Posted by Arif Sukoco, Android Studio Engineering Manager (@GoogArif) & Jolanda Verhoef, Developer Relations Engineer (@Lojanda)
We know it can be challenging to run Android instrumented tests at scale, especially when you have a big test suite that you want to run against a variety of Android device profiles.
At I/O 2021 we first introduced Unified Test Platform or UTP. UTP allows us to build testing features for Android instrumented tests such as running instrumented tests from Android Studio through Gradle, and Gradle Managed Devices (GMD). GMD allows you to define a set of virtual devices in build.gradle, and let Gradle manage them by spinning them up before each instrumented test run, and tearing them down afterwards. In the latest version of Android Gradle Plugin 7.2.0, we are introducing more features on top of GMD to help scale tests across multiple Android virtual devices in parallel.
Sharding
The first feature we are introducing is sharding on top of GMD. Sharding is a common technique used in test runners where the test runner splits up the tests into multiple groups, or shards, and runs them in parallel. With the ability to spin up multiple emulator instances in GMD, sharding is an obvious next step to make GMD a more scalable solution for large test suites.
When you enable sharding for GMD and specify the desired number of shards, it will automatically spin up that number of managed devices for you. For example, the sample below configures a Gradle Managed Devices called pixel2 in your build.gradle:
android {
testOptions {
devices {
pixel2 (com.android.build.api.dsl.ManagedVirtualDevice) {
device = "Pixel 2"
apiLevel = 30
systemImageSource = "google"
abi = "x86"
}
}
}
}
Let’s say you have 4 instrumented tests in your test suite. You can pass an experimental property to Gradle to specify how many shards you want to divide your tests in. The following command splits the test run into two shards:
./gradlew -Pandroid.experimental.androidTest.numManagedDeviceShards=2 pixel2DebugAndroidTest
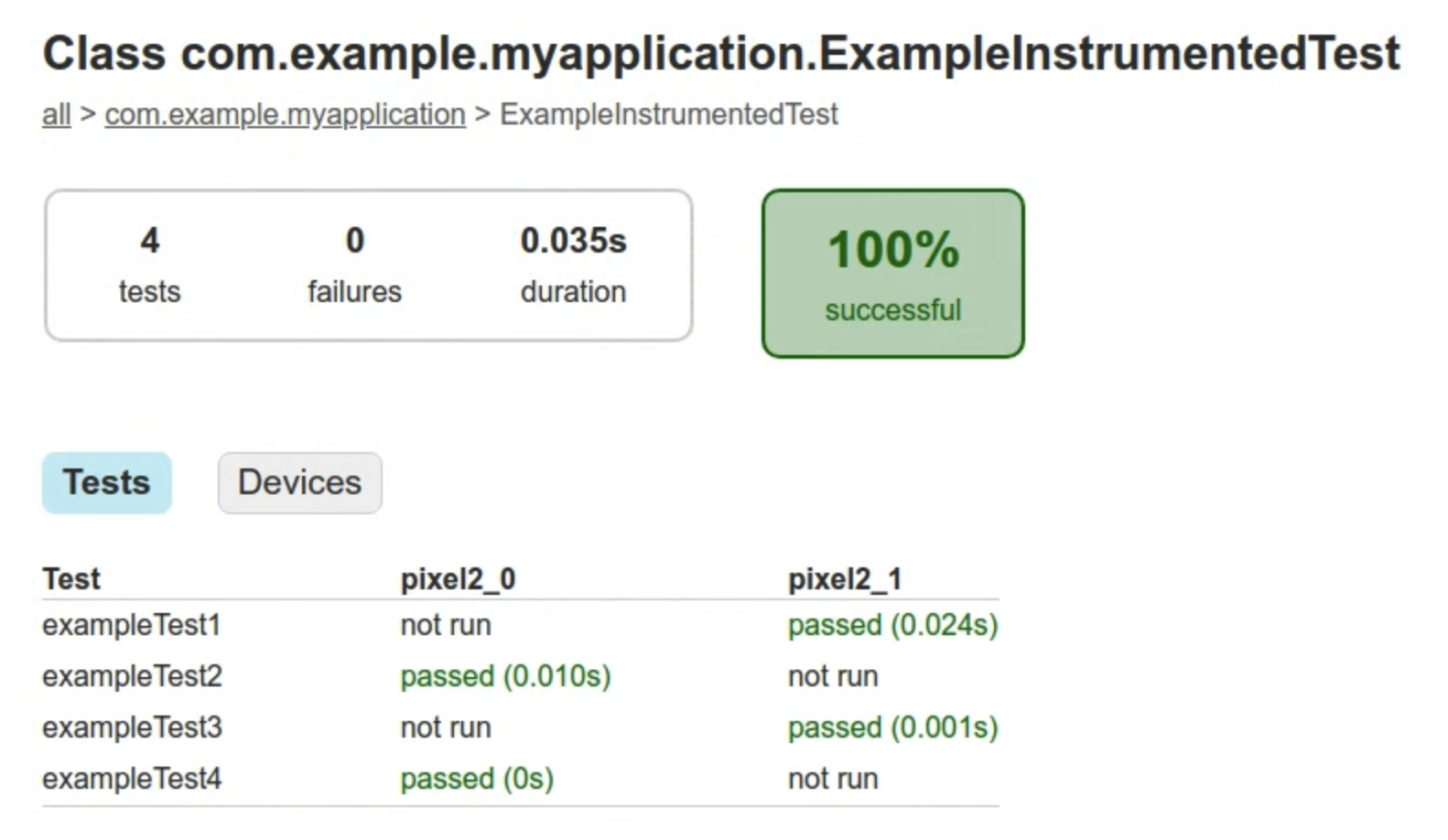
Invoking Gradle this way will tell GMD to spin up 2 instances of pixel2, and split the running of your 4 instrumented tests between those 2 emulated devices. In the Gradle output, you will see "Starting 2 tests on pixel2_0", and "Starting 2 tests on pixel2_1".
As seen in this example, sharding through GMD spins up multiple identical virtual devices. If you apply sharding and have more than one device defined in build.gradle, GMD will spin up multiple instances of each virtual device.
The HTML format output of your test run report will be generated in app/build/reports/androidTests/managedDevice/pixel2. This report will contain the combined test results from all the shards.
You can also load the test results from each shard to Android Studio by selecting Run > Import Tests From File from the menu and loading the protobuf output files app/build/outputs/androidTest-results/managedDevice/pixel2/shard_1/test-result.pb and app/build/outputs/androidTest-results/managedDevice/pixel2/shard_2/test-result.pb.
It’s worth remembering that when sharding your tests, there is always a tradeoff between the extra resources and time required to spin up additional emulator instances, and the savings in test running time. As such, it is more useful when you have larger test suites to run.
Also please note that currently GMD doesn’t support running tests for test-only modules yet, and there are known flakiness issues when running on cloud hosted CI servers.
Slimmer Emulator System Images
When running multiple emulator instances at the same time, your limited server’s computing resources could become an issue.
One of the ways to improve this is by slimming down the Android emulator system image to create a new type of device that’s optimized for running automated tests. The Automated Test Device (ATD) system image is designed to consume less CPU and memory by removing components that normally do not affect the running of your app’s instrumented tests, such as the SystemUI, Settings app, bundled apps like Gmail, Google Maps, etc., and some other components. Please read the release notes for more information about the ATD system image.
The ATD system images have hardware rendering disabled by default. This helps with another common source of slow-running test suites. Often, when running instrumented tests on an emulator, access to the host’s GPU for graphics hardware acceleration is not available. In this case, the emulator will choose to use software graphics acceleration, which is much more CPU intensive. Nearly all functionalities still work as expected with hardware rendering off, with the notable exception of screenshots. If you need to take screenshots in your test, we recommend taking a look at the new AndroidX Test Screenshot APIs which will dynamically enable hardware rendering in order to take a screenshot. Please take a look at the examples for how to use these APIs.
To use ATD, first make sure you have downloaded the latest version of the Android emulator from the Canary channel (version 30.9.2 or newer). To download this emulator, go to Appearance & Behavior > System Settings > Updates and set the IDE updates dropdown to “Canary Channel”.
Next, you need to specify an ATD system image in your GMD configuration:
android {
testOptions {
devices {
pixel2 (com.android.build.api.dsl.ManagedVirtualDevice) {
device = "Pixel 2"
apiLevel = 30
systemImageSource = "aosp-atd" // Or "google-atd" if you need
// access to Google APIs
abi = "x86" // Or "arm64-v8a" if you are on an Apple M1 machine
}
}
}
}
You can now run tests from the Gradle command line just like you would with GMD as before, including with sharding enabled. The only thing you need to add for now is to let Gradle know you are referring to a system image in the Canary channel.
./gradlew -Pandroid.sdk.channel=3
-Pandroid.experimental.androidTest.numManagedDeviceShards=2
pixel2DebugAndroidTest
Test running time improvement using ATD might vary, depending on your machine configuration. In our tests, comparing ATD and non-ATD system images running on a Linux machine with Intel Xeon CPU and 64GB of RAM, we saw 33% shorter test running time when using ATD, while on a 2020 Macbook Pro with Intel i9 processor and 32GB of RAM, we saw 55% improvement.
We’re really excited about these new features, and we hope they can allow you to better scale out your instrumented tests. Please try them out and let us know what you think! Follow us -- the Android Studio development team ‐ on Twitter and on Medium.





 Posted by Nevin Mital, Partner Developer Relations
Posted by Nevin Mital, Partner Developer Relations