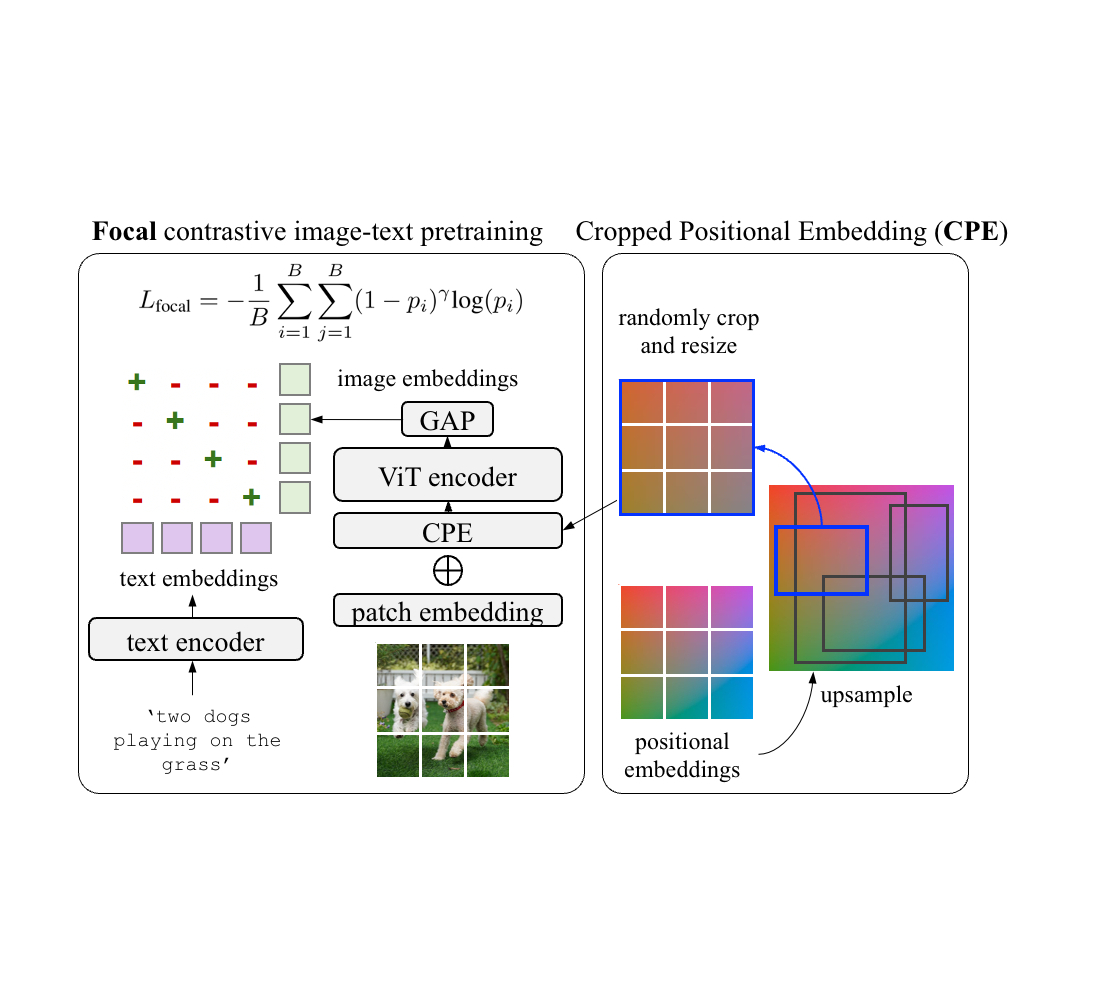
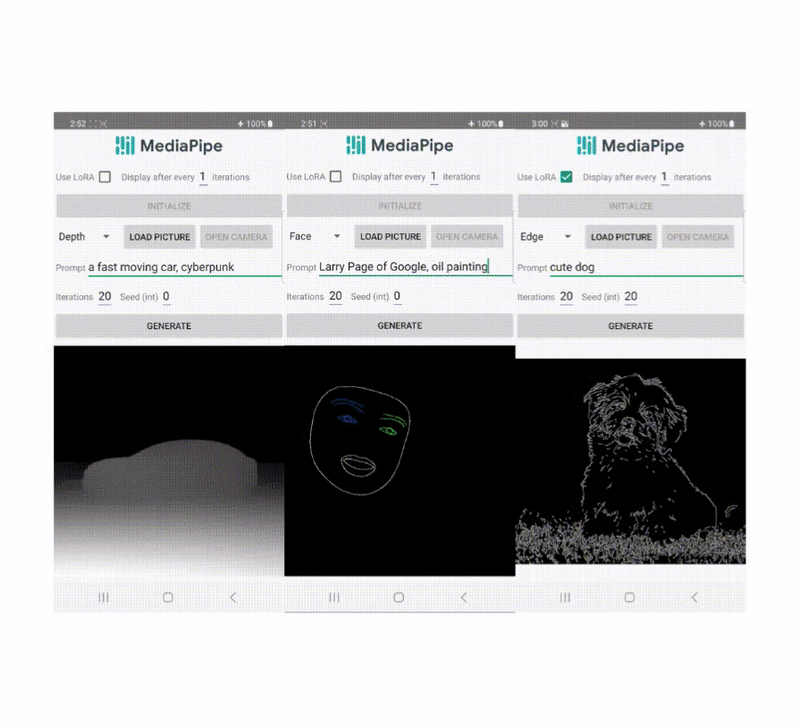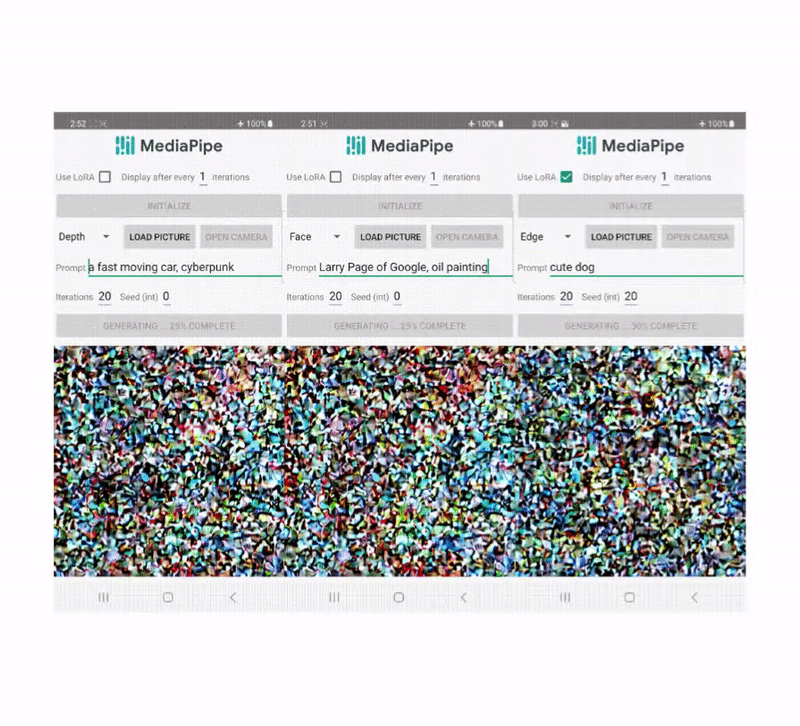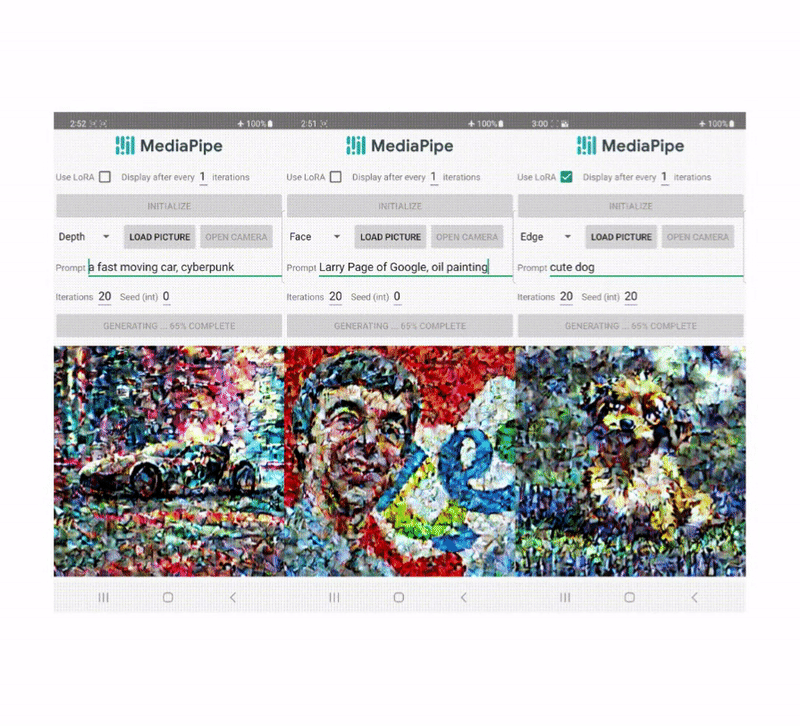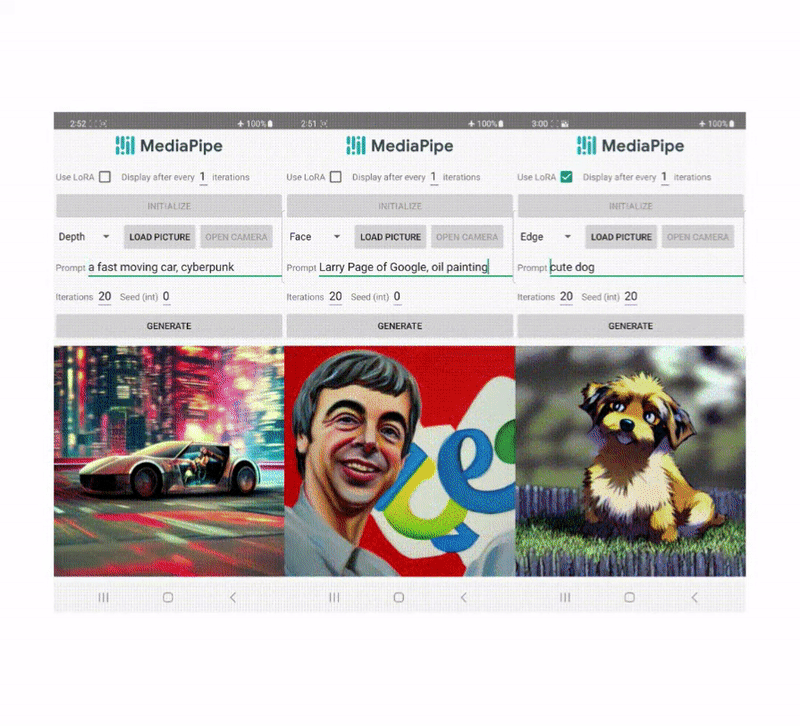
In recent years, we have witnessed rising interest across consumers and researchers in integrated augmented reality (AR) experiences using real-time face feature generation and editing functions in mobile applications, including short videos, virtual reality, and gaming. As a result, there is a growing demand for lightweight, yet high-quality face generation and editing models, which are often based on generative adversarial network (GAN) techniques. However, the majority of GAN models suffer from high computational complexity and the need for a large training dataset. In addition, it is also important to employ GAN models responsibly.
In this post, we introduce MediaPipe FaceStylizer, an efficient design for few-shot face stylization that addresses the aforementioned model complexity and data efficiency challenges while being guided by Google’s responsible AI Principles. The model consists of a face generator and a face encoder used as GAN inversion to map the image into latent code for the generator. We introduce a mobile-friendly synthesis network for the face generator with an auxiliary head that converts features to RGB at each level of the generator to generate high quality images from coarse to fine granularities. We also carefully designed the loss functions for the aforementioned auxiliary heads and combined them with the common GAN loss functions to distill the student generator from the teacher StyleGAN model, resulting in a lightweight model that maintains high generation quality. The proposed solution is available in open source through MediaPipe. Users can fine-tune the generator to learn a style from one or a few images using MediaPipe Model Maker, and deploy to on-device face stylization applications with the customized model using MediaPipe FaceStylizer.
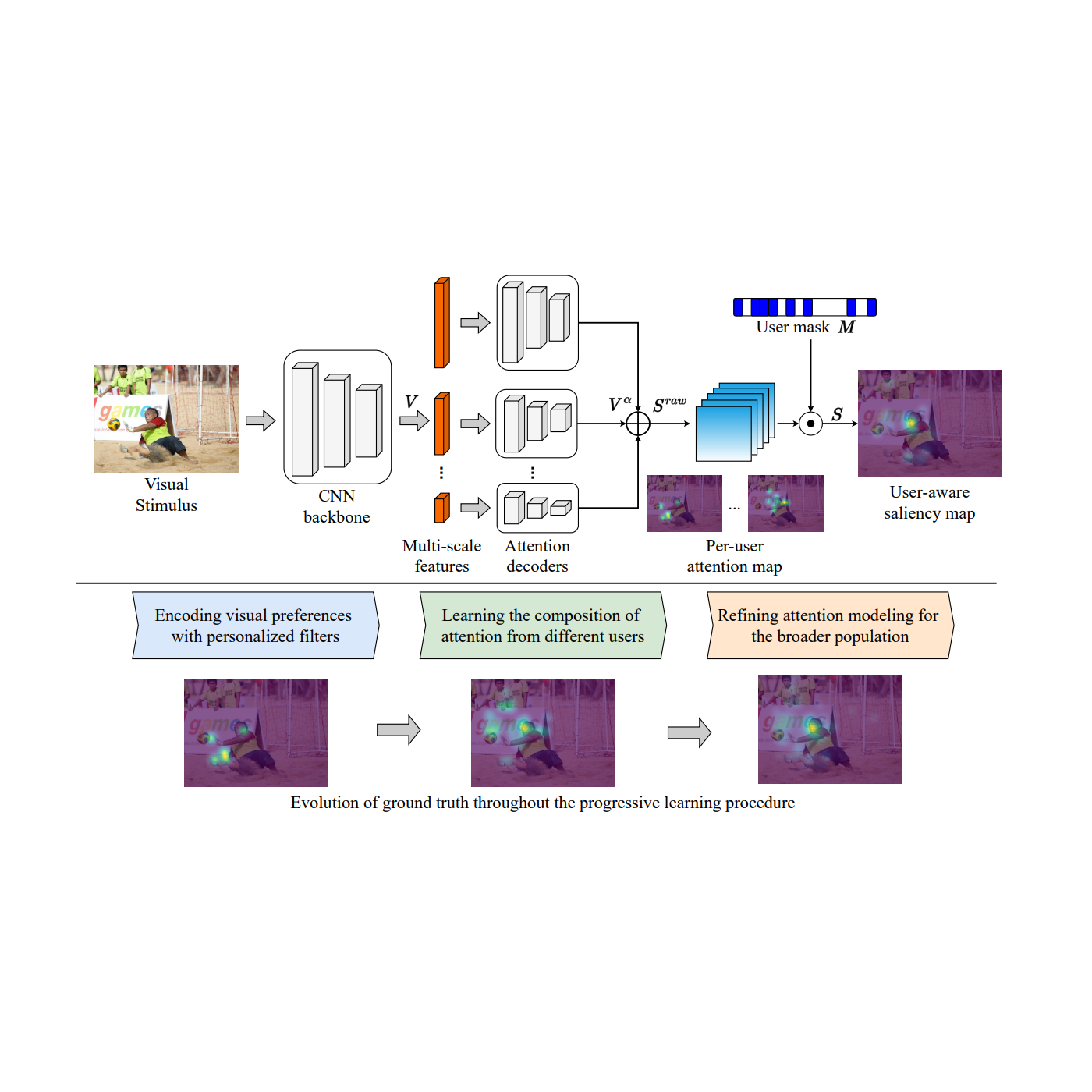
Few-shot on-device face stylization
An end-to-end pipeline
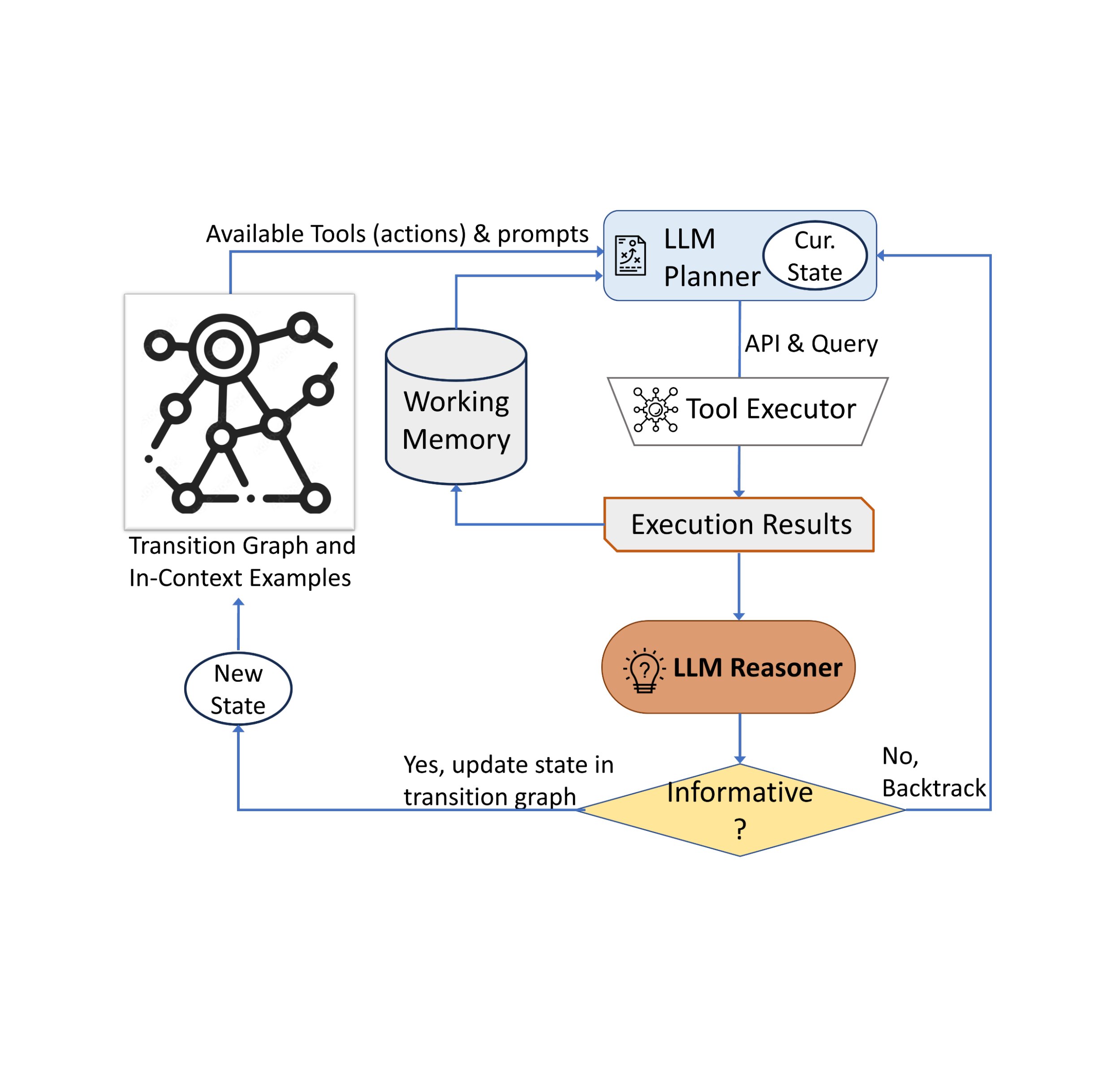
Our goal is to build a pipeline to support users to adapt the MediaPipe FaceStylizer to different styles by fine-tuning the model with a few examples. To enable such a face stylization pipeline, we built the pipeline with a GAN inversion encoder and efficient face generator model (see below). The encoder and generator pipeline can then be adapted to different styles via a few-shot learning process. The user first sends a single or a few similar samples of the style images to MediaPipe ModelMaker to fine-tune the model. The fine-tuning process freezes the encoder module and only fine-tunes the generator. The training process samples multiple latent codes close to the encoding output of the input style images as the input to the generator. The generator is then trained to reconstruct an image of a person’s face in the style of the input style image by optimizing a joint adversarial loss function that also accounts for style and content. With such a fine-tuning process, the MediaPipe FaceStylizer can adapt to the customized style, which approximates the user’s input. It can then be applied to stylize test images of real human faces.
Generator: BlazeStyleGAN
The StyleGAN model family has been widely adopted for face generation and various face editing tasks. To support efficient on-device face generation, we based the design of our generator on StyleGAN. This generator, which we call BlazeStyleGAN, is similar to StyleGAN in that it also contains a mapping network and synthesis network. However, since the synthesis network of StyleGAN is the major contributor to the model’s high computation complexity, we designed and employed a more efficient synthesis network. The improved efficiency and generation quality is achieved by:
- Reducing the latent feature dimension in the synthesis network to a quarter of the resolution of the counterpart layers in the teacher StyleGAN,
- Designing multiple auxiliary heads to transform the downscaled feature to the image domain to form a coarse-to-fine image pyramid to evaluate the perceptual quality of the reconstruction, and
- Skipping all but the final auxiliary head at inference time.
With the newly designed architecture, we train the BlazeStyleGAN model by distilling it from a teacher StyleGAN model. We use a multi-scale perceptual loss and adversarial loss in the distillation to transfer the high fidelity generation capability from the teacher model to the student BlazeStyleGAN model and also to mitigate the artifacts from the teacher model.
More details of the model architecture and training scheme can be found in our paper.
 |
| Visual comparison between face samples generated by StyleGAN and BlazeStyleGAN. The images on the first row are generated by the teacher StyleGAN. The images on the second row are generated by the student BlazeStyleGAN. The face generated by BlazeStyleGAN has similar visual quality to the image generated by the teacher model. Some results demonstrate the student BlazeStyleGAN suppresses the artifacts from the teacher model in the distillation. |
In the above figure, we demonstrate some sample results of our BlazeStyleGAN. By comparing with the face image generated by the teacher StyleGAN model (top row), the images generated by the student BlazeStyleGAN (bottom row) maintain high visual quality and further reduce artifacts produced by the teacher due to the loss function design in our distillation.
An encoder for efficient GAN inversion
To support image-to-image stylization, we also introduced an efficient GAN inversion as the encoder to map input images to the latent space of the generator. The encoder is defined by a MobileNet V2 backbone and trained with natural face images. The loss is defined as a combination of image perceptual quality loss, which measures the content difference, style similarity and embedding distance, as well as the L1 loss between the input images and reconstructed images.
On-device performance
We documented model complexities in terms of parameter numbers and computing FLOPs in the following table. Compared to the teacher StyleGAN (33.2M parameters), BlazeStyleGAN (generator) significantly reduces the model complexity, with only 2.01M parameters and 1.28G FLOPs for output resolution 256x256. Compared to StyleGAN-1024 (generating image size of 1024x1024), the BlazeStyleGAN-1024 can reduce both model size and computation complexity by 95% with no notable quality difference and can even suppress the artifacts from the teacher StyleGAN model.
| Model | Image Size | #Params (M) | FLOPs (G) | |||
| StyleGAN | 1024 | 33.17 | 74.3 | |||
| BlazeStyleGAN | 1024 | 2.07 | 4.70 | |||
| BlazeStyleGAN | 512 | 2.05 | 1.57 | |||
| BlazeStyleGAN | 256 | 2.01 | 1.28 | |||
| Encoder | 256 | 1.44 | 0.60 |
| Model complexity measured by parameter numbers and FLOPs. |
We benchmarked the inference time of the MediaPipe FaceStylizer on various high-end mobile devices and demonstrated the results in the table below. From the results, both BlazeStyleGAN-256 and BlazeStyleGAN-512 achieved real-time performance on all GPU devices. It can run in less than 10 ms runtime on a high-end phone’s GPU. BlazeStyleGAN-256 can also achieve real-time performance on the iOS devices’ CPU.
| Model | BlazeStyleGAN-256 (ms) | Encoder-256 (ms) | ||
| iPhone 11 | 12.14 | 11.48 | ||
| iPhone 12 | 11.99 | 12.25 | ||
| iPhone 13 Pro | 7.22 | 5.41 | ||
| Pixel 6 | 12.24 | 11.23 | ||
| Samsung Galaxy S10 | 17.01 | 12.70 | ||
| Samsung Galaxy S20 | 8.95 | 8.20 |
| Latency benchmark of the BlazeStyleGAN, face encoder, and the end-to-end pipeline on various mobile devices. |
Fairness evaluation
The model has been trained with a high diversity dataset of human faces. The model is expected to be fair to different human faces. The fairness evaluation demonstrates the model performs good and balanced in terms of human gender, skin-tone, and ages.
Face stylization visualization
Some face stylization results are demonstrated in the following figure. The images in the top row (in orange boxes) represent the style images used to fine-tune the model. The images in the left column (in the green boxes) are the natural face images used for testing. The 2x4 matrix of images represents the output of the MediaPipe FaceStylizer which is blending outputs between the natural faces on the left-most column and the corresponding face styles on the top row. The results demonstrate that our solution can achieve high-quality face stylization for several popular styles.
 |
| Sample results of our MediaPipe FaceStylizer. |
MediaPipe Solutions
The MediaPipe FaceStylizer is going to be released to public users in MediaPipe Solutions. Users can leverage MediaPipe Model Maker to train a customized face stylization model using their own style images. After training, the exported bundle of TFLite model files can be deployed to applications across platforms (Android, iOS, Web, Python, etc.) using the MediaPipe Tasks FaceStylizer API in just a few lines of code.
Acknowledgements
This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Omer Tov, Yang Zhao, Andrey Vakunov, Fei Deng, Ariel Ephrat, Inbar Mosseri, Lu Wang, Chuo-Ling Chang, Tingbo Hou, and Matthias Grundmann.