Besides main application cores that are directly exposed to the users, many industrial and consumer devices include embedded controllers, which, although fairly invisible to the user, perform critical system tasks such as power management, receiving and processing user input, or signals from sensors like thermal. Given their role in the system, those MCUs need to be rigorously tested in CI. This is why the ChromeOS team has collaborated with Antmicro to simulate the ChromeOS FPMCU (Fingerprint Firmware) module, based on the ChromeOS EC (Embedded Controller) firmware in Antmicro’s Renode open source simulation framework.
This enables automated testing of embedded controllers in CI at scale, in a deterministic manner, and with complete observability. It also streamlines the developer feedback loop for faster development of microcontroller firmware that ChromeOS uses to drive peripherals, such as fingerprint readers or touchpads. To make this possible, we have improved the simulation capabilities for two of the microcontrollers used in FPMCU modules, popular in consumer electronics like Chromebooks and wearables, but also in many industrial applications: STM32F412 and STM32H743.
 |
| Testing consumer-grade products with Renode |
Continuous testing for embedded systems
The project required implementing continuous testing of the FPMCU module against tens of binaries that test the controller in the most common operations and scenarios to ensure maximum reliability at all times. A traditional approach would require reflashing the physical microcontroller memory with each binary, which is time-consuming and error-prone. To scratch that itch we developed the CrOS EC Tester, which runs all EC tests in a Renode simulation and uses GitHub Actions to handle building and executing test binaries for a truly automated workflow—useful both in CI and in an interactive development environment.
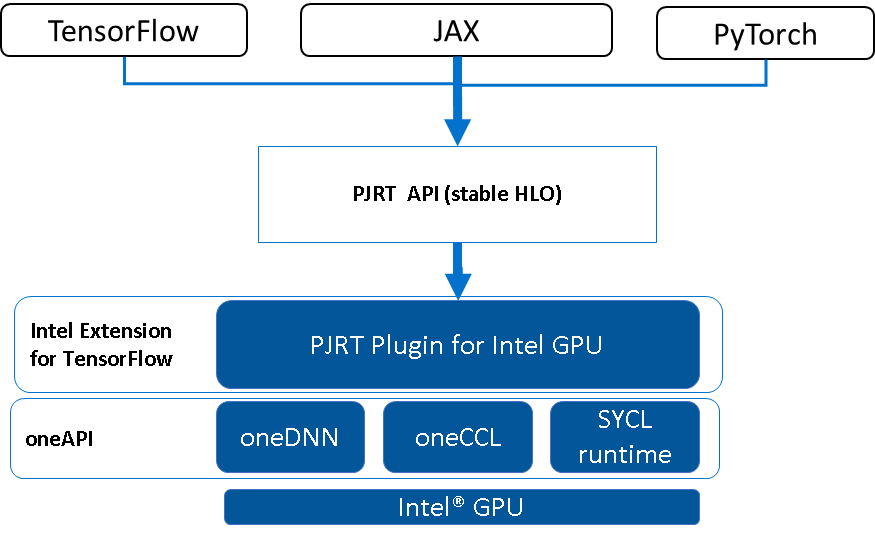
Renode has broad support for architectures such as (but not limited to) RISC-V, ARM Cortex-M, (recently added) Cortex-R or Cortex-A, and runs binary-compatible software. Thus, it is not limited to testing embedded controllers but entire multi-CPU systems. You can easily add Renode to an existing workflow without any major changes for testing in real-life scenarios. By moving all testing efforts into an interactive and deterministic environment of Renode, you can implement a fully CI-driven testing approach in your projects and benefit from advanced debugging, tracing, and prototyping capabilities.
Comprehensive simulation of STM32 microcontrollers
The Renode models of the STM32F412 and STM32H743 microcontrollers give you access to a broad range of peripherals, allowing you to run various scenarios you’d typically test on hardware. As a result of our collaboration with Google, we have added or improved models of ST peripherals like UART, EXTI, GPIO, DMA, ADC, SPI, flash controllers, timers, watchdogs, and more.
The need for in-depth testing has led to the introduction of many enhancements to ARM Cortex-M support in general, such as the MPU (Memory Protection Unit), which allows you to protect certain memory areas from unauthorized modification or access or FPU interrupts. These features can now be used by other Cortex-M-based projects to further extend their test coverage with Renode.
Renode for rapid, interactive prototyping
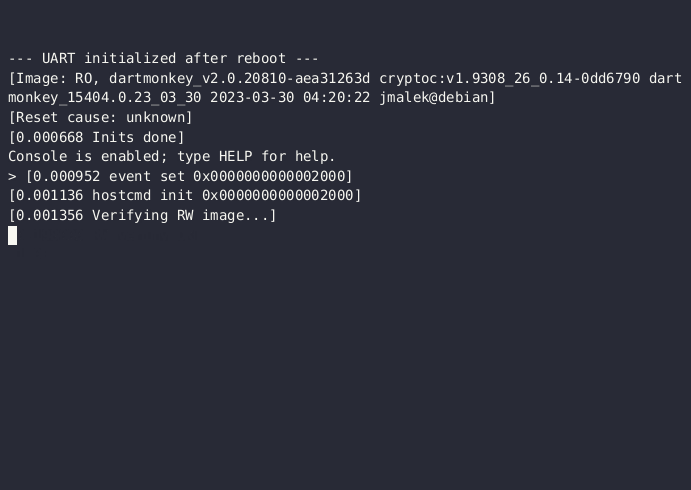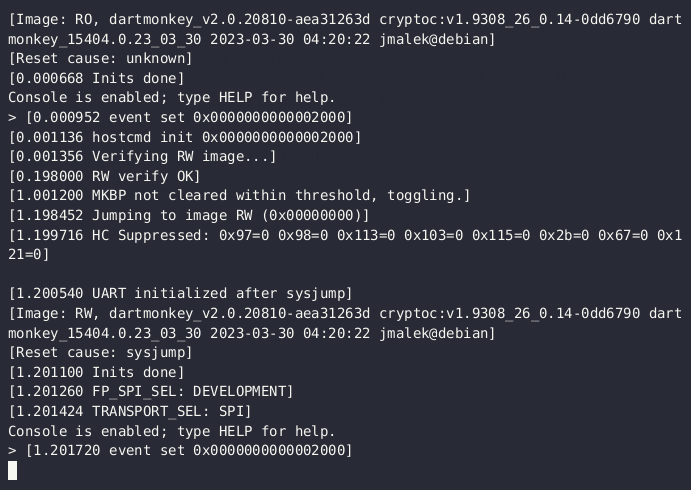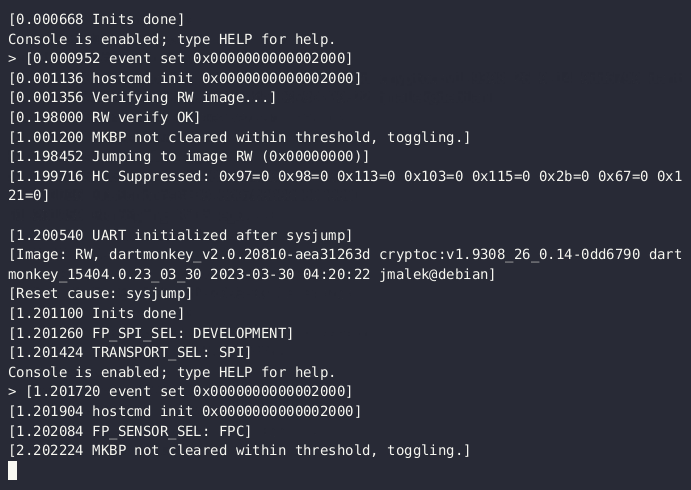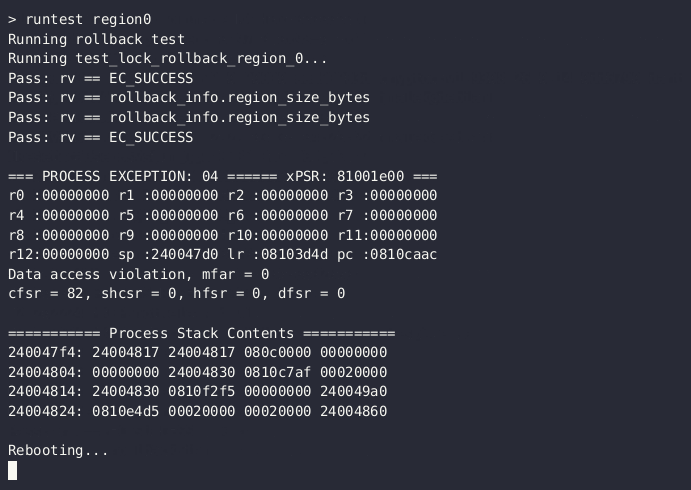
One of the tests from our test suite used the microcontroller's MPU module to test address space security. When you run the test-rollback test case, you can see that the MPU simulated in Renode successfully protected the OS from unauthorized memory access:
 |
| Testing consumer-grade products with Renode |
Another Renode feature that allowed us to increase our test coverage of the EC ecosystem is support for dummy SPI and I2C devices. While Renode supports a recently added advanced framework for time-controlled feeding of sensor data, many scenarios require much simpler interaction with the external device. For this purpose, we developed a dummy SPI device that simply returns pre-programmed data to the controller, which allowed us to pass initialization tests for a sensor without modeling the sensor itself. From the functional point of view of the simulation, the dummy sensor data is identical to the real data, which is useful when the specific component is difficult to model or lacks documentation.
Build a CI-driven test workflow with Renode
Renode is a powerful tool for automating and simplifying the test workflow in the project at any stage of development, even pre-silicon. It helps you reduce the tedium typically associated with embedded software testing by providing a fully controllable environment that can lead to fewer bugs and vulnerabilities, which is naturally important for mass-market products such as Chromebooks.
By Michael Gielda – Antmicro