The ability to detect objects in the visual world is crucial for computer vision and machine intelligence, enabling applications like adaptive autonomous agents and versatile shopping systems. However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. To overcome this, the open-vocabulary detection task (OVD) has emerged, utilizing image-text pairs for training and incorporating new category names at test time by associating them with the image content. By treating categories as text embeddings, open-vocabulary detectors can predict a wide range of unseen objects. Various techniques such as image-text pre-training, knowledge distillation, pseudo labeling, and frozen models, often employing convolutional neural network (CNN) backbones, have been proposed. With the growing popularity of vision transformers (ViTs), it is important to explore their potential for building proficient open-vocabulary detectors.
The existing approaches assume the availability of pre-trained vision-language models (VLMs) and focus on fine-tuning or distillation from these models to address the disparity between image-level pre-training and object-level fine-tuning. However, as VLMs are primarily designed for image-level tasks like classification and retrieval, they do not fully leverage the concept of objects or regions during the pre-training phase. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
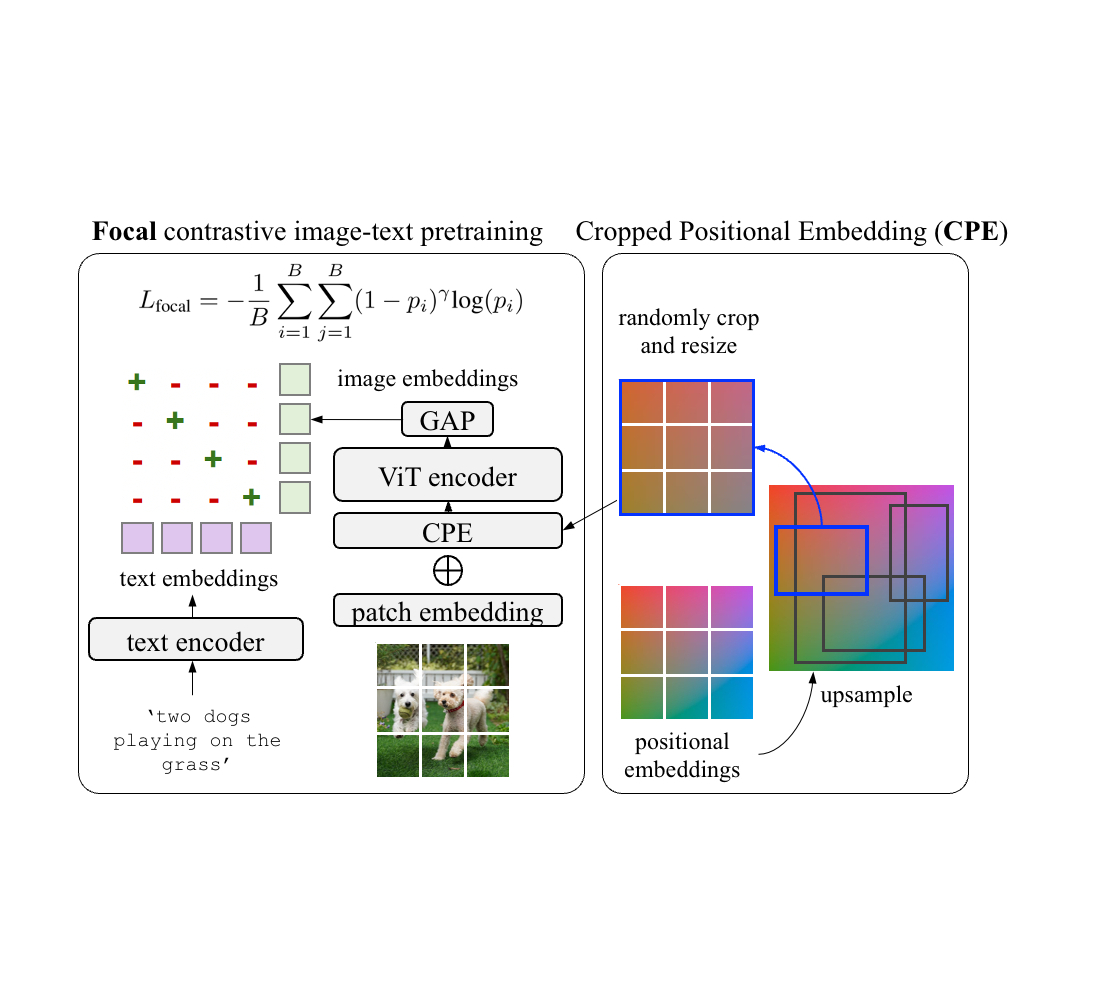
In “RO-ViT: Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers”, presented at CVPR 2023, we introduce a simple method to pre-train vision transformers in a region-aware manner to improve open-vocabulary detection. In vision transformers, positional embeddings are added to image patches to encode information about the spatial position of each patch within the image. Standard pre-training typically uses full-image positional embeddings, which does not generalize well to detection tasks. Thus, we propose a new positional embedding scheme, called “cropped positional embedding”, that better aligns with the use of region crops in detection fine-tuning. In addition, we replace the softmax cross entropy loss with focal loss in contrastive image-text learning, allowing us to learn from more challenging and informative examples. Finally, we leverage recent advances in novel object proposals to enhance open-vocabulary detection fine-tuning, which is motivated by the observation that existing methods often miss novel objects during the proposal stage due to overfitting to foreground categories. We are also releasing the code here.
Region-aware image-text pre-training
Existing VLMs are trained to match an image as a whole to a text description. However, we observe there is a mismatch between the way the positional embeddings are used in the existing contrastive pre-training approaches and open-vocabulary detection. The positional embeddings are important to transformers as they provide the information of where each element in the set comes from. This information is often useful for downstream recognition and localization tasks. Pre-training approaches typically apply full-image positional embeddings during training, and use the same positional embeddings for downstream tasks, e.g., zero-shot recognition. However, the recognition occurs at region-level for open-vocabulary detection fine-tuning, which requires the full-image positional embeddings to generalize to regions that they never see during the pre-training.
To address this, we propose cropped positional embeddings (CPE). With CPE, we upsample positional embeddings from the image size typical for pre-training, e.g., 224x224 pixels, to that typical for detection tasks, e.g., 1024x1024 pixels. Then we randomly crop and resize a region, and use it as the image-level positional embeddings during pre-training. The position, scale, and aspect ratio of the crop is randomly sampled. Intuitively, this causes the model to view an image not as a full image in itself, but as a region crop from some larger unknown image. This better matches the downstream use case of detection where recognition occurs at region- rather than image-level.
 |
| For the pre-training, we propose cropped positional embedding (CPE) which randomly crops and resizes a region of positional embeddings instead of using the whole-image positional embedding (PE). In addition, we use focal loss instead of the common softmax cross entropy loss for contrastive learning. |
We also find it beneficial to learn from hard examples with a focal loss. Focal loss enables finer control over how hard examples are weighted than what the softmax cross entropy loss can provide. We adopt the focal loss and replace it with the softmax cross entropy loss in both image-to-text and text-to-image losses. Both CPE and focal loss introduce no extra parameters and minimal computation costs.
Open-vocabulary detector fine-tuning
An open-vocabulary detector is trained with the detection labels of ‘base’ categories, but needs to detect the union of ‘base’ and ‘novel’ (unlabeled) categories at test time. Despite the backbone features pre-trained from the vast open-vocabulary data, the added detector layers (neck and heads) are newly trained with the downstream detection dataset. Existing approaches often miss novel/unlabeled objects in the object proposal stage because the proposals tend to classify them as background. To remedy this, we leverage recent advances in a novel object proposal method and adopt the localization quality-based objectness (i.e., centerness score) instead of object-or-not binary classification score, which is combined with the detection score. During training, we compute the detection scores for each detected region as the cosine similarity between the region’s embedding (computed via RoI-Align operation) and the text embeddings of the base categories. At test time, we append the text embeddings of novel categories, and the detection score is now computed with the union of the base and novel categories.
 |
| The pre-trained ViT backbone is transferred to the downstream open-vocabulary detection by replacing the global average pooling with detector heads. The RoI-Align embeddings are matched with the cached category embeddings to obtain the VLM score, which is combined with the detection score into the open-vocabulary detection score. |
Results
We evaluate RO-ViT on the LVIS open-vocabulary detection benchmark. At the system-level, our best model achieves 33.6 box average precision on rare categories (APr) and 32.1 mask APr, which outperforms the best existing ViT-based approach OWL-ViT by 8.0 APr and the best CNN-based approach ViLD-Ens by 5.8 mask APr. It also exceeds the performance of many other approaches based on knowledge distillation, pre-training, or joint training with weak supervision.
 |
| RO-ViT outperforms both the state-of-the-art (SOTA) ViT-based and CNN-based methods on LVIS open-vocabulary detection benchmark. We show mask AP on rare categories (APr) , except for SOTA ViT-based (OwL-ViT) where we show box AP. |
Apart from evaluating region-level representation through open-vocabulary detection, we evaluate the image-level representation of RO-ViT in image-text retrieval through the MS-COCO and Flickr30K benchmarks. Our model with 303M ViT outperforms the state-of-the-art CoCa model with 1B ViT on MS COCO, and is on par on Flickr30K. This shows that our pre-training method not only improves the region-level representation but also the global image-level representation for retrieval.
 |
| We show zero-shot image-text retrieval on MS COCO and Flickr30K benchmarks, and compare with dual-encoder methods. We report recall@1 (top-1 recall) on image-to-text (I2T) and text-to-image (T2I) retrieval tasks. RO-ViT outperforms the state-of-the-art CoCa with the same backbone. |
 |
| RO-ViT open-vocabulary detection on LVIS. We only show the novel categories for clarity. RO-ViT detects many novel categories that it has never seen during detection training: “fishbowl”, “sombrero”, “persimmon”, “gargoyle”. |
Visualization of positional embeddings
We visualize and compare the learned positional embeddings of RO-ViT with the baseline. Each tile is the cosine similarity between positional embeddings of one patch and all other patches. For example, the tile in the top-left corner (marked in red) visualizes the similarity between the positional embedding of the location (row=1, column=1) and those positional embeddings of all other locations in 2D. The brightness of the patch indicates how close the learned positional embeddings of different locations are. RO-ViT forms more distinct clusters at different patch locations showing symmetrical global patterns around the center patch.
 |
| Each tile shows the cosine similarity between the positional embedding of the patch (at the indicated row-column position) and the positional embeddings of all other patches. ViT-B/16 backbone is used. |
Conclusion
We present RO-ViT, a contrastive image-text pre-training framework to bridge the gap between image-level pre-training and open-vocabulary detection fine-tuning. Our methods are simple, scalable, and easy to apply to any contrastive backbones with minimal computation overhead and no increase in parameters. RO-ViT achieves the state-of-the-art on LVIS open-vocabulary detection benchmark and on the image-text retrieval benchmarks, showing the learned representation is not only beneficial at region-level but also highly effective at the image-level. We hope this study can help the research on open-vocabulary detection from the perspective of image-text pre-training which can benefit both region-level and image-level tasks.
Acknowledgements
Dahun Kim, Anelia Angelova, and Weicheng Kuo conducted this work and are now at Google DeepMind. We would like to thank our colleagues at Google Research for their advice and helpful discussions.