 Posted by Thomas Ezan – Sr Developer Relation Engineer (@lethargicpanda)
Posted by Thomas Ezan – Sr Developer Relation Engineer (@lethargicpanda)
We're excited to announce Gaze Link as the winner of the Best Android App for our Gemini API Developer Competition!
This innovative app demonstrates the potential of the Gemini API in providing a communication system for individuals with Amyotrophic lateral sclerosis (ALS) who develop severe motor and verbal disabilities, enabling them to type sentences with only their eyes.
About Gaze Link
Gaze Link uses Google’s Gemini 1.5 Flash model to predict the user’s intended sentence based on a few key words and the context of the conversation.
For example if the context is “Is the room temperature ok?” and the user replies “hot AC two” the app will leverage Gemini to generate the full sentence “I am hot, can you turn the AC down by two degrees?”.
The Gaze Link team took advantage of Gemini 1.5 Flash multilingual capabilities to let the app generate sentences in English, Spanish and Chinese, the three languages currently supported by the app.
We were truly impressed by the Gaze Link app. The team used the Gemini API combined with ML Kit Face Detection to empower individuals with ALS providing them with a powerful communication system that is both accessible and affordable.
With Gemini 1.5 Flash currently supporting 38 languages, it is possible for Gaze Link to add support for more languages in the future. In addition, the model’s multimodal abilities could enable the team to enhance the user experience by integrating image, audio and video to augment the context of the conversation.
Build with the Gemini API
The result of the integration of the Gemini API in Gaze Link is inspiring. If you are working on an Android app today, we encourage you to learn about the Gemini API capabilities to see how you can successfully add generative AI to your app and delight your users.
To get started, go to the Android AI documentation!
 We’re working with leaders in the fashion industry to bring product inclusion and equity to New York Fashion Week.
We’re working with leaders in the fashion industry to bring product inclusion and equity to New York Fashion Week.


 Fatmir Seremeti made history as the first visually impaired runner to complete the Stockholm Half Marathon using Google's Project Guideline, showcasing the power of AI i…
Fatmir Seremeti made history as the first visually impaired runner to complete the Stockholm Half Marathon using Google's Project Guideline, showcasing the power of AI i…
 These new AI-powered features across Pixel and Android help make the world even more accessible.
These new AI-powered features across Pixel and Android help make the world even more accessible.

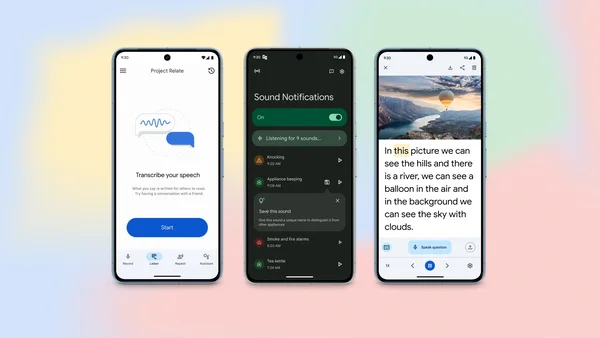 For Global Accessibility Awareness Day, here’s new updates to our accessibility products.
For Global Accessibility Awareness Day, here’s new updates to our accessibility products.
 We’re excited to announce the Google Rising Influencers with Disabilities Program, a first of its kind program to support people with disabilities.
We’re excited to announce the Google Rising Influencers with Disabilities Program, a first of its kind program to support people with disabilities.
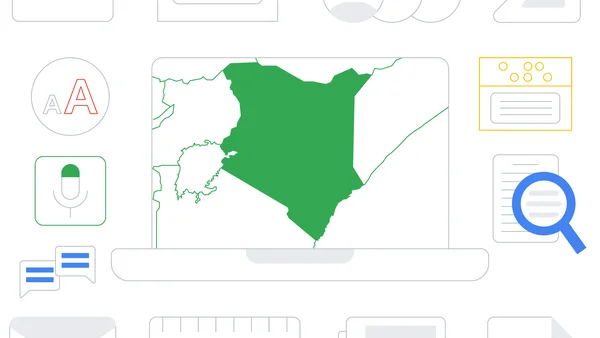 Read about our partnerships in Kenya that bring Chromebooks to low vision and blind children, and learn more about new Chromebook updates for Global Accessibility Awaren…
Read about our partnerships in Kenya that bring Chromebooks to low vision and blind children, and learn more about new Chromebook updates for Global Accessibility Awaren…