Answers to some common questions about appearing in Google News
Today, we’re answering some common questions we've heard from publishers to help them better understand
how news appears on Google News and Google Search.
Hi, everyone! We've just released Chrome 91 (91.0.4472.164) for Android: it'll become available on Google Play over the next few weeks.
This release includes stability and performance improvements. You can see a full list of the changes in the Git log. If you find a new issue, please let us know by filing a bug.The Stable channel has been updated to 91.0.4472.164 for Windows, Mac and Linux which will roll out over the coming days/weeks.
A full list of changes in this build is available in the log. Interested in switching release channels? Find out how here. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
Security Fixes and Rewards
Note: Access to bug details and links may be kept restricted until a majority of users are updated with a fix. We will also retain
restrictions if the bug exists in a third party library that other projects similarly depend on, but haven’t yet fixed.
This update includes 8 security fixes. Below, we highlight fixes that were contributed by external researchers.
Please see the Chrome Security Pagfor more information.
[$7500][1219082] High CVE-2021-30559: Out of bounds write in ANGLE. Reported by Seong-Hwan Park (SeHwa) of SecunologyLab on 2021-06-11
[$5000][1214842] High CVE-2021-30541: Use after free in V8. Reported by Richard Wheeldon on 2021-05-31
[$N/A][1219209] High CVE-2021-30560: Use after free in Blink XSLT. Reported by Nick Wellnhofer on 2021-06-12
[$TBD][1219630] High CVE-2021-30561: Type Confusion in V8. Reported by Sergei Glazunov of Google Project Zero on 2021-06-14
[$TBD][1220078] High CVE-2021-30562: Use after free in WebSerial. Reported by Anonymous on 2021-06-15
[$TBD][1228407] High CVE-2021-30563: Type Confusion in V8. Reported by Anonymous on 2021-07-12
[$TBD][1221309] Medium CVE-2021-30564: Heap buffer overflow in WebXR. Reported by Ali Merchant, iQ3Connect VR Platform on 2021-06-17
We would also like to thank all security researchers that worked with us during the development cycle to prevent security bugs from ever reaching the stable channel.
Google is aware of reports that an exploit for CVE-2021-30563 exists in the wild.
As usual, our ongoing internal security work was responsible for a wide range of fixes:
[1229408] Various fixes from internal audits, fuzzing and other initiatives
Many of our security bugs are detected using AddressSanitizer, MemorySanitizer, UndefinedBehaviorSanitizer, Control Flow Integrity, libFuzzer, or AFL.
Reinforcement learning (RL) is a popular method for teaching robots to navigate and manipulate the physical world, which itself can be simplified and expressed as interactions between rigid bodies1 (i.e., solid physical objects that do not deform when a force is applied to them). In order to facilitate the collection of training data in a practical amount of time, RL usually leverages simulation, where approximations of any number of complex objects are composed of many rigid bodies connected by joints and powered by actuators. But this poses a challenge: it frequently takes millions to billions of simulation frames for an RL agent to become proficient at even simple tasks, such as walking, using tools, or assembling toy blocks.
While progress has been made to improve training efficiency by recycling simulation frames, some RL tools instead sidestep this problem by distributing the generation of simulation frames across many simulators. These distributed simulation platforms yield impressive results that train very quickly, but they must run on compute clusters with thousands of CPUs or GPUs which are inaccessible to most researchers.
In “Brax - A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, we present a new physics simulation engine that matches the performance of a large compute cluster with just a single TPU or GPU. The engine is designed to both efficiently run thousands of parallel physics simulations alongside a machine learning (ML) algorithm on a single accelerator and scale millions of simulations seamlessly across pods of interconnected accelerators. We’ve open sourced the engine along with reference RL algorithms and simulation environments that are all accessible via Colab. Using this new platform, we demonstrate 100-1000x faster training compared to a traditional workstation setup.
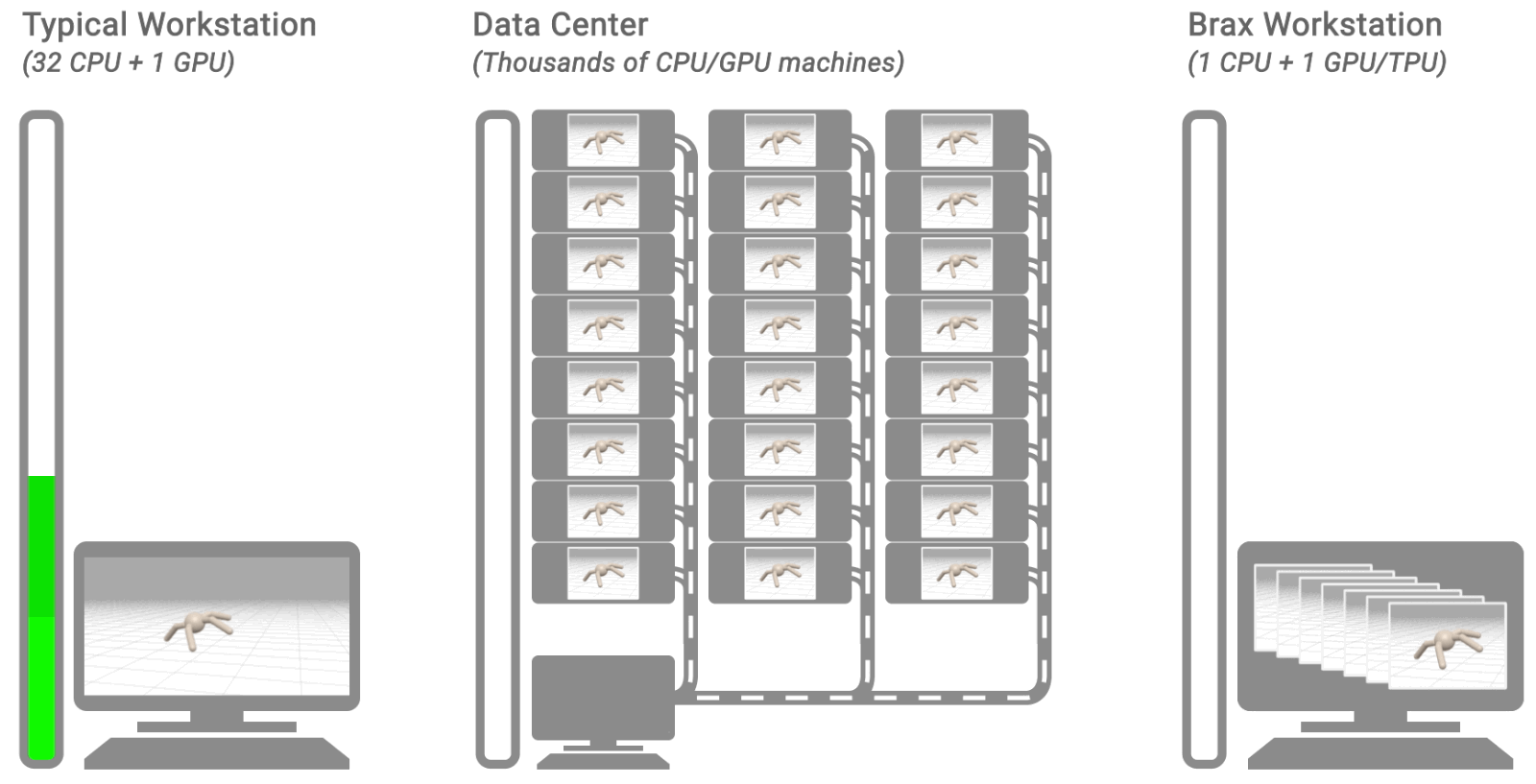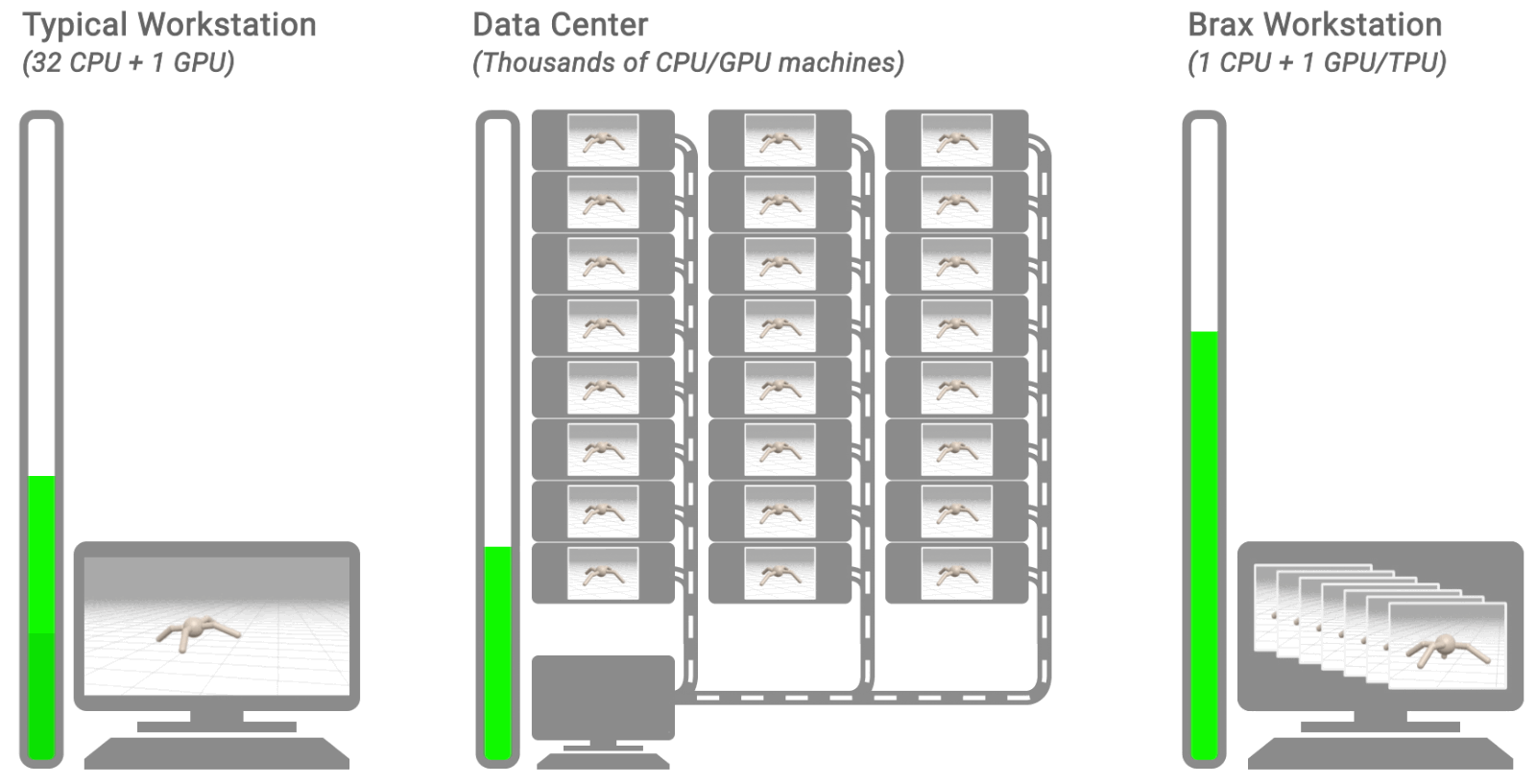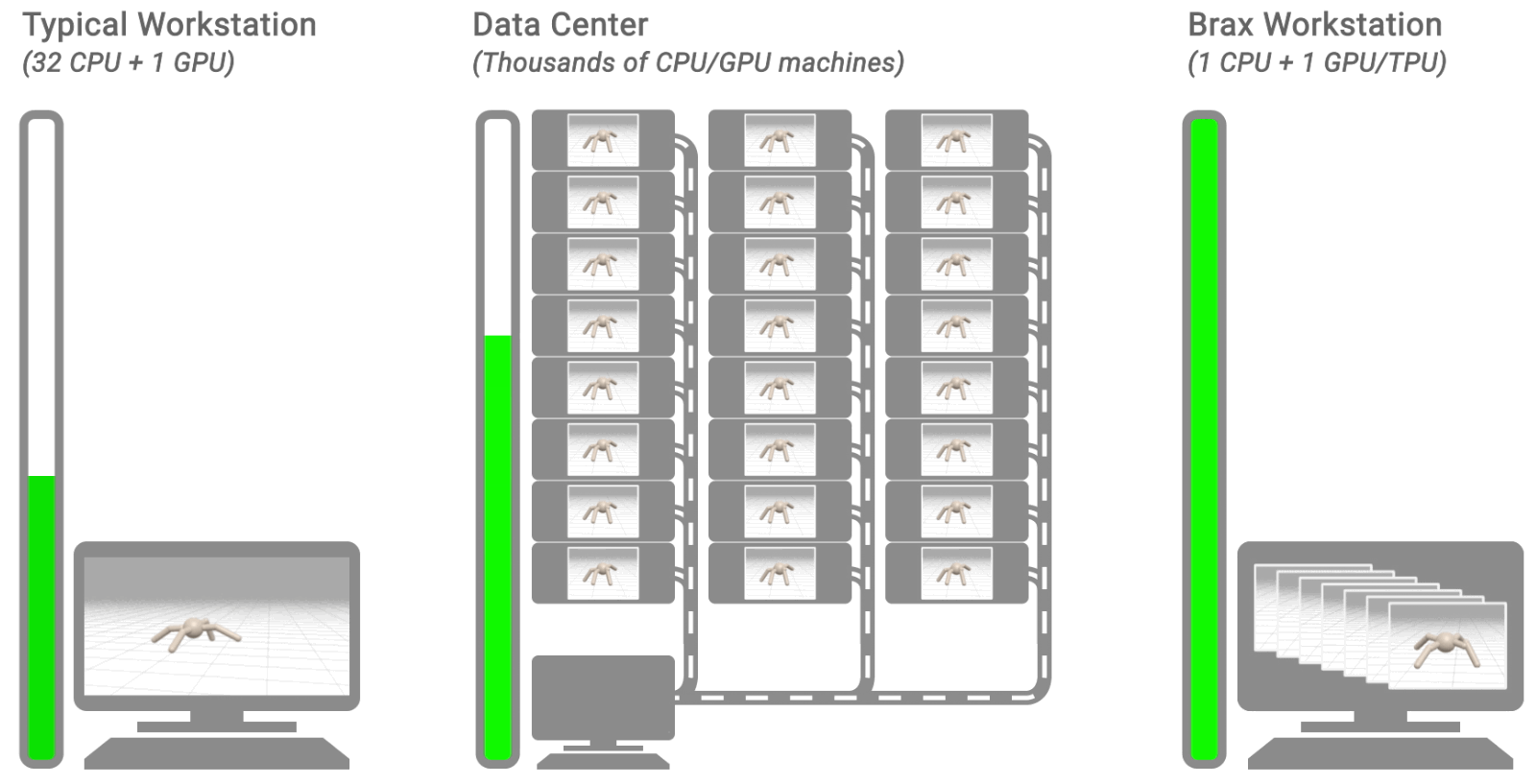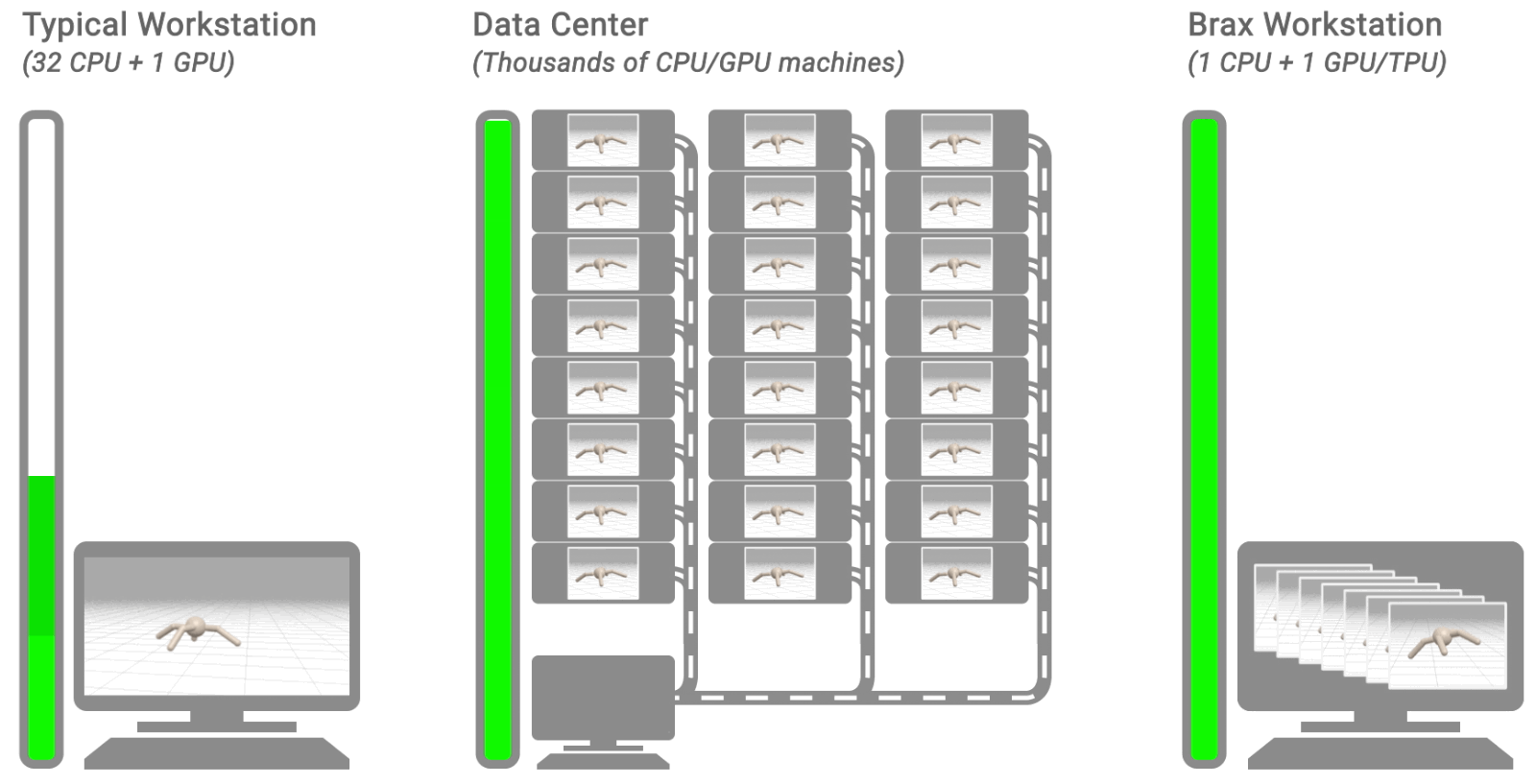 |
| Three typical RL workflows. The left shows a typical workstation flow: on a single machine, with the environment on CPU, training takes hours or days. The middle shows a typical distributed simulation flow: training takes minutes by farming simulation out to thousands of machines. The right shows the Brax flow: learning and large batch simulation occur side by side on a single CPU/GPU chip. |
Physics Simulation Engine Design Opportunities
Rigid body physics are used in video games, robotics, molecular dynamics, biomechanics, graphics and animation, and other domains. In order to accurately model such systems, simulators integrate forces from gravity, motor actuation, joint constraints, object collisions, and others to simulate the motion of a physical system across time.
 |
| Simulation of three spherical bodies, a wall, two joints, and one actuator. For each simulation timestep, forces and torques are integrated together to update the positions, rotations, and velocities of each physical body. |
Taking a closer look at how most physics simulation engines are designed today, there are a few large opportunities to improve efficiency. As we noted above, a typical robotics learning pipeline places a single learner in a tight feedback with many simulations in parallel, but upon analyzing this architecture, one finds that:
Brax Design
In response to these observations, Brax is designed so that its physics calculations are exactly the same across each of its thousands of parallel environments by ensuring that the simulation is free of branches (i.e., simulation “if” logic that diverges as a result of the environment state). An example of a branch in a physics engine is the application of a contact force between a ball and a wall: different code paths will execute depending on whether the ball is touching the wall. That is, if the ball contacts the wall, separate code for simulating the ball’s bounce off the wall will execute. Brax employs a mix of the following three strategies to avoid branching:
Once the calculations are guaranteed to be exactly uniform, the entire training architecture can be reduced in complexity to be executed on a single TPU or GPU. Doing so removes the computational overhead and latency of cross-machine communication. In practice, these changes lower the cost of training by 100x-1000x for comparable workloads.
Brax Environments
Environments are tiny packaged worlds that define a task for an RL agent to learn. Environments contain not only the means to simulate a world, but also functions, such as how to observe the world and the definition of the goal in that world.
A few standard benchmark environments have emerged in recent years for testing new RL algorithms and for evaluating the impact of those algorithms using metrics commonly understood by research scientists. Brax includes four such ready-to-use environments that come from the popular OpenAI gym: Ant, HalfCheetah, Humanoid, and Reacher.
 |  |  |  |
| From left to right: Ant, HalfCheetah, Humanoid, and Reacher are popular baseline environments for RL research. |
Brax also includes three novel environments: dexterous manipulation of an object (a popular challenge in robotics), generalized locomotion (an agent that goes to a target placed anywhere around it), and a simulation of an industrial robot arm.
 |  |  |
| Left: Grasp, a claw hand that learns dexterous manipulation. Middle: Fetch, a toy, box-like dog learns a general goal-based locomotion policy. Right: Simulation of UR5e, an industrial robot arm. |
Performance Benchmarks
The first step for analyzing Brax’s performance is to measure the speed at which it can simulate large batches of environments, because this is the critical bottleneck to overcome in order for the learner to consume enough experience to learn quickly.
These two graphs below show how many physics steps (updates to the state of the environment) Brax can produce as it is tasked with simulating more and more environments in parallel. The graph on the left shows that Brax scales the number of steps per second linearly with the number of parallel environments, only hitting memory bandwidth bottlenecks at 10,000 environments, which is not only enough for training single agents, but also suitable for training entire populations of agents. The graph on the right shows two things: first, that Brax performs well not only on TPU, but also on high-end GPUs (see the V100 and P100 curves), and second, that by leveraging JAX’s device parallelism primitives, Brax scales seamlessly across multiple devices, reaching hundreds of millions of physics steps per second (see the TPUv3 8x8 curve, which is 64 TPUv3 chips directly connected to each other over a high speed interconnect) .
 |
| Left: Scaling of the simulation steps per second for each Brax environment on a 4x2 TPU v3. Right: Scaling of the simulation steps per second for several accelerators on the Ant environment. |
Another way to analyze Brax’s performance is to measure its impact on the time it takes to run a reinforcement learning experiment on a single workstation. Here we compare Brax training the popular Ant benchmark environment to its OpenAI counterpart, powered by the MuJoCo physics engine.
In the graph below, the blue line represents a standard workstation setup, where a learner runs on the GPU and the simulator runs on the CPU. We see that the time it takes to train an ant to run with reasonable proficiency (a score of 4000 on the y axis) drops from about 3 hours for the blue line, to about 10 seconds using Brax on accelerator hardware. It’s interesting to note that even on CPU alone (the grey line), Brax performs more than an order of magnitude faster, benefitting from learner and simulator both sitting in the same process.
 |
| Brax’s optimized PPO versus a standard GPU-backed PPO learning the MuJoCo-Ant-v2 environment, evaluated for 10 million steps. Note the x-axis is log-wallclock-time in seconds. Shaded region indicates lowest and highest performing seeds over 5 replicas, and solid line indicates mean. |
Physics Fidelity
Designing a simulator that matches the behavior of the real world is a known hard problem that this work does not address. Nevertheless, it is useful to compare Brax to a reference simulator to ensure it is producing output that is at least as valid. In this case, we again compare Brax to MuJoCo, which is well-regarded for its simulation quality. We expect to see that, all else being equal, a policy has a similar reward trajectory whether trained in MuJoCo or Brax.
 |
| MuJoCo-Ant-v2 vs. Brax Ant, showing the number of environment steps plotted against the average episode score achieved for the environment. Both environments were trained with the same standard implementation of SAC. Shaded region indicates lowest and highest performing seeds over five runs, and solid line indicates the mean. |
These curves show that as the reward rises at about the same rate for both simulators, both engines compute physics with a comparable level of complexity or difficulty to solve. And as both curves top out at about the same reward, we have confidence that the same general physical limits apply to agents operating to the best of their ability in either simulation.
We can also measure Brax’s ability to conserve linear momentum, angular momentum, and energy.
 |
| Linear momentum (left), angular momentum (middle), and energy (right) non-conservation scaling for Brax as well as several other physics engines. The y-axis indicates drift from the expected calculation (higher is smaller drift, which is better), and the x axis indicates the amount of time being simulated. |
This measure of physics simulation quality was first proposed by the authors of MuJoCo as a way to understand how the simulation drifts off course as it is tasked with computing larger and larger time steps. Here, Brax performs similarly as its neighbors.
Conclusion
We invite researchers to perform a more qualitative measure of Brax’s physics fidelity by training their own policies in the Brax Training Colab. The learned trajectories are recognizably similar to those seen in OpenAI Gym.
Our work makes fast, scalable RL and robotics research much more accessible — what was formerly only possible via large compute clusters can now be run on workstations, or for free via hosted Google Colaboratory. Our Github repository includes not only the Brax simulation engine, but also a host of reference RL algorithms for fast training. We can’t wait to see what kind of new research Brax enables.
Acknowledgements
We'd like to thank our paper co-authors: Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. We also thank Erwin Coumans for advice on building physics engines, Blake Hechtman and James Bradbury for providing optimization help with JAX and XLA, and Luke Metz and Shane Gu for their advice. We’d also like to thank Vijay Sundaram, Wright Bagwell, Matt Leffler, Gavin Dodd, Brad Mckee, and Logan Olson, for helping to incubate this project.
1 Due to the complexity of the real world, there is also ongoing research exploring the physics of deformable bodies. ↩

#IamaGDE series presents: Google Maps
Welcome to #IamaGDE - a series of spotlights presenting Google Developer Experts (GDEs) from across the globe. Discover their stories, passions, and highlights of their community work.

Homing Tam is a product manager at Lalamove, an on-demand logistics company. He started at the company as a product manager focusing on location-based systems, talking with developers and business users to enhance the company’s mapping solutions, before moving into product management. Now, Homing handles corporate solutions; takes care of people who want to integrate with his company’s systems; handles the API side of things to help make integration easier; and provides recommendations for developers and other technical teammates.
Homing studied geomatics and computing at university, and his 2009 thesis was based on Google’s API backend. His dissertation focused on using the Google Maps API to perform mapping and overlay. His first full-time job was as a GIS analyst at Esri, the largest private software company in the world. A year and a half later, he became a solutions consultant for a different company, helping customers interested in integrating Google Maps with their software.

After Homing got involved in the Google Technology User Group (now known as Google Developer Groups), his boss at the time told him about the Google Developer Experts program. For his interview, Homing presented a product using the Google Maps APIs. When he became a GDE, he gave presentations and talks in the greater China region as a surrogate for the Google Maps Platform team. Homing is currently one of the organizers for GDG Hong Kong, organizing and giving community talks.
Homing says the Maps Styling Wizard, the precursor to the newer Cloud-based Maps Styling features, is one of his favorite features.
“Cartography, which I studied in college, matters a lot, especially to a simple black and white schematic map, or when matching the theme of a map to a site,” he says. “I like that feature a lot.”
In 2020, Homing gave one talk on Android in the Android 11 Meetup and another talk on Maps at the first-ever virtual Hong Kong Devfest, and he’s ready to do more speaking.
“It had been a while since I gave a talk on maps, and the launch of Cloud-based Maps Styling is so exciting that I feel like it’s time to do some presentations and let the community know more about it. Beyond knowing how to use the API, you need to know how you can make the most of the API.”
Homing notes that this year, in particular, more small business owners need to know how to collect customer addresses, allow customers to place on-demand delivery orders, and update customers.

In 2021, in addition to giving more talks, Homing hopes to work with the GDG organizers in Hong Kong to plan a hackathon or otherwise teach community members more about the new Maps features.
“Can we make an MVP or a really initial stage cycling app to use as a base to explore the new features and use different Google components?’
As his career continues, Homing says he has two priorities: progressing as a product manager and leveraging technology, including maps, to improve lives.
“This year was a year for everyone to become digitally literate,” he says. “With the extra time we spend on technology, we should make good use of technology to make life better.”
For more information on Google Maps Platform, visit our website.
For more information on Google Developer Experts, visit our website.
People around the world turn to Google Search to find information and make important decisions. We’re deeply committed to making sure you can do that safely and with the privacy you expect.
Today, we’re announcing a new tool to add extra protection to the Search history saved to your Google Account. And we’re sharing a few reminders about the features we offer to keep your searches safer and more private.
If your Web & App Activity setting is on, your Search history is saved to your account to enable more personalized experiences across Google services. You can view and delete that Search history any time at My Activity.
But maybe you share a device, and want to make sure others who use it can’t go into My Activity and look at your Search history. Now, we’ve given you a way to put extra protection around the searches saved in your account.
With this setting, you’ll need to provide additional information — like your password or two-factor authentication — before your full history can be viewed.
It’s easy for you to control how you want your Search history to be saved to your Google Account — including if you don’t want it saved at all.
With auto-delete controls, you can choose to have Google automatically and continuously delete your Search history, along with other Web & App Activity, from your account after three, 18 or 36 months. For new accounts, the default auto-delete option for Web & App Activity is 18 months, but you can always choose to update your settings if you’d like.
You can also try out a new way to quickly delete your last 15 minutes of saved Search history with the single tap of a button. This feature is available in the Google app for iOS, and is coming to the Android Google app later this year.
We also offer a range of check-ups to make sure your settings and password practices are giving you the privacy and security you want.
With a Privacy Checkup, we’ll walk you through key privacy settings step by step. When you’re finished, head over to Security Checkup for personalized recommendations to help protect your data and devices, like managing which third-party apps have access to your account data and learning if any of your passwords stored in Google Password Manager are weak. We also proactively notify you if we discover that any of these passwords have been compromised and whether you’ve reused them across multiple sites.
In addition to keeping your data private and secure, we also work to keep you safe while you’re browsing and searching for information on the web. Google Safe Browsing helps protect over four billion devices every day by showing people warnings when they attempt to navigate to dangerous sites or download dangerous files. We also notify webmasters when malicious actors compromise their websites, and we help them diagnose and resolve the problem so their visitors stay safer.
And our teams and systems are hard at work keeping dangerous and malicious sites from showing up in Google Search. Every day, our systems detect over 40 billion pagesof spam, which we block from appearing in Search.
It’s all part of our work to make Google the safer way to search.
The Beta channel has been updated to 92.0.4515.98 (Platform version: 13982.51.0) for most Chrome OS devices. This build contains a number of bug fixes, security updates and feature enhancements.
If you find issues, please let us know by visiting our forum or filing a bug. Interested in switching channels? Find out how. You can submit feedback using 'Report an issue...' in the Chrome menu (3 vertical dots in the upper right corner of the browser).
Daniel Gagnon
Google Chrome OS