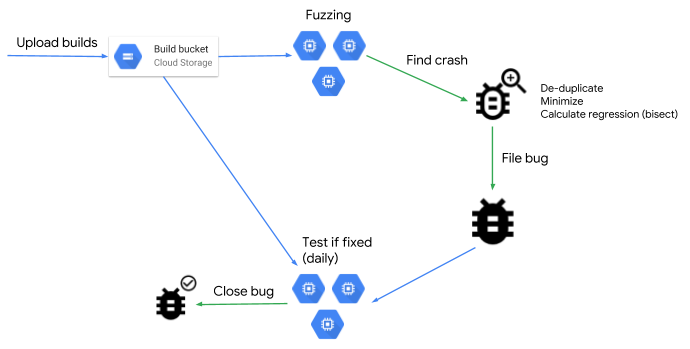
OSS-Fuzz, Google’s open source fuzzing service, now supports fuzzing applications written in Java and other Java Virtual Machine (JVM) based languages (e.g. Kotlin, Scala, etc.). Open source projects written in JVM based languages can add their project to OSS-Fuzz by following our documentation.
The Google Open Source Security team partnered with Code Intelligence to integrate their Jazzer fuzzer with OSS-Fuzz. Thanks to their integration, open source projects written in JVM-based languages can now use OSS-Fuzz for continuous fuzzing.
OSS-Fuzz has found more than 25,000 bugs in open source projects using fuzzing. We look forward to seeing how this technique can help secure and improve code written in JVM-based languages.
What can Jazzer do?
Jazzer allows users to fuzz code written in JVM-based languages with libFuzzer, as they already can for code written in C/C++. It does this by providing code coverage feedback from JVM bytecode to libFuzzer. Jazzer already supports important libFuzzer features such as:
Jazzer allows users to fuzz code written in JVM-based languages with libFuzzer, as they already can for code written in C/C++. It does this by providing code coverage feedback from JVM bytecode to libFuzzer. Jazzer already supports important libFuzzer features such as:
- FuzzedDataProvider for fuzzing code that doesn’t accept an array of bytes.
- Evaluation of code coverage based on 8-bit edge counters.
- Value profile.
- Minimization of crashing inputs.
What Does Jazzer Support?
Jazzer supports all languages that compile to JVM bytecode, since instrumentation is done on the bytecode level. This includes:
Jazzer supports all languages that compile to JVM bytecode, since instrumentation is done on the bytecode level. This includes:
- Java
- Kotlin
- Scala
- Clojure
Why Fuzz Java/JVM-based Code?
As discussed in our post on Atheris, fuzzing code written in memory safe languages, such as JVM-based languages, is useful for finding bugs where code behaves incorrectly or crashes. Incorrect behavior can be just as dangerous as memory corruption. For example, Jazzer was used to find CVE-2021-23899 in json-sanitizer which could be exploited for cross-site scripting (XSS). Bugs causing crashes or incorrect exceptions can sometimes be used for denial of service. For example, OSS-Fuzz recently found a denial of service issue that could have been used to take “a major part of the ethereum network offline”.
When fuzzing memory safe code, you can use the same classic approach for fuzzing memory unsafe code: passing mutated input to code and waiting for crashes. Or you can take a more unit test like approach where your fuzzer verifies that the code is behaving correctly (example).
Another way fuzzing can find interesting bugs in JVM-based code is through differential fuzzing. With differential fuzzing, your fuzzer passes mutated input from the fuzzer to multiple library implementations that should have the same functionality. Then it compares the results from each library to find differences.
Check out our documentation to get started. We will explore this more during our OSS-Fuzz talk at FuzzCon Europe.
As discussed in our post on Atheris, fuzzing code written in memory safe languages, such as JVM-based languages, is useful for finding bugs where code behaves incorrectly or crashes. Incorrect behavior can be just as dangerous as memory corruption. For example, Jazzer was used to find CVE-2021-23899 in json-sanitizer which could be exploited for cross-site scripting (XSS). Bugs causing crashes or incorrect exceptions can sometimes be used for denial of service. For example, OSS-Fuzz recently found a denial of service issue that could have been used to take “a major part of the ethereum network offline”.
When fuzzing memory safe code, you can use the same classic approach for fuzzing memory unsafe code: passing mutated input to code and waiting for crashes. Or you can take a more unit test like approach where your fuzzer verifies that the code is behaving correctly (example).
Another way fuzzing can find interesting bugs in JVM-based code is through differential fuzzing. With differential fuzzing, your fuzzer passes mutated input from the fuzzer to multiple library implementations that should have the same functionality. Then it compares the results from each library to find differences.
Check out our documentation to get started. We will explore this more during our OSS-Fuzz talk at FuzzCon Europe.