In 2022, the research team within Google’s Open Source Programs Office launched an in-depth study to better understand open source developers, contributors, and maintainers. Since Alphabet is a large consumer of and contributor to open source, our primary goals were to investigate the evolving needs and motivations of open source contributors, and to learn how we can best support the communities we depend on. We also wanted to share our findings with the community in order to further research efforts and our collective understanding of open source work.
Key findings from this work suggest that community leaders should:
- Value your time together and apart: Lack of time was cited as the leading reason ‘not to contribute’ as well as motivation to ‘leave a community’. This should encourage community leaders to adopt practices that ensure that they are making the most of the time they have together. One example: some projects have planned breaks, no-meeting weeks, or official slowdowns during holidays or popular conference weeks.
- Invest in documentation: Contributors and maintainers expressed that task variety, delegation, and onboarding new maintainers could help to reduce burnout in open source. Documentation is one way to make individual knowledge accessible to the community. In addition to technical and procedural overviews, documentation can also be used to clarify roles, tasks, expectations, and a path to leadership.
- Always communicate with care: Contributors prefer projects that have welcoming communities, clear onboarding paths, and a code of conduct. Communication is the primary way for community leaders to promote welcoming and inclusive communities and set norms around language and behavior (as documented in a Code of Conduct). Communication is also how we build relationships, trust, and respect for each other.
- Create spaces for anonymous feedback: Variable answers between demographic subsets in our research suggest that while systematic approaches can be taken to reduce burnout, there is no one-size-fits-all approach. Feedback is a valuable tool for any project to adjust to the evolving needs of their contributor and user communities. When designed appropriately, surveys can serve as safe, anonymous, retaliation-free spaces for individuals to provide honest feedback.
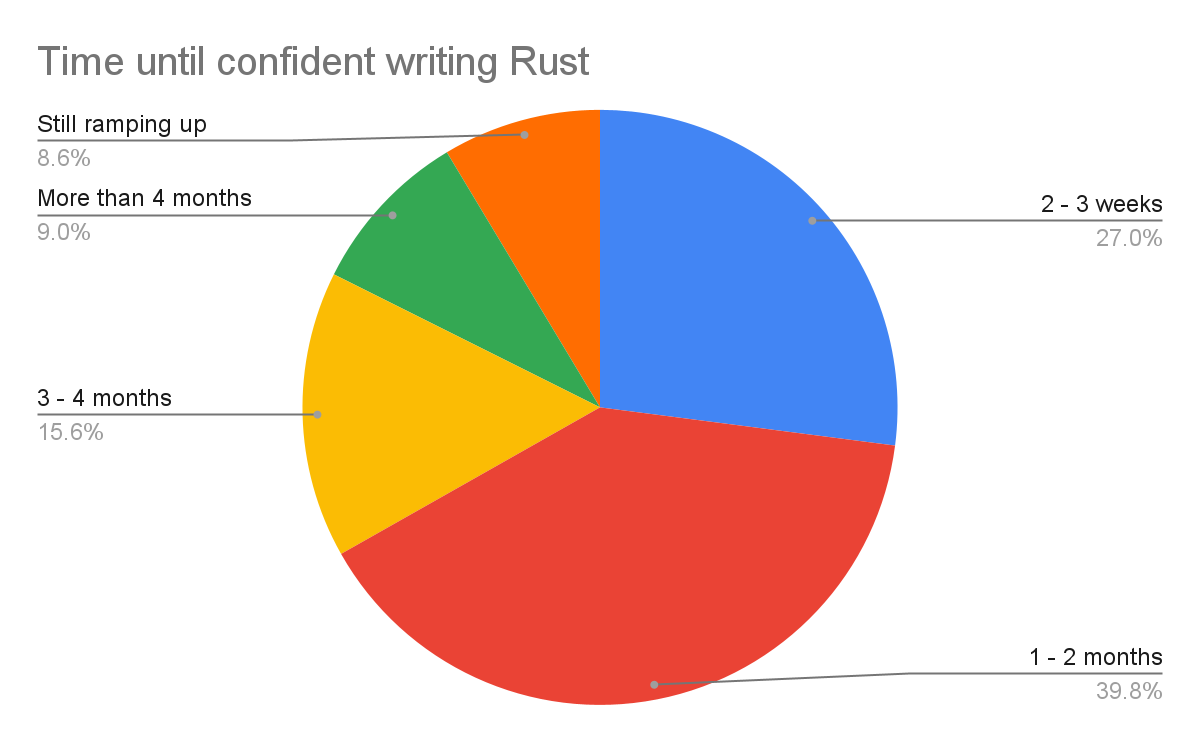
How do contributors select projects?
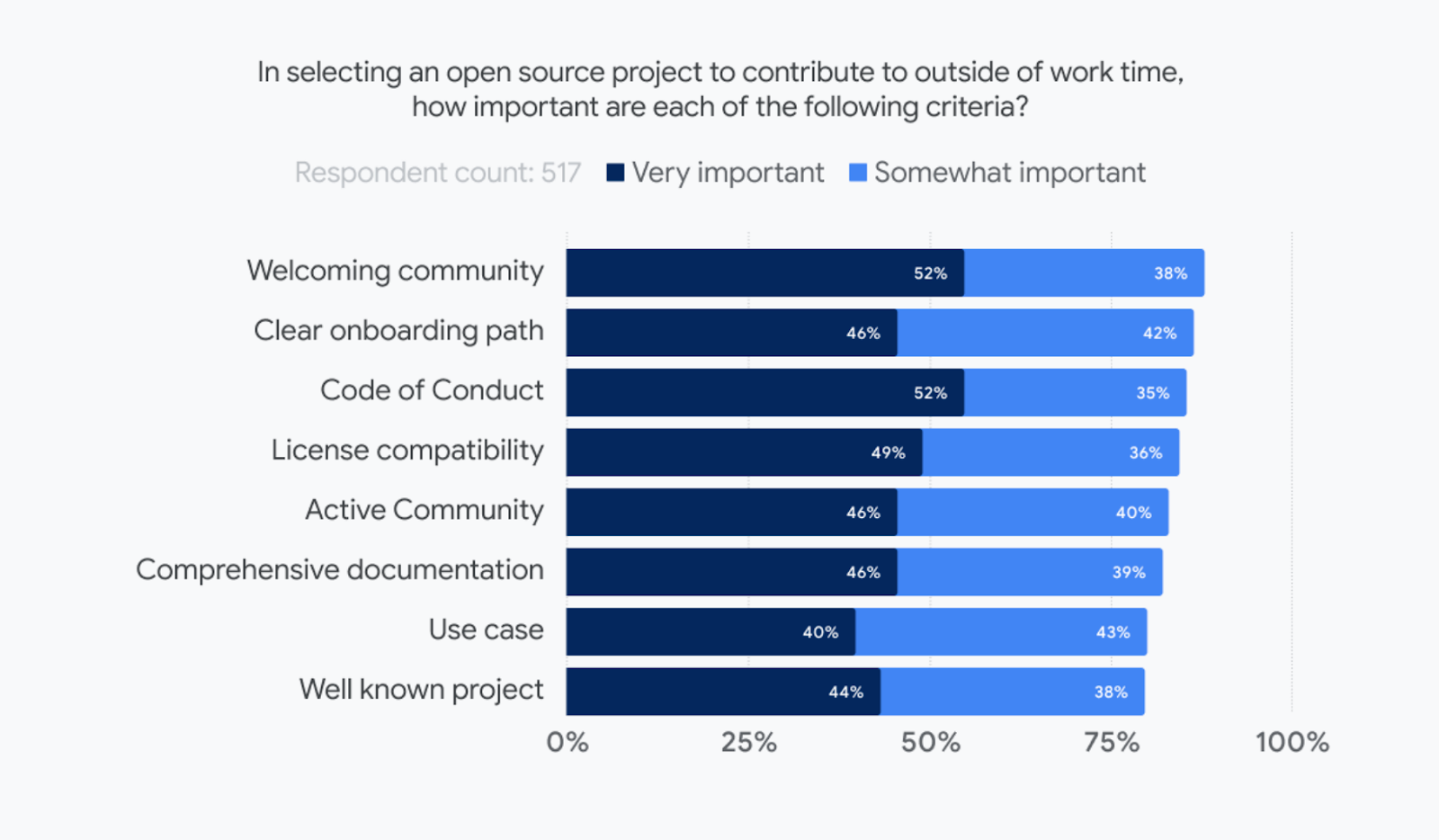 |
| Base: 517 international OSS developers, contributors, maintainers and students who worked on open source in their personal time |
Within Google’s Open Source Programs office, we are constantly looking for ways to improve support for contributors inside and outside of Google. Studies such as this one provide guidance to our programs and investments in the community. This work helps us to see we should continue to:
- Invest in documentation competency: Google Season of Docs provides support for open source projects to improve their documentation and gives professional technical writers an opportunity to gain experience in open source.
- Document roles and promote tactics that recognize work within communities: The ACROSS project continues to work with projects and communities to establish consistent language to define roles, responsibilities, and work done within open source projects.
- Exercise and discuss ‘better’ practices within the community: While we continually seek to improve our engagement practices within communities, we will also continue to share these experiences with the broader community in hopes that we can all learn from our successes and challenges. For example, we’ve published documentation around our release process, including resources for the creation and management of a code of conduct.
This research, along with other articles authored by the OSPO research team is now available on our site.
By Sophia Vargas – Researcher, Google Open Source Programs Office