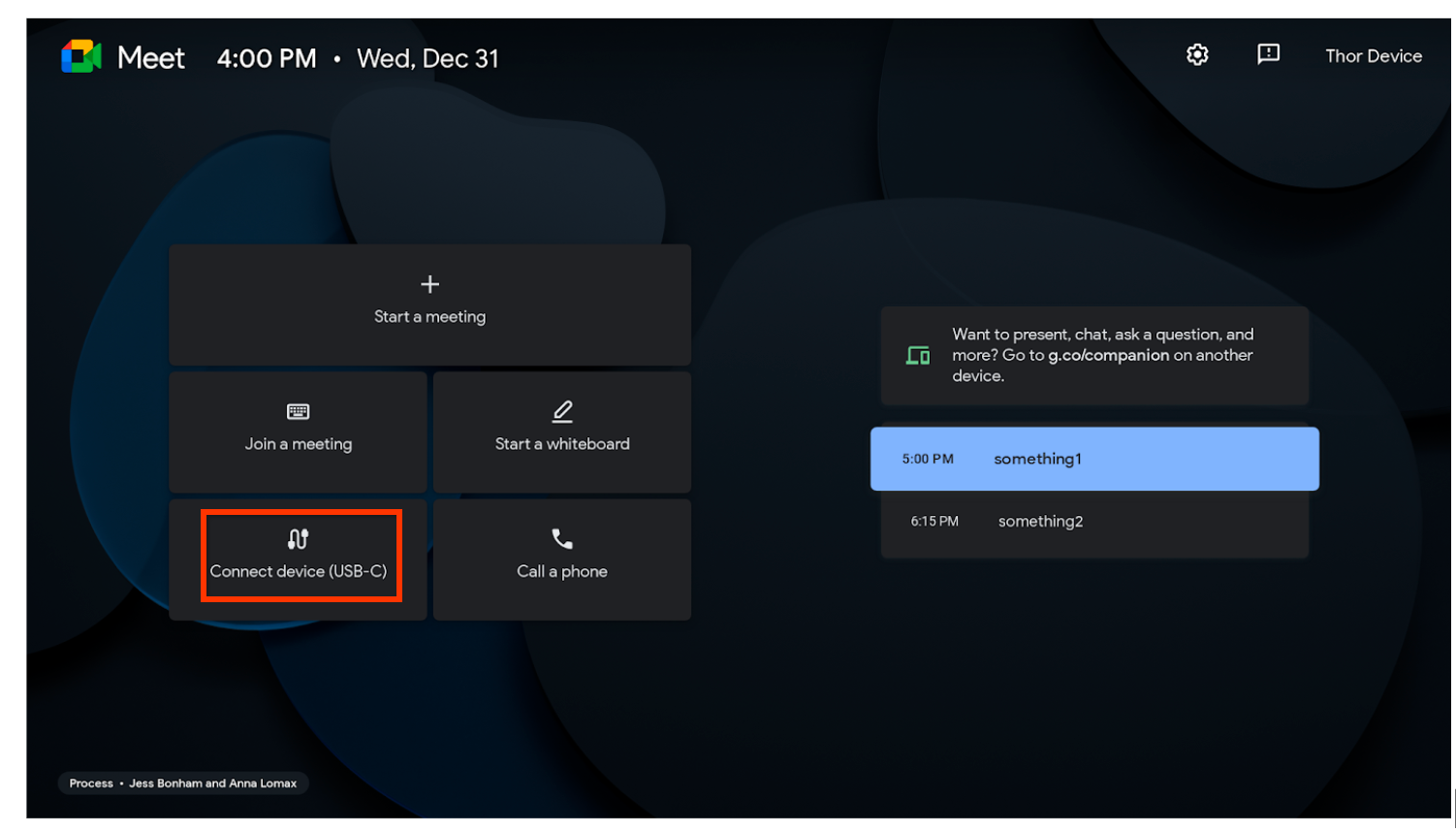
We’re updating the home screen on Series On Desk 27 and Board 65 devices to feature a “Connect device” button as a quick action.
One of the key values of the Desk 27 and Board 65 devices is the ability to use it as a primary monitor by connecting it to your laptop — by surfacing the “Connect device” button, you can take advantage of this capability faster. Further, this improves the discoverability of the feature, which was only accessible via a physical button on the back of the Desk 27 and Board 65.
Getting started
Admins and End users: No action required — these updates will be available automatically.
Posted by Lyanne Alfaro, DevRel Program Manager, Google Developer Studio
Developer Journey is a monthly series to spotlight diverse and global developers sharing relatable challenges, opportunities, and wins in their journey. Every month, we will spotlight developers around the world, the Google tools they leverage, and the kind of products they are building.
This month, it’s our pleasure to feature three members spanning communities, including Women Techmakers, Google Developer Experts and Google Developer Groups. Enjoy reading through their entries below and be on the lookout on social media platforms, where we will also showcase their work.
Deepa Subramanian
Google Developer Group, Women Techmakers Road to GDS Candidate, Web Technologies Freelance Software Engineer Find me on: LinkedIn
What Google tools have you used to build?
I am a frontend engineer, having used Angular framework for building single page applications, and using Chrome dev tools, like Puppeteer, Lighthouse, and more. I have also built progressive web app projects using project Fugu API’s to add to homescreen, badging, file share API etc. I am excited to see more API’s in the future.
Which tool has been your favorite to use? Why?
I enjoy using Firebase for authentication and realtime database as it makes my life easier as a frontend engineer.
Please share with us about something you’ve built in the past using Google tools.
In the past, I have built small applications using Android and Java. My first Google tool that I used was Android studio where I built small Android applications using Java (this was back in 2017). Then, I moved to the web. Currently, I am also using the Flutter web platform.
What advice would you give someone starting in their developer journey?
If you are a beginner, start building small projects. You will need to be consistently learning. I would urge everyone to join a developer community like GDG. It helps you grow and network with other developers.
Burcu Geneci
Former Women Techmakers Ambassador Co-Founder & CTO at Monday Hero, Inc. San Francisco, CA Find me on: LinkedIn, Instagram, Twitter
What Google tools have you used to build?
As a CTO and technical founder, I’ve used various Google Cloud services, including Cloud Run, Cloud Build, Cloud Storage, Google Maps Geocoding API, Kubernetes Engine, and Secret Manager.
At my startup Monday Hero, we’re building a solution that converts Figma design to code and generates Flutter widgets from design. I’m using Google tools related to Flutter almost every day. Dartpad.dev is always open and pinned on my browser. I find Flutter docs very clear and concise.
I also usually explore other Google tools in personal projects. For example, I’ve used ML Kit and Firebase for one of my hobby projects to recognize texts in images.
Which tool has been your favorite to use? Why?
My favorite tool so far is Google's open-source framework Flutter. It's very straightforward to create mobile, web, and desktop applications from a single codebase. The coolest part of Flutter is that applications written on Flutter are natively compiled. Creating natively working applications is very important for user experience. Before using Flutter, I built applications for both iOS and Android natively, but being able to build a mobile application for both platforms at least 30% faster is a game changer. Flutter is a life-saver for startups that want to create mobile solutions.
Considering new technologies like Flutter, the community around that specific technology is essential to adopting and improving the technology with honest feedback. I think the huge and welcoming community was one of the most important reasons to adopt and start using Flutter for my new projects. I want to thank the community builder and program managers for building the Flutter community worldwide.
Please share with us about something you’ve built in the past using Google tools.
After learning about ML Kit capabilities at Google IO 2018, I implemented ML Kit’s Text Recognition API on one of my iOS applications. It was surprisingly easy to build the solution, and the confidence rate was very high. Later that day, I also wrote a blog post for the Google Developer Community about the project and how smooth the integration was.
Knowing how to use technology to build creative solutions and what is possible with this kind of tech is a powerful skill. In the startup's early days, my cofounder and I attended a hackathon, and we won first place with the project in which we used ML Kit and Firebase. One of the project's key features was detecting the indicator number on the counter, which is used for utility usage via ML Kit's text recognition and alerting the user when there is water leakage.
What advice would you give someone starting in their developer journey?
Improve analytical and problem-solving skills early in your developer journey, and continuously invest in these skills!
A good developer should be able to identify and solve problems. Problem-solving is about using logic and imagination to analyze a situation and then develop smart solutions to that problem. Follow the tech leaders and influencers in your area of interest and learn something new every day!
Katerina Skroumpelou
Google Developer Expert, Angular, Web Technologies, and Google Maps Platform Senior Software Engineer at Nx Athens, Greece Find me on: Twitter
What Google tools have you used to build?
I have used Firebase, Google Cloud Platform, Google Cloud Functions, Google Maps Platform, Angular, Google Cloud Run.
As part of my previous job, our whole infrastructure was built in Firebase, using Cloud Firestore, and Google Cloud Functions used for microservices and also for custom Firestore queries. We also used a combination of Google Cloud Run and Cloud Storage for scheduled backups. In a previous position, I used the Google Maps JS API, which now has evolved into so much more as part of the Google Maps Platform. Today, I build demos and POCs mostly in my free time, using the Google Maps Platform which I love so much. My current role does not involve Google tools at the moment.
Which tool has been your favorite to use? Why?
My favorite tool by far is Firebase. I love the robustness and reliability that it offers in developing and publishing a web application. It offers a solution for every part of the process, be it the backend, storage, database, microservices, hosting, authentication, even analytics. All in one place, easy to use and implement. What is also amazing with Firebase is the scalability that it offers. I would opt to use Firebase whether it is a small demo app I am building for a conference, or a large scale application which involves a huge user base, data, and hits per second.
My second favorite tool is, of course, the Google Maps Platform. Maps excite me, and the Google Maps Platform offers much more than visualizing data on a map - which it does in an amazing way. It has become almost a game engine, in a way, providing access to so many different APIs and features of the map itself for the user to tweak.
Please share with us about something you’ve built in the past using Google tools.
I have used Firebase and the Google Cloud Platform to build and ship applications. A few years ago, a couple of friends and myself had an idea that we turned into a product, which we built and scaled solely using the Google Cloud Platform, and specifically the following features: Cloud Firestore, Cloud Storage, Cloud Run, Cloud Functions, BigQuery, Maps Platform, Authentication. That’s all you really need to build any app today.
What advice would you give someone starting in their developer journey?
Be social: Connect with other people by going to on-site conferences. And always be kind.
Continue skill-building: Build small apps and demos to test out different things, and see how they work. Don’t worry about learning all technologies, and don’t “marry” one technology, either. Get a solid foundation of the basics (JavaScript/TypeScript), and then, at your new job, you will learn the technologies they are using there.
Finally, don’t get discouraged by bad days! If you love what you do, you’ll get there in the end, no matter what!
Last year, we expanded the client-side encryption beta to Google Calendar to help customers strengthen the confidentiality of their data while helping address a broad range of data sovereignty and compliance requirements. Today, we’re happy to announce that client-side encryption for Google Calendar is now generally available to eligible Workspace editions. Additionally, based on feedback from beta, we’ve extended client-side encryption to support Key Migration and Google Takeout.
When using client-side encryption for Calendar events, your event description, attachments, and Meet data is indecipherable to Google servers. You have control over encryption keys and the identity service to access those keys.
Who’s impacted
Admins and end users
Why it’s important
Google Workspace already uses the latest cryptographic standards to encrypt data at rest and in transit between our facilities. With client-side encryption, we’re taking this a step further by giving customers direct control of encryption keys and the identity provider used to access those keys. This can help you strengthen the confidentiality of your data while helping to address a broad range of data sovereignty and compliance needs.
Client-side encryption allows you to create a fundamentally stronger privacy posture, whether that’s to help your organization comply with regulations like ITAR and CJIS or simply to better protect the privacy of your confidential data.
Additional details
Client-side encryption for Google Calendar on mobile is currently in beta. Google Workspace Enterprise Plus, Education Plus, and Education Standard customers are eligible to apply for the mobile beta here until March 3, 2023.
Getting started
Admins: This feature will be OFF by default and can be enabled at the domain, OU, and Group levels. Go to the Admin console > Security > Access and data control > Client-side encryption. Visit the Help Center to learn more about client-side encryption.
End users:
You will need to be logged in with your Identity Provider to have access to encrypted content.
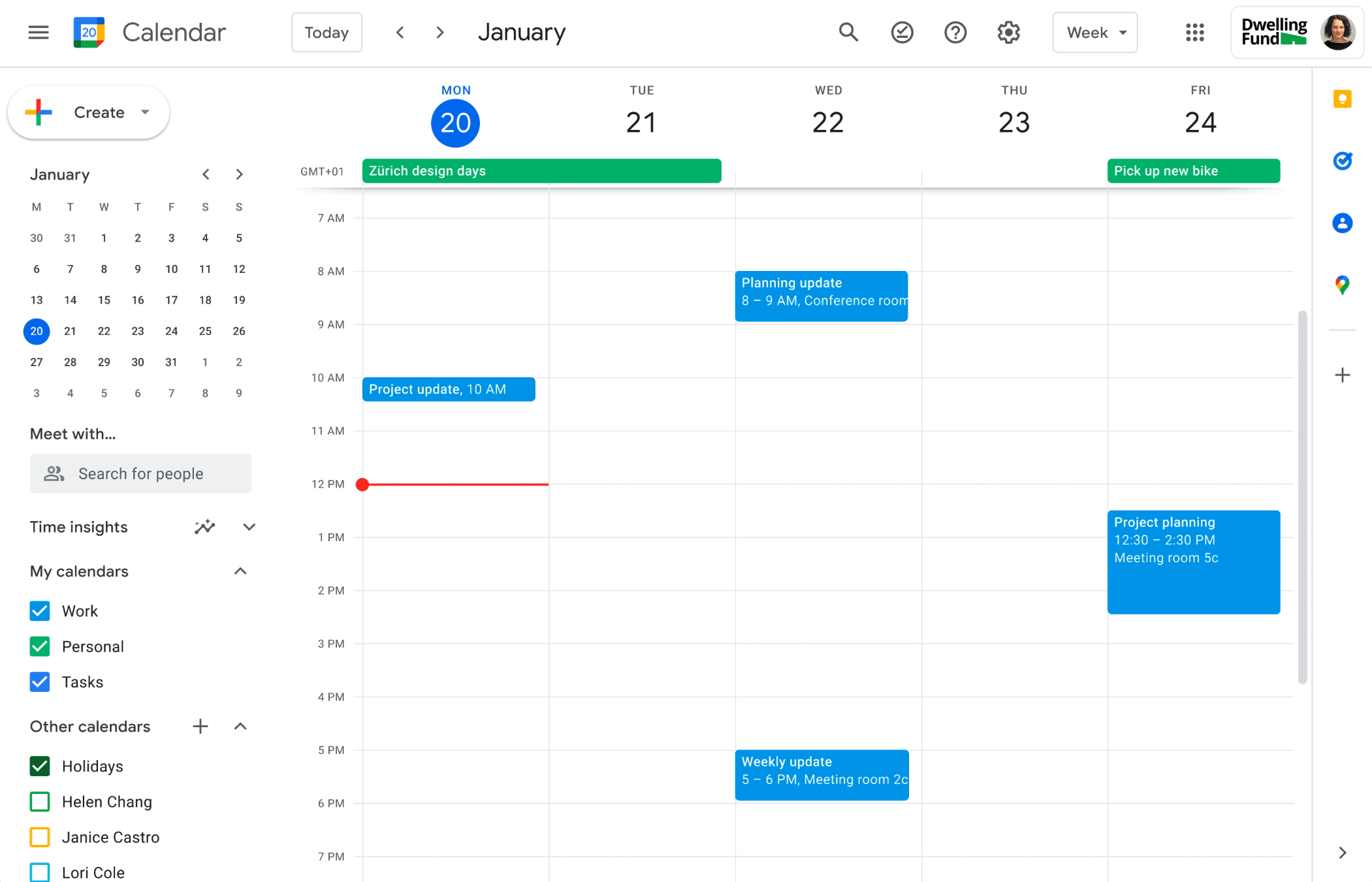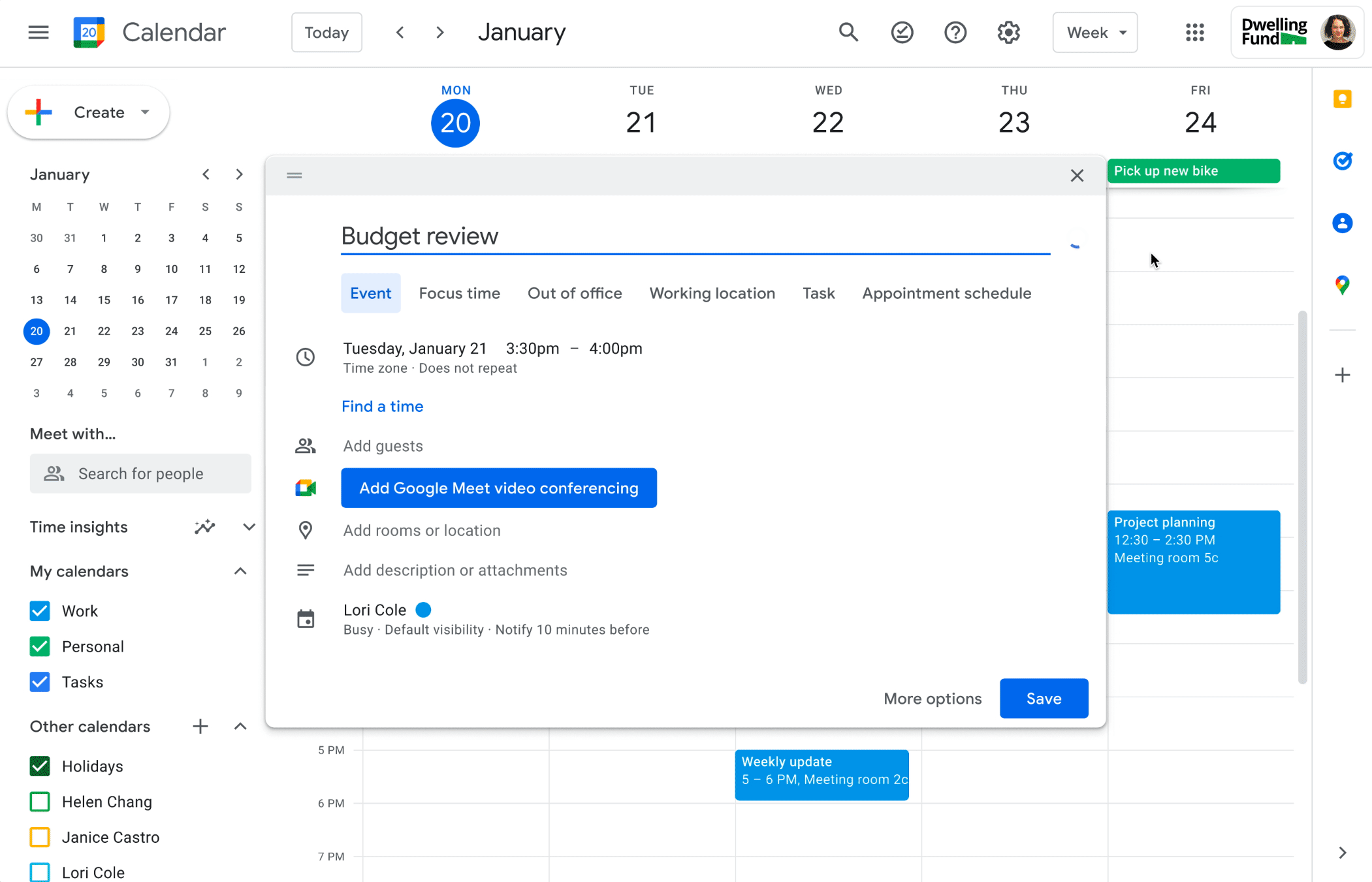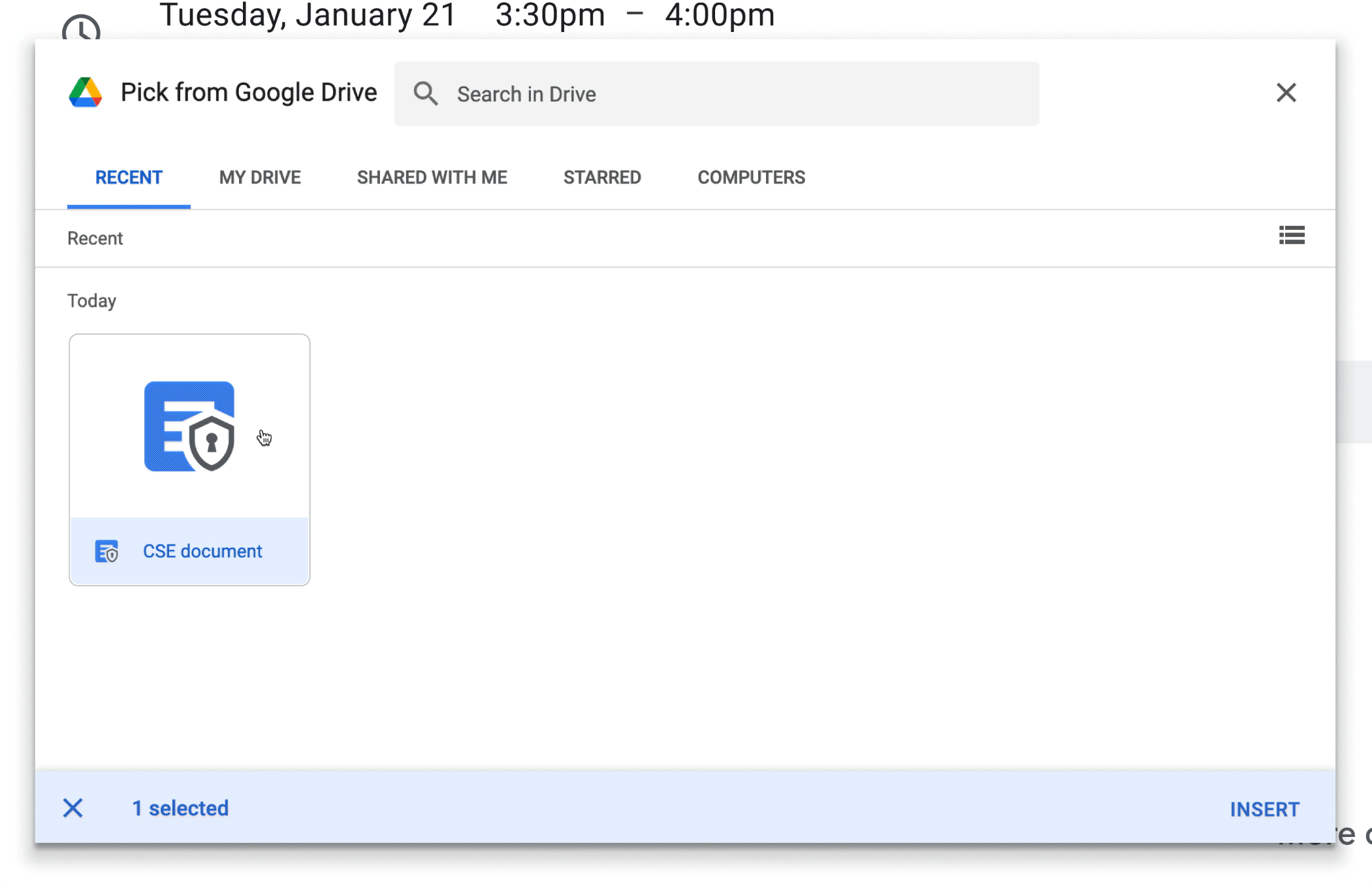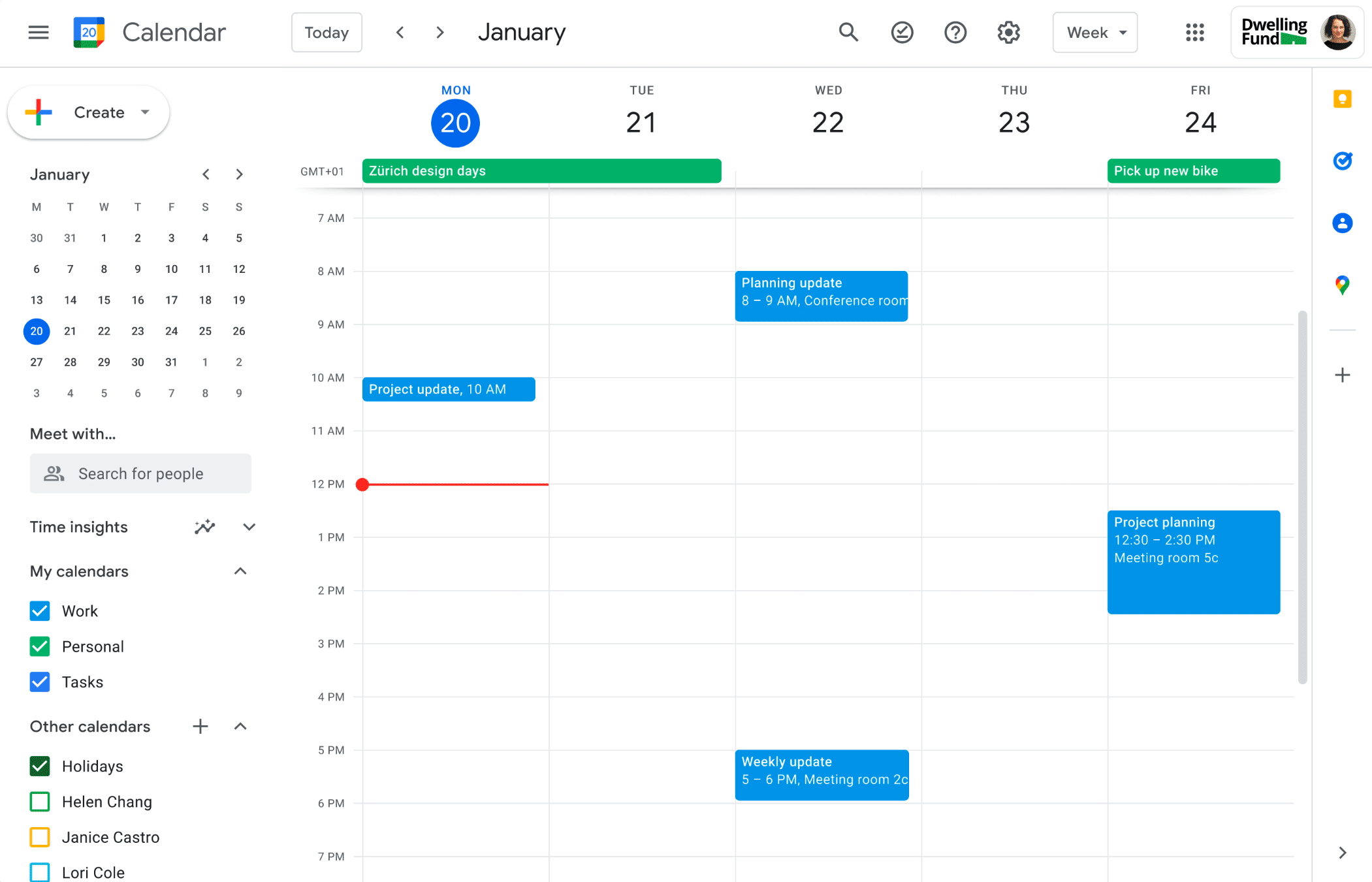
To add encryption to any event in Calendar, click on the shield icon at the top of the event creation card. This will add encryption to event description, attachments, and Meet, while other items such as event title, time, and guests remain on standard encryption.
Available to Google Workspace Enterprise Plus, Education Plus, and Education Standard customers
Not available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Enterprise Standard, Education Fundamentals, Frontline, and Nonprofits, as well as legacy G Suite Basic and Business customers
Not available to users with personal Google Accounts
The Stable channel has been updated to 110.0.5481.100 for Windows, Mac and Linux, which will roll out over the coming days/weeks. A full list of changes in this build is available in the log.
The Extended Stable channel has been updated to 110.0.5481.100 for Windows andMac which will roll out over the coming days/weeks.
Interested in switching release channels? Find out how here. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.











.jpg "Nick Saporito, Head of Multi-gig and Commercial Product")
 5 Gig offers symmetrical upload and download speeds with a Wi-Fi 6 router (or you can easily use your own), up to two mesh extenders and professional installation, all for $125 a month. Installation also includes an upgraded 10 Gig Fiber Jack, which means your home will be prepared for even more internet when the time comes.
5 Gig offers symmetrical upload and download speeds with a Wi-Fi 6 router (or you can easily use your own), up to two mesh extenders and professional installation, all for $125 a month. Installation also includes an upgraded 10 Gig Fiber Jack, which means your home will be prepared for even more internet when the time comes. 







 New features in Display & Video 360 to help you plan, buy and measure your CTV campaigns.
New features in Display & Video 360 to help you plan, buy and measure your CTV campaigns.