Mechanical ventilators provide critical support for patients who have difficulty breathing or are unable to breathe on their own. They see frequent use in scenarios ranging from routine anesthesia, to neonatal intensive care and life support during the COVID-19 pandemic. A typical ventilator consists of a compressed air source, valves to control the flow of air into and out of the lungs, and a "respiratory circuit" that connects the ventilator to the patient. In some cases, a sedated patient may be connected to the ventilator via a tube inserted through the trachea to their lungs, a process called invasive ventilation.
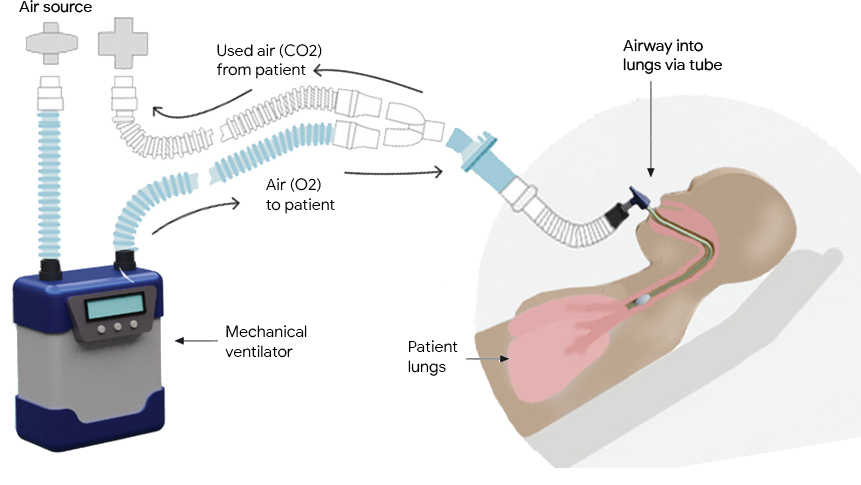 |
| A mechanical ventilator takes breaths for patients who are not fully capable of doing so on their own. In invasive ventilation, a controllable, compressed air source is connected to a sedated patient via tubing called a respiratory circuit. |
In both invasive and non-invasive ventilation, the ventilator follows a clinician-prescribed breathing waveform based on a respiratory measurement from the patient (e.g., airway pressure, tidal volume). In order to prevent harm, this demanding task requires both robustness to differences or changes in patients' lungs and adherence to the desired waveform. Consequently, ventilators require significant attention from highly-trained clinicians in order to ensure that their performance matches the patients’ needs and that they do not cause lung damage.
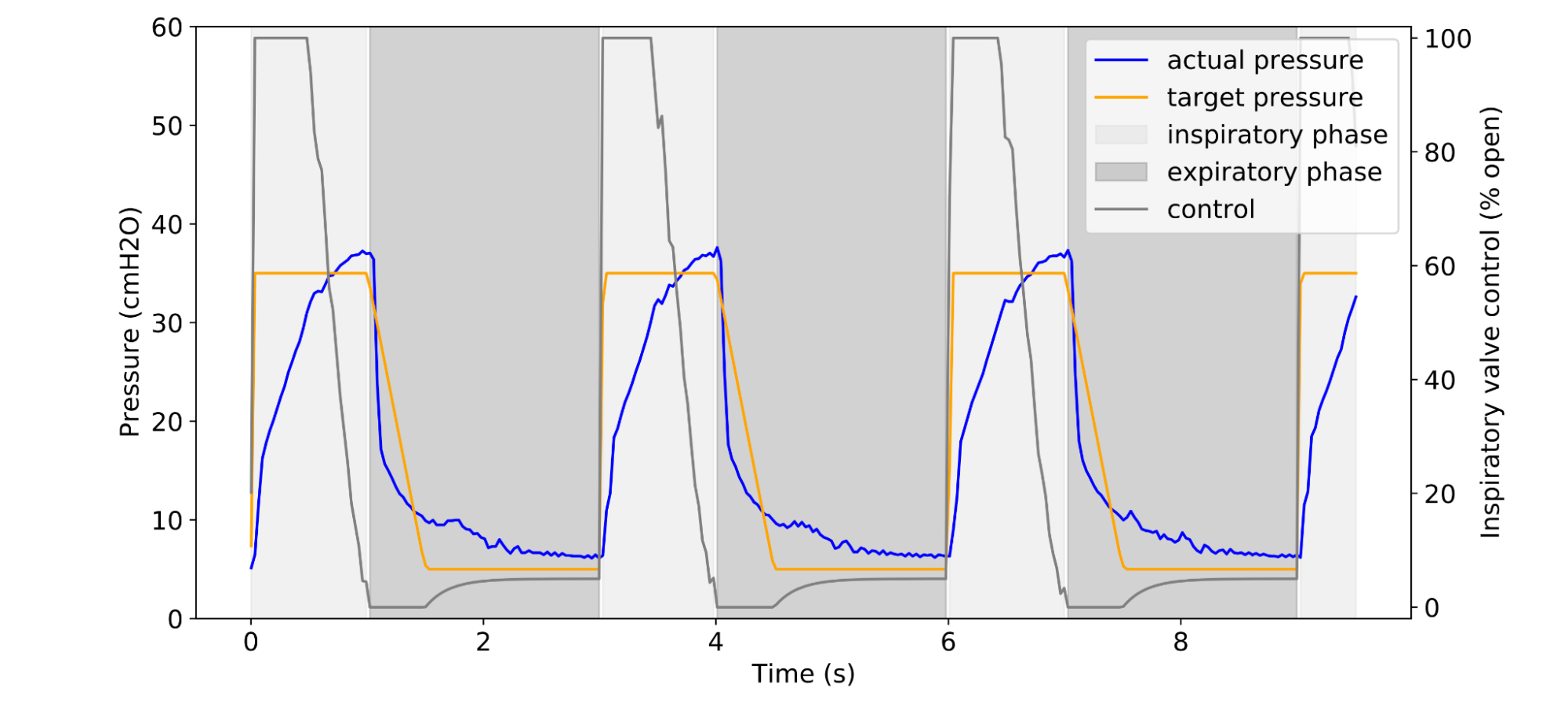 |
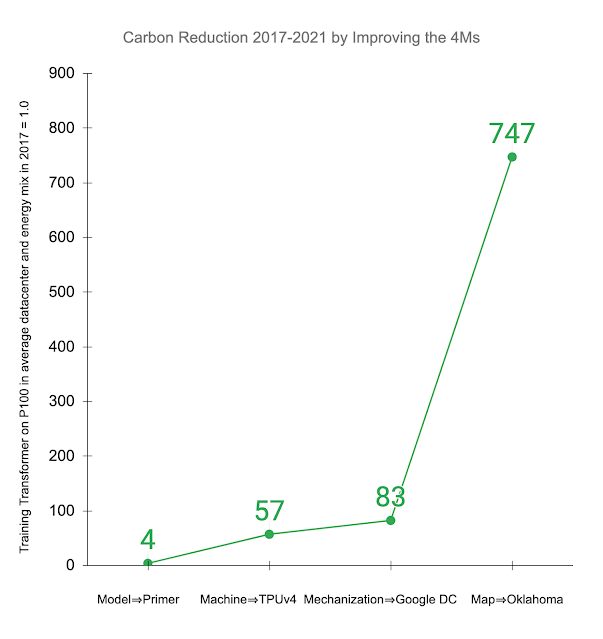
| Example of a clinician-prescribed breathing waveform (orange) in units of airway pressure and the actual pressure (blue), given some controller algorithm. |
In “Machine Learning for Mechanical Ventilation Control”, we present exploratory research into the design of a deep learning–based algorithm to improve medical ventilator control for invasive ventilation. Using signals from an artificial lung, we design a control algorithm that measures airway pressure and computes necessary adjustments to the airflow to better and more consistently match prescribed values. Compared to other approaches, we demonstrate improved robustness and better performance while requiring less manual intervention from clinicians, which suggests that this approach could reduce the likelihood of harm to a patient’s lungs.
Current Methods
Today, ventilators are controlled with methods belonging to the PID family (i.e., Proportional, Integral, Differential), which control a system based on the history of errors between the observed and desired states. A PID controller uses three characteristics for ventilator control: proportion (“P”) — a comparison of the measured and target pressure; integral (“I”) — the sum of previous measurements; and differential (“D”) — the difference between two previous measurements. Variants of PID have been used since the 17th century and today form the basis of many controllers in both industrial (e.g., controlling heat or fluids) and consumer (e.g., controlling espresso pressure) applications.
PID control forms a solid baseline, relying on the sharp reactivity of P control to rapidly increase lung pressure when breathing in and the stability of I control to hold the breath in before exhaling. However, operators must tune the ventilator for specific patients, often repeatedly, to balance the “ringing” of overzealous P control against the ineffectually slow rise in lung pressure of dominant I control.
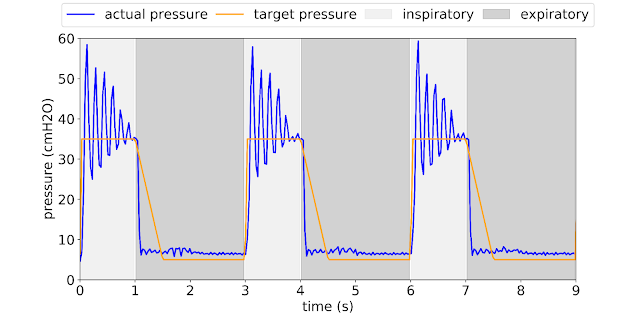 |
| Current PID methods are prone to over- and then under-shooting their target (ringing). Because patients differ in their physiology and may even change during treatment, highly-trained clinicians must constantly monitor and adjust existing methods to ensure such violent ringing as in the above example does not occur. |
To more effectively balance these characteristics, we propose a neural network–based controller to create a set of control signals that are more broad and adaptable than PID-generated controls.
A Machine-Learned Ventilator Controller
While one could tune the coefficients of a PID controller (either manually or via an exhaustive grid search) through a limited number of repeated trials, it is impossible to apply such a direct approach towards a deep controller, as deep neural networks (DNNs) are often parameter-rich and require significant training data. Similarly, popular model-free approaches, such as Q-Learning or Policy Gradient, are data-intensive and therefore unsuitable for the physical system at hand. Further, these approaches don't take into account the intrinsic differentiability of the ventilator dynamical system, which is deterministic, continuous and contact-free.
We therefore adopt a model-based approach, where we first learn a DNN-based simulator of the ventilator-patient dynamical system. An advantage of learning such a simulator is that it provides a more accurate data-driven alternative to physics-based models, and can be more widely distributed for controller research.
To train a faithful simulator, we built a dataset by exploring the space of controls and the resulting pressures, while balancing against physical safety, e.g., not over-inflating a test lung and causing damage. Though PID control can exhibit ringing behavior, it performs well enough to use as a baseline for generating training data. To safely explore and to faithfully capture the behavior of the system, we use PID controllers with varied control coefficients to generate the control-pressure trajectory data for simulator training. Further, we add random deviations to the PID controllers to capture the dynamics more robustly.
We collect data for training by running mechanical ventilation tasks on a physical test lung using an open-source ventilator designed by Princeton University's People's Ventilator Project. We built a ventilator farm housing ten ventilator-lung systems on a server rack, which captures multiple airway resistance and compliance settings that span a spectrum of patient lung conditions, as required for practical applications of ventilator systems.
 |
| We use a rack-based ventilator farm (10 ventilators / artificial lungs) to collect training data for a ventilator-lung simulator. Using this simulator, we train a DNN controller that we then validate on the physical ventilator farm. |
The true underlying state of the dynamical system is not available to the model directly, but rather only through observations of the airway pressure in the system. In the simulator we model the state of the system at any time as a collection of previous pressure observations and the control actions applied to the system (up to a limited lookback window). These inputs are fed into a DNN that predicts the subsequent pressure in the system. We train this simulator on the control-pressure trajectory data collected through interactions with the test lung.
The performance of the simulator is measured via the sum of deviations of the simulator’s predictions (under self-simulation) from the ground truth.
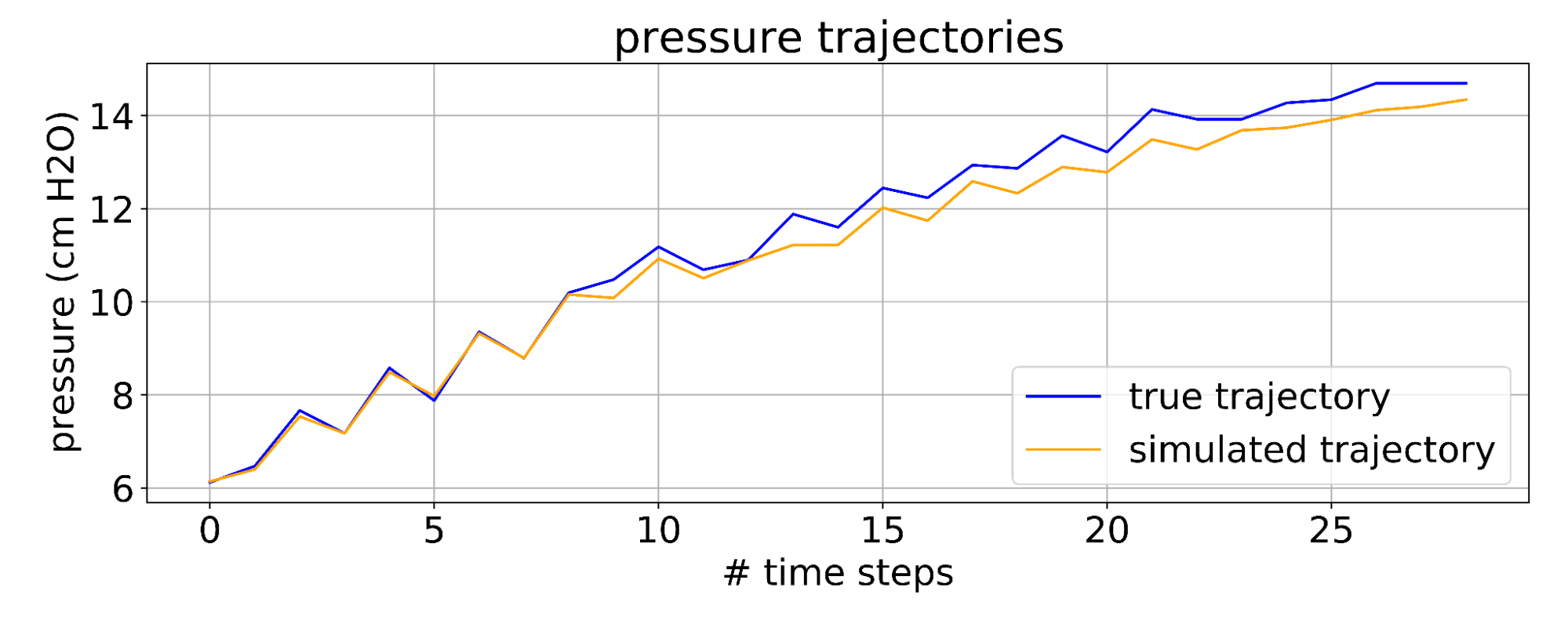 |
| While it is infeasible to compare real dynamics with their simulated counterparts over all possible trajectories and control inputs, we measure the distance between simulation and the known safe trajectories. We introduce some random exploration around these safe trajectories for robustness. |
Having learned an accurate simulator, we then use it to train a DNN-based controller completely offline. This approach allows us to rapidly apply updates during controller training. Furthermore, the differentiable nature of the simulator allows for the stable use of the direct policy gradient, where we analytically compute the gradient of the loss with respect to the DNN parameters. We find this method to be significantly more efficient than model-free approaches.
Results
To establish a baseline, we run an exhaustive grid of PID controllers for multiple lung settings and select the best performing PID controller as measured by average absolute deviation between the desired pressure waveform and the actual pressure waveform. We compare these to our controllers and provide evidence that our DNN controllers are better performing and more robust.
- Breathing waveform tracking performance:
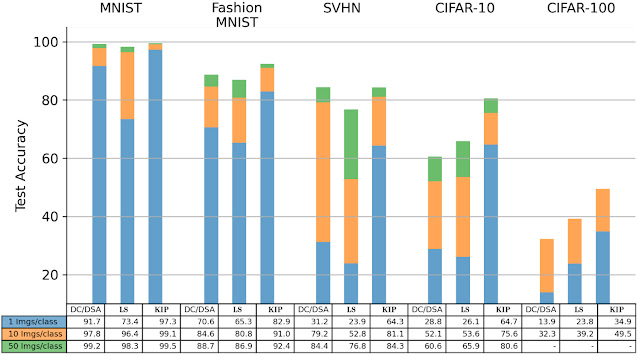
We compare the best PID controller for a given lung setting against our controller trained on the learned simulator for the same setting. Our learned controller shows a 22% lower mean absolute error (MAE) between target and actual pressure waveforms.
Comparison of the MAE between target and actual pressure waveforms (lower is better) for the best PID controller (orange) for a given lung setting (shown for two settings, R=5 and R=20) against our controller (blue) trained on the learned simulator for the same setting. The learned controller performs up to 22% better. - Robustness:
Further, we compare the performance of the single best PID controller across the entire set of lung settings with our controller trained on a set of learned simulators over the same settings. Our controller performs up to 32% better in MAE between target and actual pressure waveforms, suggesting that it could require less manual intervention between patients or even as a patient's condition changes.
As above, but comparing the single best PID controller across the entire set of lung settings against our controller trained over the same settings. The learned controller performs up to 32% better, suggesting that it may require less manual intervention.


Finally, we investigated the feasibility of using model-free and other popular RL algorithms (PPO, DQN), in comparison to a direct policy gradient trained on the simulator. We find that the simulator-trained direct policy gradient achieves slightly better scores and does so with a more stable training process that uses orders of magnitude fewer training samples and a significantly smaller hyperparameter search space.
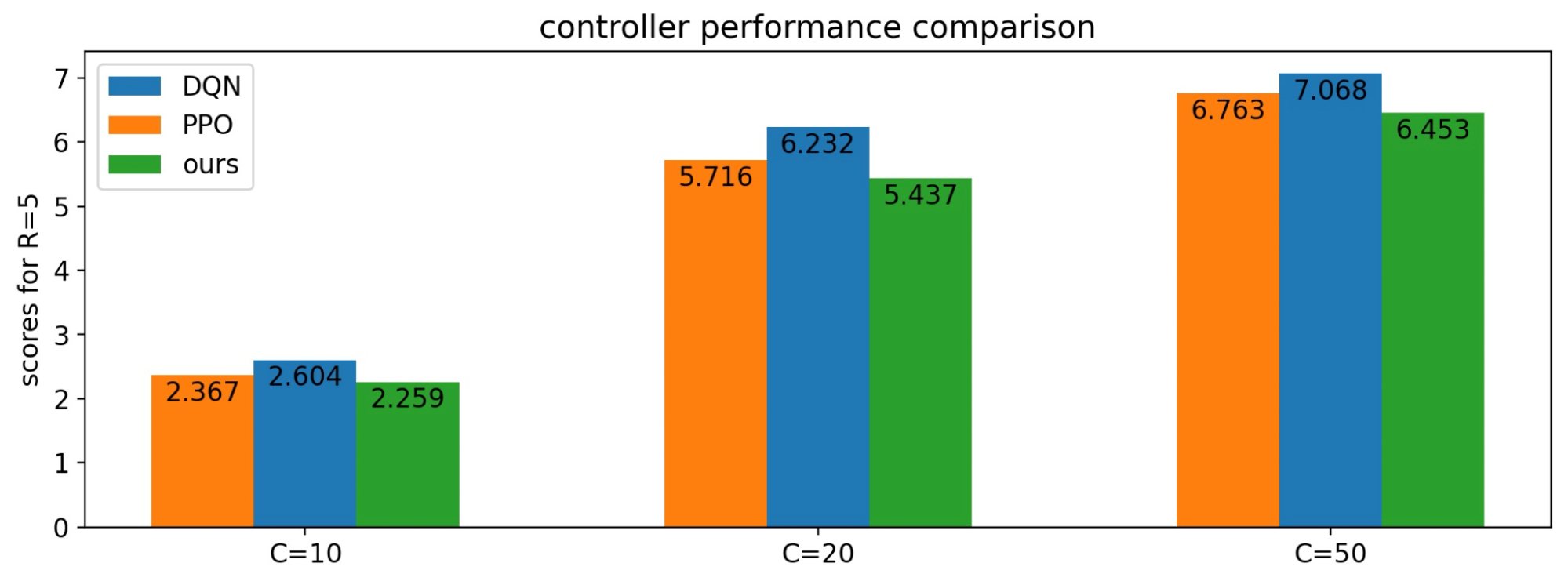 |
| In the simulator, we find that model-free and other popular algorithms (PPO, DQN) perform approximately as well as our method. |
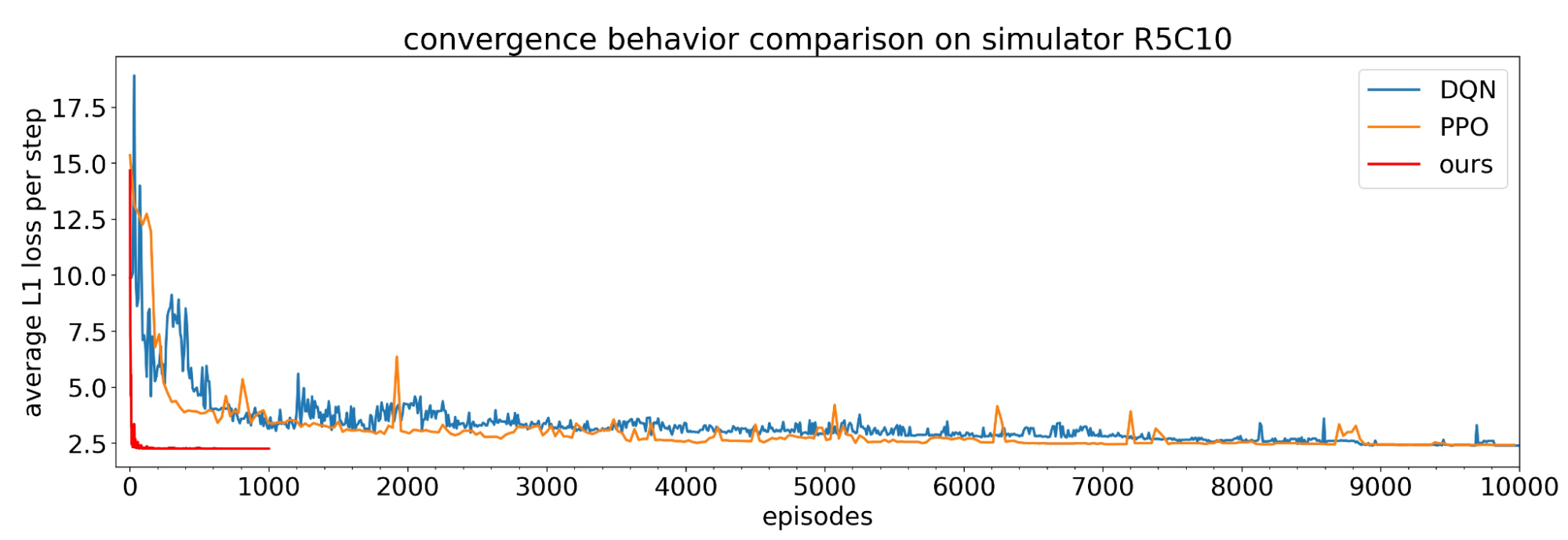 |
| However, these other methods take an order of magnitude more episodes to train to similar levels. |
Conclusions and the Road Forward
We have described a deep-learning approach to mechanical ventilation based on simulated dynamics learned from a physical test lung. However, this is only the beginning. To make an impact on real-world ventilators there are numerous other considerations and issues to take into account. Most important amongst them are non-invasive ventilators, which are significantly more challenging due to the difficulty of discerning pressure from lungs and mask pressure. Other directions are how to handle spontaneous breathing and coughing. To learn more and become involved in this important intersection of machine learning and health, see an ICML tutorial on control theory and learning, and consider participating in one of our kaggle competitions for creating better ventilator simulators!
Acknowledgements
The primary work was based in the Google AI Princeton lab, in collaboration with Cohen lab at the Mechanical and Aerospace Engineering department at Princeton University. The research paper was authored by contributors from Google and Princeton University, including: Daniel Suo, Naman Agarwal, Wenhan Xia, Xinyi Chen, Udaya Ghai, Alexander Yu, Paula Gradu, Karan Singh, Cyril Zhang, Edgar Minasyan, Julienne LaChance, Tom Zajdel, Manuel Schottdorf, Daniel Cohen, and Elad Hazan.