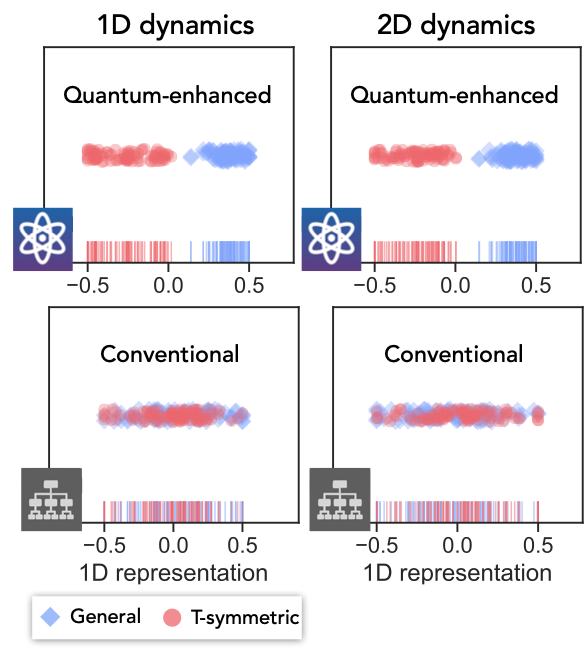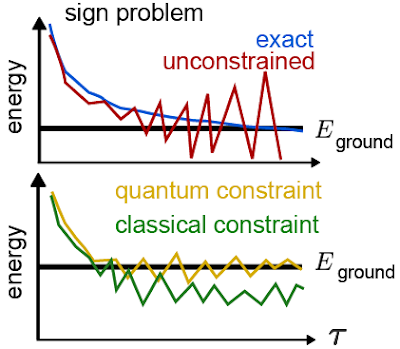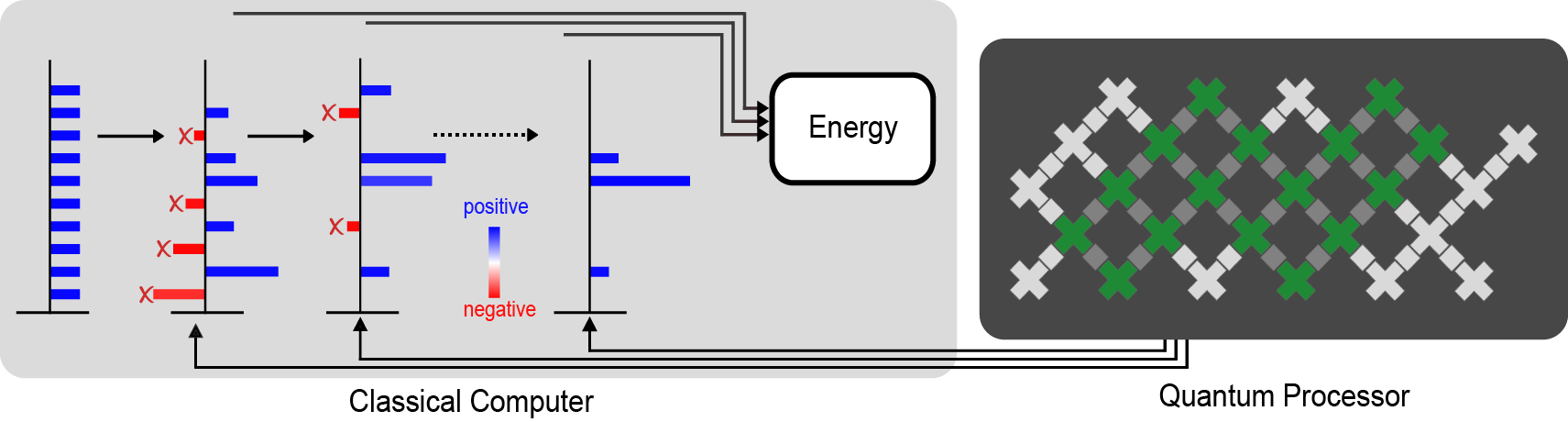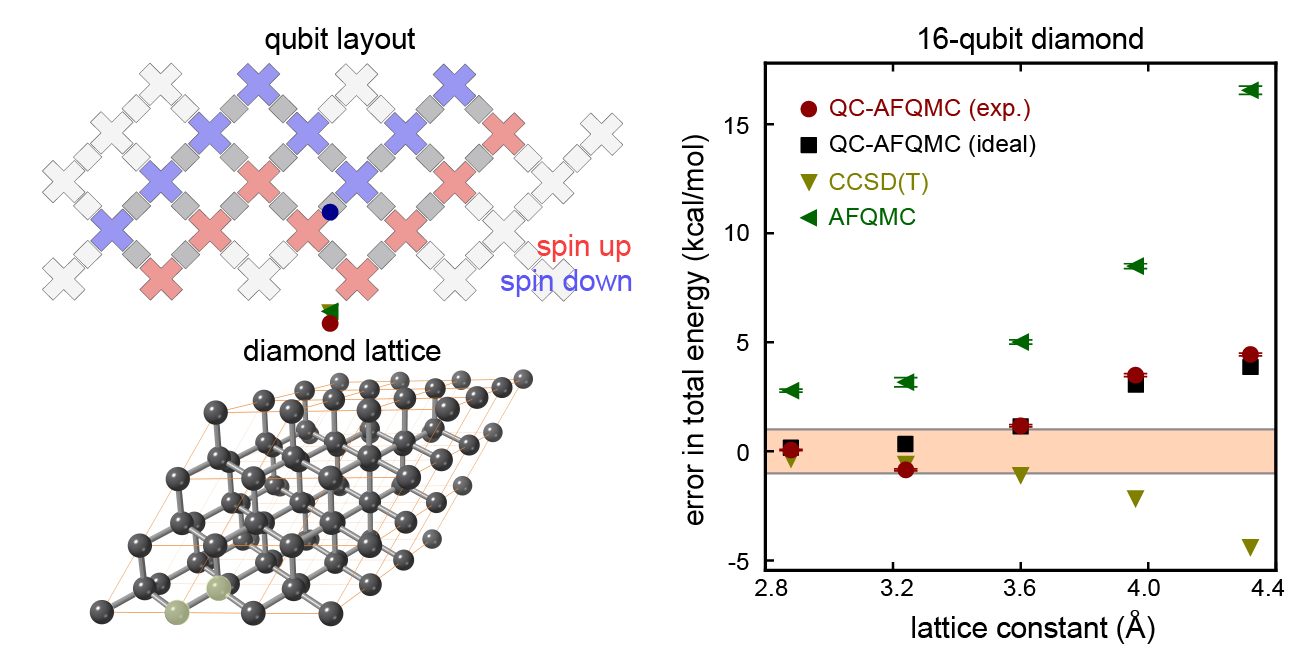
When quantum computers were first proposed, they were hoped to be a way to better understand the quantum world. With a so-called “quantum simulator,” one could engineer a quantum computer to investigate how various quantum phenomena arise, including those that are intractable to simulate with a classical computer.
But making a useful quantum simulator has been a challenge. Until now, quantum simulations with superconducting qubits have predominantly been used to verify pre-existing theoretical predictions and have rarely explored or discovered new phenomena. Only a few experiments with trapped ions or cold atoms have revealed new insights. Superconducting qubits, even though they are one of the main candidates for universal quantum computing and have demonstrated computational capabilities beyond classical reach, have so far not delivered on their potential for discovery.
In “Formation of Robust Bound States of Interacting Photons”, published in Nature, we describe a previously unpredicted phenomenon first discovered through experimental investigation. First, we present the experimental confirmation of the theoretical prediction of the existence of a composite particle of interacting photons, or a bound state, using the Google Sycamore quantum processor. Second, while studying this system, we discovered that even though one might guess the bound states to be fragile, they remain robust to perturbations that we expected to have otherwise destroyed them. Not only does this open the possibility of designing systems that leverage interactions between photons, it also marks a step forward in the use of superconducting quantum processors to make new scientific discoveries by simulating non-equilibrium quantum dynamics.
Overview
Photons, or quanta of electromagnetic radiation like light and microwaves, typically don’t interact. For example, two intersecting flashlight beams will pass through one another undisturbed. In many applications, like telecommunications, the weak interactions of photons is a valuable feature. For other applications, such as computers based on light, the lack of interactions between photons is a shortcoming.
In a quantum processor, the qubits host microwave photons, which can be made to interact through two-qubit operations. This allows us to simulate the XXZ model, which describes the behavior of interacting photons. Importantly, this is one of the few examples of integrable models, i.e., one with a high degree of symmetry, which greatly reduces its complexity. When we implement the XXZ model on the Sycamore processor, we observe something striking: the interactions force the photons into bundles known as bound states.
Using this well-understood model as a starting point, we then push the study into a less-understood regime. We break the high level of symmetries displayed in the XXZ model by adding extra sites that can be occupied by the photons, making the system no longer integrable. While this nonintegrable regime is expected to exhibit chaotic behavior where bound states dissolve into their usual, solitary selves, we instead find that they survive!
Bound Photons
To engineer a system that can support the formation of bound states, we study a ring of superconducting qubits that host microwave photons. If a photon is present, the value of the qubit is “1”, and if not, the value is “0”. Through the so-called “fSim” quantum gate, we connect neighboring sites, allowing the photons to hop around and interact with other photons on the nearest-neighboring sites.
 |
| Superconducting qubits can be occupied or unoccupied with microwave photons. The “fSim” gate operation allows photons to hop and interact with each other. The corresponding unitary evolution has a hopping term between two sites (orange) and an interaction term corresponding to an added phase when two adjacent sites are occupied by a photon. |
 |
| We implement the fSim gate between neighboring qubits (left) to effectively form a ring of 24 interconnected qubits on which we simulate the behavior of the interacting photons (right). |
The interactions between the photons affect their so-called “phase.” This phase keeps track of the oscillation of the photon’s wavefunction. When the photons are non-interacting, their phase accumulation is rather uninteresting. Like a well-rehearsed choir, they’re all in sync with one another. In this case, a photon that was initially next to another photon can hop away from its neighbor without getting out of sync. Just as every person in the choir contributes to the song, every possible path the photon can take contributes to the photon’s overall wavefunction. A group of photons initially clustered on neighboring sites will evolve into a superposition of all possible paths each photon might have taken.
When photons interact with their neighbors, this is no longer the case. If one photon hops away from its neighbor, its rate of phase accumulation changes, becoming out of sync with its neighbors. All paths in which the photons split apart overlap, leading to destructive interference. It would be like each choir member singing at their own pace — the song itself gets washed out, becoming impossible to discern through the din of the individual singers. Among all the possible configuration paths, the only possible scenario that survives is the configuration in which all photons remain clustered together in a bound state. This is why interaction can enhance and lead to the formation of a bound state: by suppressing all other possibilities in which photons are not bound together.
 |
| Left: Evolution of interacting photons forming a bound state. Right: Time goes from left to right, each path represents one of the paths that can break the 2-photon bonded state. Due to interactions, these paths interfere destructively, preventing the photons from splitting apart. |
 |
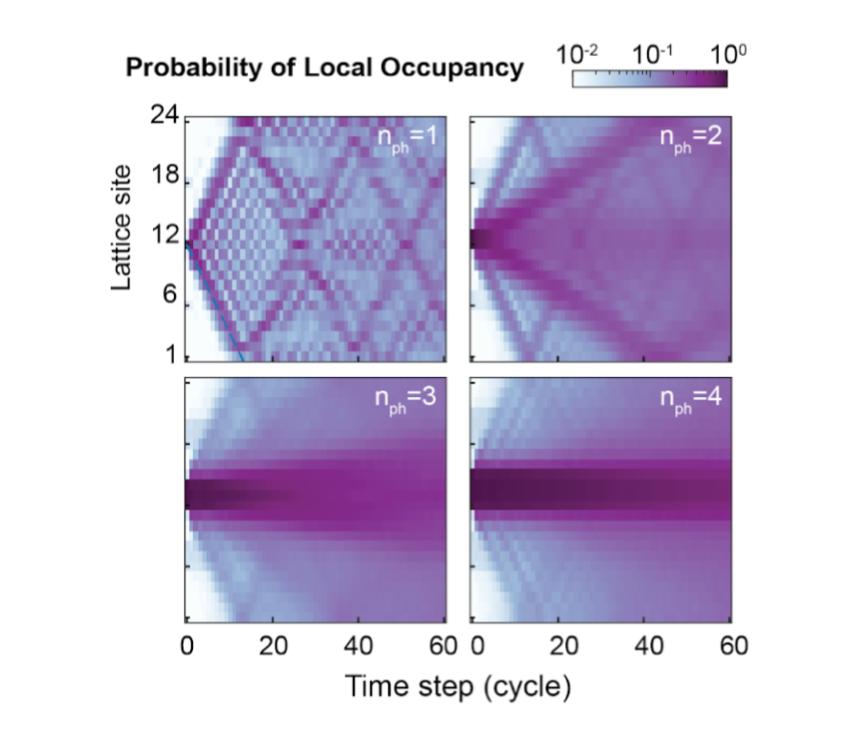
| Occupation probability versus gate cycle, or discrete time step, for n-photon bound states. We prepare bound states of varying sizes and watch them evolve. We observe that the majority of the photons (darker colors) remain bound together. |
In our processor, we start by putting two to five photons on adjacent sites (i.e., initializing two to five adjacent qubits in “1”, and the remaining qubits in “0”), and then study how they propagate. First, we notice that in the theoretically predicted parameter regime, they remain stuck together. Next, we find that the larger bound states move more slowly around the ring, consistent with the fact that they are “heavier”. This can be seen in the plot above where the lattice sites closest to Site 12, the initial position of the photons, remain darker than the others with increasing number of photons (nph) in the bound state, indicating that with more photons bound together there is less propagation around the ring.
Bound States Behave Like Single Composite Particles
To more rigorously show that the bound states indeed behave as single particles with well-defined physical properties, we devise a method to measure how the energy of the particles changes with momentum, i.e., the energy-momentum dispersion relation.
To measure the energy of the bound state, we use the fact that the energy difference between two states determines how fast their relative phase grows with time. Hence, we prepare the bound state in a superposition with the state that has no photons, and measure their phase difference as a function of time and space. Then, to convert the result of this measurement to a dispersion relation, we utilize a Fourier transform, which translates position and time into momentum and energy, respectively. We’re left with the familiar energy-momentum relationship of excitations in a lattice.
 |
| Spectroscopy of bound states. We compare the phase accumulation of an n-photon bound state with that of the vacuum (no photons) as a function of lattice site and time. A 2D Fourier transform yields the dispersion relation of the bound-state quasiparticle. |
Breaking Integrability
The above system is “integrable,” meaning that it has a sufficient number of conserved quantities that its dynamics are constrained to a small part of the available computational space. In such integrable regimes, the appearance of bound states is not that surprising. In fact, bound states in similar systems were predicted in 2012, then observed in 2013. However, these bound states are fragile and their existence is usually thought to derive from integrability. For more complex systems, there is less symmetry and integrability is quickly lost. Our initial idea was to probe how these bound states disappear as we break integrability to better understand their rigidity.
To break integrability, we modify which qubits are connected with fSim gates. We add qubits so that at alternating sites, in addition to hopping to each of its two nearest-neighboring sites, a photon can also hop to a third site oriented radially outward from the ring.
While a bound state is constrained to a very small part of phase space, we expected that the chaotic behavior associated with integrability breaking would allow the system to explore the phase space more freely. This would cause the bound states to break apart. We find that this is not the case. Even when the integrability breaking is so strong that the photons are equally likely to hop to the third site as they are to hop to either of the two adjacent ring sites, the bound state remains intact, up to the decoherence effect that makes them slowly decay (see paper for details).
 |
| Top: New geometry to break integrability. Alternating sites are connected to a third site oriented radially outward. This increases the complexity of the system, and allows for potentially chaotic behavior. Bottom: Despite this added complexity pushing the system beyond integrability, we find that the 3-photon bound state remains stable even for a relatively large perturbation. The probability of remaining bound decreases slowly due to decoherence (see paper). |
Conclusion
We don’t yet have a satisfying explanation for this unexpected resilience. We speculate that it may be related to a phenomenon called prethermalization, where incommensurate energy scales in the system can prevent a system from reaching thermal equilibrium as quickly as it otherwise would. We believe further investigations will hopefully lead to new insights into many-body quantum physics, including the interplay of prethermalization and integrability.
Acknowledgements
We would like to thank our Quantum Science Communicator Katherine McCormick for her help writing this blog post.
-buffer.jpg)