Posted by Greg Corrado*, Senior Research ScientistMachine Intelligence for YouWhat I love about working at Google is the opportunity to harness cutting-edge machine intelligence for users’ benefit. Two recent Research Blog posts talked about how we’ve used machine learning in the form of
deep neural networks to improve
voice search and
YouTube thumbnails. Today we can share something even wilder -- Smart Reply, a deep neural network that writes email.
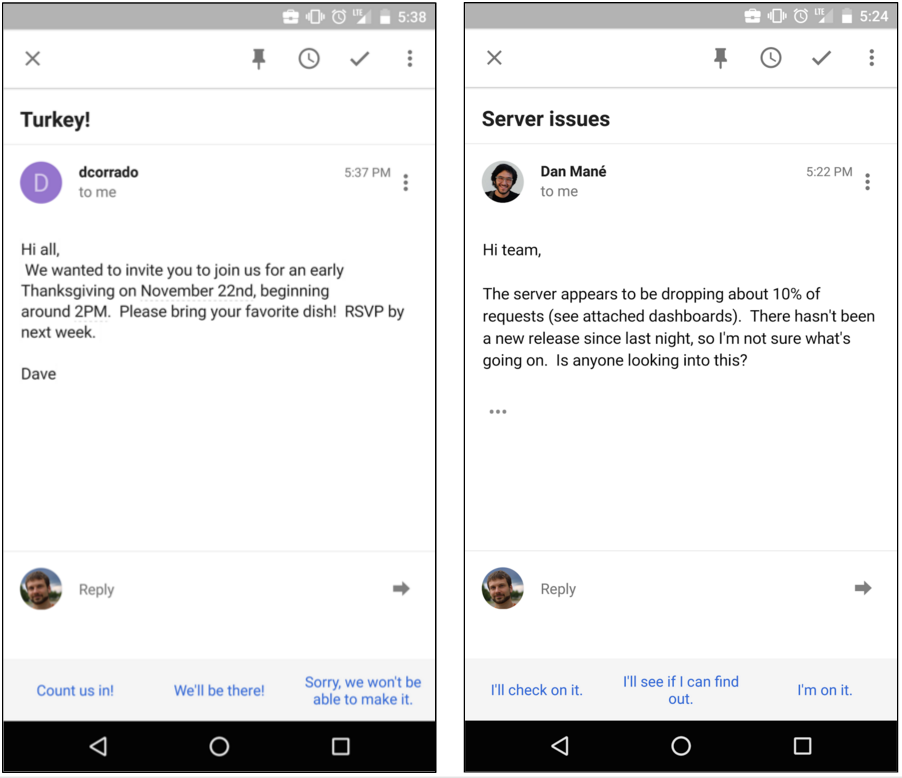
I get a lot of email, and I often peek at it on the go with my phone. But replying to email on mobile is a real pain, even for short replies. What if there were a system that could automatically determine if an email was answerable with a short reply, and compose a few suitable responses that I could edit or send with just a tap?
Some months ago, Bálint Miklós from the Gmail team asked me if such a thing might be possible. I said it sounded too much like passing the
Turing Test to get our hopes up... but having collaborated before on machine learning improvements to spam detection and email categorization, we thought we’d give it a try.
There’s a long history of research on both understanding and generating natural language for applications like machine translation. Last year, Google researchers Oriol Vinyals, Ilya Sutskever, and Quoc Le proposed fusing these two tasks in what they called
sequence-to-sequence learning. This end-to-end approach has many possible applications, but one of the most unexpected that we’ve experimented with is conversational synthesis.
Early results showed that we could use sequence-to-sequence learning to power a chatbot that was remarkably
fun to play with, despite having included no explicit knowledge of language in the program.
Obviously, there’s a huge gap between a cute research chatbot and a system that I want helping me draft email. It was still an open question if we could build something that was actually useful to our users. But one engineer on our team, Anjuli Kannan, was willing to take on the challenge. Working closely with both Machine Intelligence researchers and Gmail engineers, she elaborated and experimented with the sequence-to-sequence research ideas. The result is the industrial strength neural network that runs at the core of the Smart Reply feature we’re launching this week.
How it worksA naive attempt to build a response generation system might depend on hand-crafted rules for common reply scenarios. But in practice, any engineer’s ability to invent “rules” would be quickly outstripped by the tremendous diversity with which real people communicate. A machine-learned system, by contrast, implicitly captures diverse situations, writing styles, and tones. These systems generalize better, and handle completely new inputs more gracefully than brittle, rule-based systems ever could.
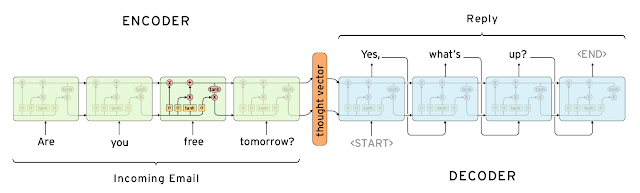 |
| Diagram by Chris Olah |
Like other sequence-to-sequence models, the Smart Reply System is built on a pair of
recurrent neural networks, one used to encode the incoming email and one to predict possible responses. The encoding network consumes the words of the incoming email one at a time, and produces a vector (a list of numbers). This vector, which Geoff Hinton calls a “
thought vector,” captures the gist of what is being said without getting hung up on diction -- for example, the vector for "Are you free tomorrow?" should be similar to the vector for "Does tomorrow work for you?" The second network starts from this thought vector and synthesizes a grammatically correct reply one word at a time, like it’s typing it out. Amazingly, the detailed operation of each network is entirely learned, just by training the model to predict likely responses.
One challenge of working with emails is that the inputs and outputs of the model can be hundreds of words long. This is where the particular choice of recurrent neural network type really matters. We used a variant of a "long short-term-memory" network (or
LSTM for short), which is particularly good at preserving long-term dependencies, and can home in on the part of the incoming email that is most useful in predicting a response, without being distracted by less relevant sentences before and after.
Of course, there's another very important factor in working with email, which is privacy. In developing Smart Reply we adhered to the same rigorous user privacy standards we’ve always held -- in other words, no humans reading your email. This means researchers have to get machine learning to work on a data set that they themselves cannot read, which is a little like trying to solve a puzzle while blindfolded -- but a challenge makes it more interesting!
Getting it right Our first prototype of the system had a few unexpected quirks. We wanted to generate a few candidate replies, but when we asked our neural network for the three most likely responses, it’d cough up triplets like “How about tomorrow?” “Wanna get together tomorrow?” “I suggest we meet tomorrow.” That’s not really much of a choice for users. The solution was provided by Sujith Ravi, whose team developed a great machine learning system for mapping natural language responses to semantic intents. This was instrumental in several phases of the project, and was critical to solving the "response diversity problem": by knowing how semantically similar two responses are, we can suggest responses that are different not only in wording, but in their underlying meaning.
Another bizarre feature of our early prototype was its propensity to respond with “I love you” to seemingly anything. As adorable as this sounds, it wasn’t really what we were hoping for. Some analysis revealed that the system was doing exactly what we’d trained it to do, generate likely responses -- and it turns out that responses like “Thanks", "Sounds good", and “I love you” are super common -- so the system would lean on them as a safe bet if it was unsure. Normalizing the likelihood of a candidate reply by some measure of that response's prior probability forced the model to predict responses that were not just highly likely, but also had high affinity to the original message. This made for a less lovey, but far more useful, email assistant.
Give it a tryWe’re actually pretty amazed at how well this works. We’ll be rolling this feature out on
Inbox for Android and iOS later this week, and we hope you’ll try it for yourself! Tap on a Smart Reply suggestion to start editing it. If it’s perfect as is, just tap send. Two-tap email on the go -- just like Bálint envisioned.
* This blog post may or may not have actually been written by a neural network.↩

















{kind=link}