Visual question answering (VQA) is a machine learning task that requires a model to answer a question about an image or a set of images. Conventional VQA approaches need a large amount of labeled training data consisting of thousands of human-annotated question-answer pairs associated with images. In recent years, advances in large-scale pre-training have led to the development of VQA methods that perform well with fewer than fifty training examples (few-shot) and without any human-annotated VQA training data (zero-shot). However, there is still a significant performance gap between these methods and state-of-the-art fully supervised VQA methods, such as MaMMUT and VinVL. In particular, few-shot methods struggle with spatial reasoning, counting, and multi-hop reasoning. Furthermore, few-shot methods have generally been limited to answering questions about single images.
To improve accuracy on VQA examples that involve complex reasoning, in “Modular Visual Question Answering via Code Generation,” to appear at ACL 2023, we introduce CodeVQA, a framework that answers visual questions using program synthesis. Specifically, when given a question about an image or set of images, CodeVQA generates a Python program (code) with simple visual functions that allow it to process images, and executes this program to determine the answer. We demonstrate that in the few-shot setting, CodeVQA outperforms prior work by roughly 3% on the COVR dataset and 2% on the GQA dataset.
CodeVQA
The CodeVQA approach uses a code-writing large language model (LLM), such as PALM, to generate Python programs (code). We guide the LLM to correctly use visual functions by crafting a prompt consisting of a description of these functions and fewer than fifteen “in-context” examples of visual questions paired with the associated Python code for them. To select these examples, we compute embeddings for the input question and of all of the questions for which we have annotated programs (a randomly chosen set of fifty). Then, we select questions that have the highest similarity to the input and use them as in-context examples. Given the prompt and question that we want to answer, the LLM generates a Python program representing that question.
We instantiate the CodeVQA framework using three visual functions: (1) query, (2) get_pos, and (3) find_matching_image.
Query, which answers a question about a single image, is implemented using the few-shot Plug-and-Play VQA (PnP-VQA) method. PnP-VQA generates captions using BLIP — an image-captioning transformer pre-trained on millions of image-caption pairs — and feeds these into a LLM that outputs the answers to the question.Get_pos, which is an object localizer that takes a description of an object as input and returns its position in the image, is implemented using GradCAM. Specifically, the description and the image are passed through the BLIP joint text-image encoder, which predicts an image-text matching score. GradCAM takes the gradient of this score with respect to the image features to find the region most relevant to the text.Find_matching_image, which is used in multi-image questions to find the image that best matches a given input phrase, is implemented by using BLIP text and image encoders to compute a text embedding for the phrase and an image embedding for each image. Then the dot products of the text embedding with each image embedding represent the relevance of each image to the phrase, and we pick the image that maximizes this relevance.
The three functions can be implemented using models that require very little annotation (e.g., text and image-text pairs collected from the web and a small number of VQA examples). Furthermore, the CodeVQA framework can be easily generalized beyond these functions to others that a user might implement (e.g., object detection, image segmentation, or knowledge base retrieval).
 |
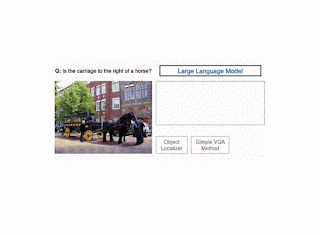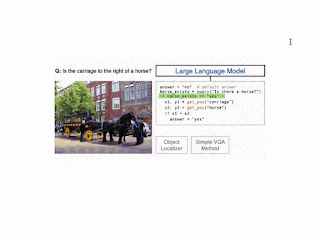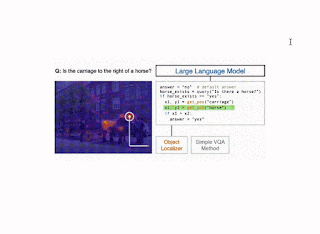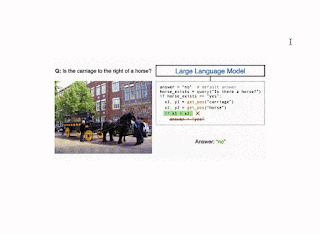
Illustration of the CodeVQA method. First, a large language model generates a Python program (code), which invokes visual functions that represent the question. In this example, a simple VQA method (query) is used to answer one part of the question, and an object localizer (get_pos) is used to find the positions of the objects mentioned. Then the program produces an answer to the original question by combining the outputs of these functions. |
Results
The CodeVQA framework correctly generates and executes Python programs not only for single-image questions, but also for multi-image questions. For example, if given two images, each showing two pandas, a question one might ask is, “Is it true that there are four pandas?” In this case, the LLM converts the counting question about the pair of images into a program in which an object count is obtained for each image (using the query function). Then the counts for both images are added to compute a total count, which is then compared to the number in the original question to yield a yes or no answer.
 |
We evaluate CodeVQA on three visual reasoning datasets: GQA (single-image), COVR (multi-image), and NLVR2 (multi-image). For GQA, we provide 12 in-context examples to each method, and for COVR and NLVR2, we provide six in-context examples to each method. The table below shows that CodeVQA improves consistently over the baseline few-shot VQA method on all three datasets.
| Method | GQA | COVR | NLVR2 | ||||||||
| Few-shot PnP-VQA | 46.56 | 49.06 | 63.37 | ||||||||
| CodeVQA | 49.03 | 54.11 | 64.04 |
| Results on the GQA, COVR, and NLVR2 datasets, showing that CodeVQA consistently improves over few-shot PnP-VQA. The metric is exact-match accuracy, i.e., the percentage of examples in which the predicted answer exactly matches the ground-truth answer. |
We find that in GQA, CodeVQA’s accuracy is roughly 30% higher than the baseline on spatial reasoning questions, 4% higher on “and” questions, and 3% higher on “or” questions. The third category includes multi-hop questions such as “Are there salt shakers or skateboards in the picture?”, for which the generated program is shown below.
img = open_image("Image13.jpg")
salt_shakers_exist = query(img, "Are there any salt shakers?")
skateboards_exist = query(img, "Are there any skateboards?")
if salt_shakers_exist == "yes" or skateboards_exist == "yes":
answer = "yes"
else:
answer = "no"
In COVR, we find that CodeVQA’s gain over the baseline is higher when the number of input images is larger, as shown in the table below. This trend indicates that breaking the problem down into single-image questions is beneficial.
| Number of images | |||||||||||
| Method | 1 |
2 |
3 |
4 |
5 |
||||||
| Few-shot PnP-VQA | 91.7 | 51.5 | 48.3 | 47.0 | 46.9 | ||||||
| CodeVQA | 75.0 | 53.3 | 48.7 | 53.2 | 53.4 | ||||||
Conclusion
We present CodeVQA, a framework for few-shot visual question answering that relies on code generation to perform multi-step visual reasoning. Exciting directions for future work include expanding the set of modules used and creating a similar framework for visual tasks beyond VQA. We note that care should be taken when considering whether to deploy a system such as CodeVQA, since vision-language models like the ones used in our visual functions have been shown to exhibit social biases. At the same time, compared to monolithic models, CodeVQA offers additional interpretability (through the Python program) and controllability (by modifying the prompts or visual functions), which are useful in production systems.
Acknowledgements
This research was a collaboration between UC Berkeley’s Artificial Intelligence Research lab (BAIR) and Google Research, and was conducted by Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, and Dan Klein.